КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Режим обучения устройства
|
|
|
|
УСТРОЙСТВА РАСПОЗНАВАНИЯ РЕЧИ (УРВ)
Рис. 1.
Cn-амплитуда гармоники;
N=0
КЛП - анализ речи.
Выделение формантных параметров речи.
Далее кратко рассмотрим их суть.
1.1. Спектральное описание речевого сигнала
Речевой сигнал, полученный с микрофона и усиленный до заданного уровня, может быть разложен на гармонические составляющие или представлен как интеграл бесконечного числа гармонических составляющих:
∞
F (t) = Σ Cn Сos (n ω t) (1)
где: n- номер гармоники;
ω -угловая частота
(напомним, что ω = 360f, где f – обычная
частота).
Спектром сигнала F(t) называют совокупность простых гармонических колебаний, на которые может быть разложено сложное колебательное движение. По сути, выражение (1) является аналитическим спектром функции F(t). При этом гармонические колебания имеют дискретный спектр (рис. 1).
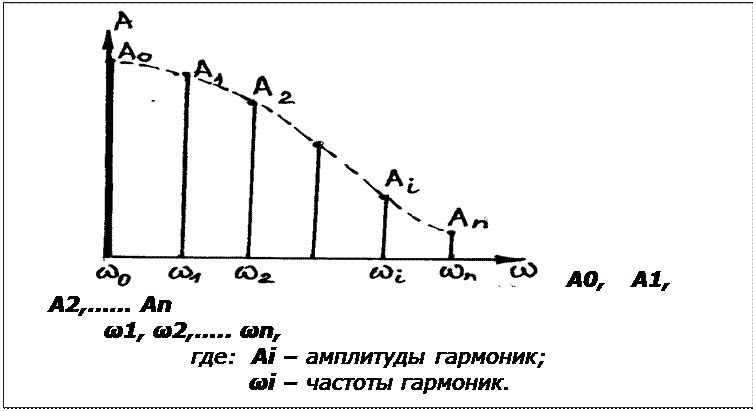
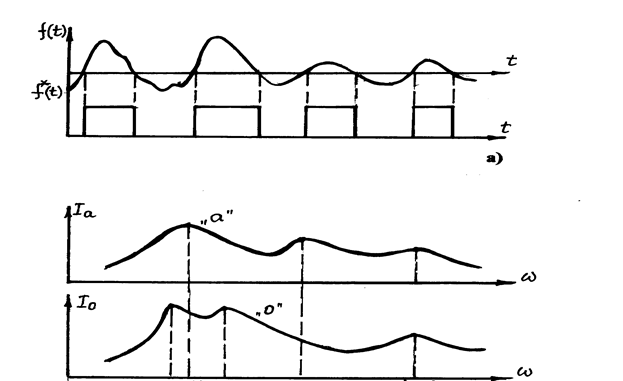
Рис. 2. б)
Основным способом разложения сигнала в спектр является преобразование Фурье с последующей полосовой фильтрацией.
Речевой сигнал обычно анализируется в полосе частот от 50 Гц до 12 кГц или меньше (300 – 3400 Гц в телефонном канале). Число спектральных полос не поддаётся точному расчёту и подбирается экспериментально (от 5 до 16, а иногда значительно больше). Для определения амплитуд спектральных составляющих используется детектирование.
В результате спектрального разложения речевого сигнала (фонем) получают «спектральный портрет» звукового образа речи:
А0, А1, А2,…… Аn
ω1, ω2,….. ωn
где: Ai – амплитуды гармоник;
ωi – частоты гармоник.
1.2. Клиппирование речевого сигнала
Клиппирование является простейшим методом анализа речевого сигнала и заключается в предельном усилении сигнала с последующим ограничением по амплитуде (рис. 2, а).
|
|
|
Преобразование сигнала f(t) в цифровую форму позволяет записать его в память ЭВМ и обработать с целью получения «цифрового портрета речевого сигнала».
Клиппированная речь обладает удовлетворительной разборчивостью, то есть несёт в себе ещё достаточно информации для различения слов и понимания фраз, несмотря на большое упрощение формы сигнала.
Разборчивость речи значительно возрастает, если сигнал смешивают с его производной. Однако при этом более чем вдвое возрастает сложность описания речи.
Анализ клиппированного сигнала сводится к подсчёту числа переходов через нулевой уровень в единицу времени и учёту распределений интервалов времени между переходами.
1.3. Выделение формантных параметров речи
Если произнести в микрофон некоторую фонему и, затем, усилить сигнал с микрофона, построить кривую I=f(ω), где I -интенсивность (для простоты – амплитуда сигнала), ω угловая частота сигнала, то можно получить график функции, которая в теории анализа речевых сигналов называют формантной характеристикой (рис. 2, б).
