КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Технико-экономическая эффективность (Technical-economical Efficiency) вычислительных систем
|
|
|
|
Самоконтроль и самодиагностика (Self-testing and Self-diagnostics) вычислительных систем
Организация надёжного и живучего функционирования вычислительных систем связана с контролем правильности их работы и с локализацией неисправностей в них. В системах–коллективах вычислителей может быть применён нетрадиционный подход к контролю и диагностике:
- в качестве контрольно-диагностического ядра ВС могут быть использованы любые исправные вычислители и в пределе ядро любого произвольно выбранного вычислителя,
- выбор ядра системы и определение её исправности могут быть произведены автоматически (с помощью средств ВС).
Предлагаемый подход позволяет говорить о самоконтроле и самодиагностике ВС. Заключение об исправности или неисправности отдельных вычислителей системы принимается коллективно всеми вычислителями на основе сопоставления их индивидуальных заключений об исправности соседних с ними вычислителей.
Конструктивная однородность позволяет резко сократить сроки разработки и изготовления систем, приводит к высокой технологичности производства, упрощает и статическую, и динамическую реконфигурации ВС, облегчает их техническую эксплуатацию. Она существенно упрощает процесс организации взаимодействий между вычислителями ВС и облегчает создание программного обеспечения. Полнота воплощения трёх основных принципов модели коллектива вычислителей позволяет заметно ослабить зависимость между ростом производительности ВС и увеличением трудоёмкости их проектирования и изготовления, а также создания системного программного обеспечения. Они открывают возможность построения высокопроизводительных экономически приемлемых вычислительных систем при существующей физико-технологической базе. Более того, возможность неограниченно наращивать производительность позволяет применить для построения ВС микроэлектронные элементы с быстродействием, далеким от предельного, и следовательно, обладающие более высокой надежностью и меньшим энергопотреблением. В свою очередь, последнее приводит к снижению расходов на установку искусственного климата и содержание эксплуатационного персонала ВС.
|
|
|
Параллельная обработка как основа высокопроизводительных вычислений. Уровни организации параллелизма: уровень заданий, программ и команд
Имеются следующие способы повышения производительности ЭВМ при обработке информации:
а) совершенствование алгоритмов решения задач;
б) оптимизация программ (создание эффективных систем программирования);
в) повышение быстродействия элементной базы ЭВМ;
г) модификация структуры процессора (улучшение алгоритмов выполнения машинных операций);
д) конвейерно-параллельная обработка информации.
Попробуем разобраться, какой из факторов является решающим в достижении современных фантастических показателей производительности. Для разрешения этого вопроса обратимся к историческим фактам. Известно, что на компьютере EDSAC (1949 г.), имевшего время такта 2мкс, можно было выполнить 2*n арифметических операций за 18*n мс, то есть в среднем 100 арифметических операций в секунду. Сравним с современным суперкомпьютером CRAY C90: время такта приблизительно 4нс, а пиковая производительность около 1 миллиарда арифметических операций в секунду.
| Компьютер | Время такта(с) | Скорость (оп/с) |
| EDSAC (1949 г.) | 2*10-6 с | 102 оп/с |
| CRAY C90 (1991 г.) | 4*10-9 с | 109 оп/с |
Производительность компьютеров за этот период выросла в приблизительно в десять миллионов раз. Уменьшение времени такта является прямым способом увеличением производительности, однако эта составляющая (с 2мкс до 4нс) в общем объеме дает вклад лишь в 500 раз. Откуда же взялось остальное? Ответ очевиден - использование новых решений в архитектуре компьютеров, среди которых основное место занимает принцип параллельной обработки данных.
|
|
|
Данный принцип, воплощая идею одновременного выполнения нескольких действий, имеет две разновидности: конвейерность и собственно параллельность.
Параллельная обработка. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени.
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых.
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций. Предположим, что в операции можно выделить пять микроопераций, каждая из которых выполняется за одну единицу времени. Если есть одно неделимое последовательное устройство, то 100 пар аргументов оно обработает за 500 единиц. Если каждую микрооперацию выделить в отдельный этап (или иначе говорят - ступень) конвейерного устройства, то на пятой единице времени на разной стадии обработки такого устройства будут находится первые пять пар аргументов, а весь набор из ста пар будет обработан за 5+99=104 единицы времени - ускорение по сравнению с последовательным устройством почти в пять раз (по числу ступеней конвейера).
|
|
|
Казалось бы конвейерную обработку можно с успехом заменить обычным параллелизмом, для чего продублировать основное устройство столько раз, сколько ступеней конвейера предполагается выделить. В самом деле, пять устройств предыдущего примера обработают 100 пар аргументов за 100 единиц времени, что быстрее времени работы конвейерного устройства! В чем же дело? Ответ прост, увеличив в пять раз число устройств, мы значительно увеличиваем как объем аппаратуры, так и ее стоимость.