Эта характеристика представляет собой графическое изображение спектра речевого сигнала, полученного при произнесении фонем букв «а» и «о». Приведённые на рисунке характеристики представляют собой частотный портрет фонем и имеют вид кривых с тремя чётко выраженными горбами на частотах ω1, ω2 и ω3 ( некоторыефонемы имеют до 6 таких горбов и, соответственно, частот ). Эти частоты называют формантными частотами. В теории формантного анализа сигналов показано, что для хорошего качества распознавания фонем и синтеза речевого
сигнала достаточно задать параметры нескольких старших (первых трёх) формант основного тона и источника шумового сигнала.
|
|
|
Формантный анализ речи является развитием спектрального анализа применительно к специфике образования речи. Данный вид анализа является весьма сложным, поскольку необходимо с высокой надёжностью различать тональные и глухие участки речи, вырабатывая признак тон/шум, определять параметры шума и параметры речевого тракта. Параметрами речевого тракта является информация о резонансах: определяются формантные частоты (от 2 до 6) и их полосы.
1.4. КЛП - анализ речи.
Этот метод основан на вычислении коэффициентов линейного предсказания (КЛП). Метод позволяет описать речевой сигнал наиболее точно и в то же время компактно. В ходе обработки текущие отсчёты речевого сигнала, взятые с интервалами квантования 50 – 120 мкс, сравниваются с линейными комбинациями ограниченного ряда (от 4 до 12) предыдущих отсчётов. Эти линейные комбинации называют предсказанными отсчётами. Коэффициенты в линейных комбинациях определяются (на быстрых ЭВМ, ON- LINE, статистическими методами) на участках речи длительностью 10 – 20 мс с таким расчётом, чтобы расхождение между предсказанными и текущими значениями были минимальными. Массивы этих коэффициентов и являются результатом КЛП - анализа.
2.1. Разновидности устройств речевого ввода и модель устройства речевого ввода.
Задача распознавания речи (речевого ввода) существенно сложнее задачи синтеза речи (речевого вывода) и к настоящему времени решается лишь при ряде ограничений:
· Ограничен объём словаря для вводимой информации (от 50 до 300 слов; при увеличении словаря падает достоверность, растёт время распознавания).
· Устройства ввода распознают изолированно (раздельно) произносимые слова. Задача распознавания слитной речи пока окончательно не решена.
· Проявляется зависимость достоверности распознавания от индивидуальных свойств речи конкретного оператора, вследствие чего требуется настройка устройства на данного диктора и его словарь. Достоверность распознавания при соблюдении некоторых условий может достигать 92 – 99 %.
В связи с перечисленными выше ограничениями устройства речевого ввода (УРВ) можно классифицировать следующим образом:
1. Устройства для распознавания изолированной или слитной речи;
|
|
|
2. Устройства с ограниченным словарём (словником);
3. Устройства адаптированные на конкретного диктора.
Большинство реально работающих устройств используют сравнительно несложный общий алгоритм распознавания речи, суть которого кратко заключается в следующем.
Предварительно, на этапе обучения устройства, формируется и записывается в память словарь эталонов – массив слов, которые устройство должно распознавать с заданной достоверностью. Затем на этапе распознавания произнесённое диктором слово (реализация) сравнивается последовательно со всеми эталонами и вырабатывается решение о сходстве (несходстве) реализации и эталона.
Сравнительная простота общего алгоритма распознавания на практике обманчива, так как к техническим параметрам отдельных узлов УРВ предъявляются очень жёсткие требования. По этим причинам устройства распознавания речи развиты в настоящее время слабей, чем синтезаторы речи.
На рис. 3 приведена модель устройства распознавания речи, с использованием которой (и её аналогов) были разработаны реальные устройства (в том числе такие серийные отечественные устройства как ИКАР, УРВ РМ, ЛЕКСИНАР, на некоторых остановимся в разделе «Практическая реализация»).
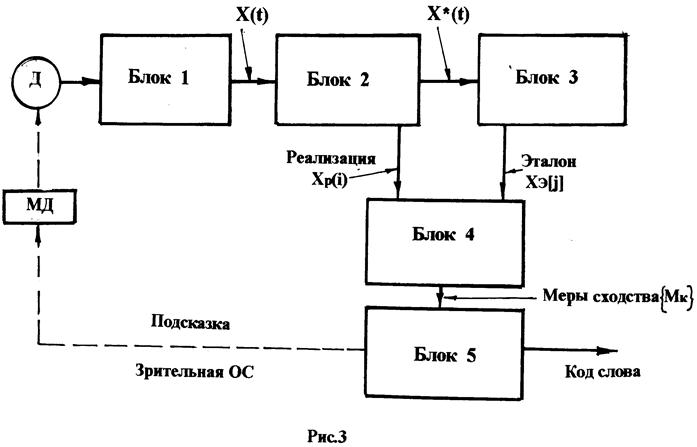
Модель УРВ состоит из нескольких блоков, каждый из которых реализует часть общего алгоритма распознавания речевого сигнала. Работа модели разбивается на два самостоятельных этапа (режима) работы:
а). Режим обучения устройства, на котором происходит формирование словаря (словника).
б). Режим распознавания – основной режим работы УРВ.
Модель основана на распознавания раздельно произносимых слов, так как в этом случае временные интервалы между словами чётко различимы и не усложняют алгоритм.