Параллелизм – основа высокопроизводительной работы всех подсистем вычислительных машин. Организация памяти любого уровня иерархии, организация системного ввода/вывода, организация мультиплексирования шин и т.д. базируются на принципах параллельной обработки запросов. Современные операционные системы являются многозадачными и многопользовательскими, имитируя параллельное исполнение программ посредством механизма прерываний.
Развитие процессоростроения также ориентировано на распараллеливание операций, т.е. на выполнение процессором большего числа операций за такт. Ключевыми ступенями развития архитектуры процессоров стали гиперконвейеризация, суперскалярность, неупорядоченная модель обработки, векторное процессирование (технология SIMD), архитектура VLIW. Все ступени были ориентированы на повышение степени параллелизма исполнения.
В настоящее время мощные сервера представляют собой мультипроцессорные системы, а в процессорах активно используется параллелизм уровня потоков.
Распараллеливание операций – перспективный путь повышения производительности вычислений. Согласно закону Мура число транзисторов экспоненциально растёт, что позволяет в настоящее время включать в состав CPU большое количество исполнительных устройств самого разного назначения. Прошли времена, когда функционирование ЭВМ подчинялось принципам фон Неймана.
|
|
|
В 70-е годы стал активно применяться принцип конвейеризации вычислений. Сейчас конвейер Intel Pentium 4 состоит из 20 ступеней. Такое распараллеливание на микроуровне – первый шаг на пути эволюции процессоров. На принципах конвейеризации базируются и внешние устройства. Например, динамическая память (организация чередования банков) или внешняя память (организация RAID).
Но число транзисторов на чипе росло. Использование микроуровневого параллелизма позволяло лишь уменьшать CPI (Cycles Per Instruction - число тактов, необходимых для выполнения одной инструкции), так как миллионы транзисторов при выполнении одиночной инструкции простаивали. CPI = общее количество тактов / число выполненных команд.
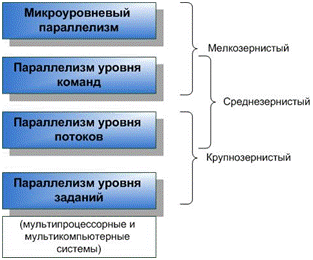
Уровни параллелизма
На следующем этапе эволюции в 80-е годы стали использовать параллелизм уровня команд посредством размещения в CPU сразу нескольких конвейеров. Такие суперскалярные CPU позволяли достигать CPI<1. Параллелизм уровня инструкций (ILP) породил неупорядоченную модель обработки, динамическое планирование, станции резервации и т.д. От CPI перешли к IPC (InstructionsPerClock). Но ILP ограничен алгоритмом исполняемой программы. Кроме того, при увеличении количества ALU сложность оборудования экспоненциально растёт, увеличивается количество горизонтальных и вертикальных потерь в слотах выдачи. Параллелизм уровня инструкций исчерпал свои резервы, а тенденции Мура позволили процессоростроителям осваивать более высокие уровни параллелизма. Современные методики повышения ILP основаны на использовании процессоров класса SIMD. Это векторное процессирование, матричные процессоры, архитектура VLIW.
Параллелизм уровня потоков и уровня заданий применяется в процессорах класса MIMD.
Параллелизм всех уровней свойственен не только процессорам общего назначения (GPP), но и процессорам специального назначения (ASP (Application-Specific Processor), DSP (Digital Signal Processor)).
Иногда классифицируют параллелизм по степени гранулярности как отношение объёма вычислений к объёму коммуникаций. Различают мелкозернистый, среднезернистый и крупнозернистый параллелизм. Мелкозернистый параллелизм обеспечивает сам CPU, но компилятор может и должен ему помочь для обеспечения большего IPC. Среднезернистый параллелизм – прерогатива программиста, которому необходимо разрабатывать многопоточные алгоритмы. Здесь роль компилятора заключается в выборе оптимальной последовательности инструкций (с большим IPC) посредством различных методик (например, символическое разворачивание циклов). Крупнозернистый параллелизм обеспечивает ОС.
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 589; Нарушение авторских прав?; Мы поможем в написании вашей работы!