В составе модели имеется мини-дисплей (МД), который информирует диктора о том, какие действия диктор должен
предпринимать, если в работе УРВ имеются какие-либо неполадки или отклонения от алгоритма или о том, что обучение устройства или распознавание слов происходит нормально.
|
|
|
Рассмотрим принцип работы модели УРВ.
(Режим 1):
Диктор (Д) последовательно произносит в микрофон отдельные слова. Речевой сигнал с микрофона усиливается усилителем и в нормированном виде поступает на дальнейшую обработку – блок 1. Далее в блоке 2 происходит преобразование аналогового речевого сигнала X(t) в цифровую форму – формируется цифровое информационное описание речевого сигнала X*(t). Алгоритм формирования цифрового описания зависит от того, какой метод положен в основу формирования признаковых параметров. Будем считать, что речевой сигнал подвергается спектральному анализу. В блоке 3 происходит формирование словаря УРВ и запись словаря в память устройства. Формирование словаря происходит последовательно для всех слов, которые должны входить в словарь. На этом заканчивается режим 1 – режим обучения УРВ.
РЕЖИМ РАСПОЗНАВАНИЯ (режим 2): Этот режим является основным, то есть это собственно режим распознавания слов. Начальная часть режима (блоки 1 и 2) реализуются аналогично.
Сформированный цифровой образ, произнесённого диктором слова – реализация Xp(i) – поступает в блок 4, в котором происходит сравнение реализации с эталонами Xэ(j). В этом же блоке происходит нормализация темпа речи методом деформации оси времени с тем, чтобы длительность звучания реализации соответствовала длительности звучания эталона. Результатом работы блока 4 являетсямассив данных – так называемых мер сходства (или несходства) – {Mk}, каждая из которых характеризует близость произнесённого слова к эталонам.
В блоке 5 происходит анализ мер сходства и вырабатывается решение, определяющее результат распознавания.
Возможны 5 вариантов решения (подсказок диктору):
а). Входная реализация тождественна (близка) одному из эталонов заданного словаря.
б). Реализация не принадлежит данному словарю.
в). Реализация равноудалена от нескольких эталонов словаря.
г). Реализация произнесена тихо.
д). Реализация не принадлежит к классу речевых сигналов (помеха).
2.2 Обобщённая структура устройства распознавания речи.
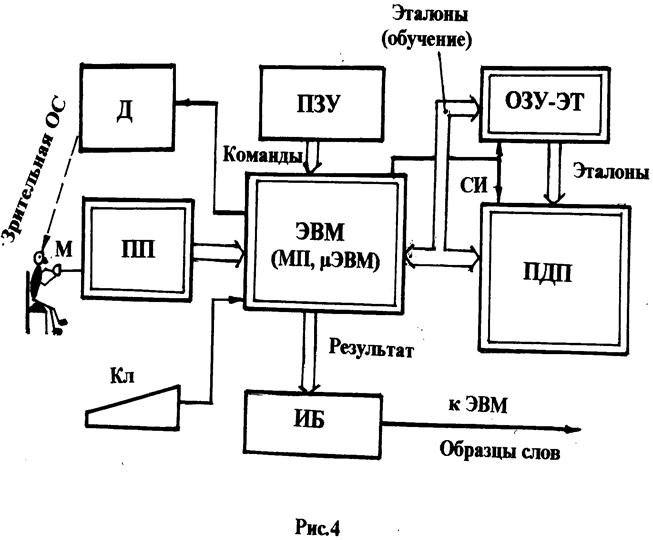
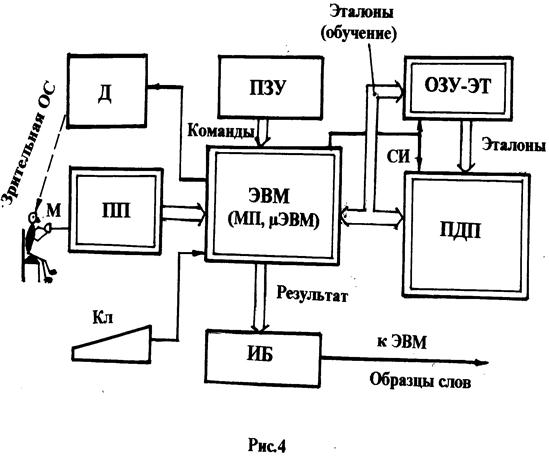
Обобщённая структура устройства распознавания речи (УРВ) приведена на рис. 4. В приведённой структуре УРВ используется метод спектрального представления речевого сигнала.
На структурной схеме использованы следующие обозначения:
Д – дисплей (мини дисплей) устройство, замыкающее цепь обратной связи, позволяющее информировать диктора о состоянии устройства (режим подсказок диктору);
ПЗУ – постоянное запоминающее устройство, хранящее микропрограммы управления ЭВМ нижнего уровня (МП, микро ЭВМ);
ОЗУ-ЭТ – оперативное запоминающее устройство эталонов, хранящее эталоны;
ПП – предпроцессор, аналого-цифровое вычислительное устройство, осуществляющее спектральный анализ речевого сигнала с последующим преобразованием данных в цифровую форму;
ЭВМ (МП, μЭВМ) – ЭВМ нижнего уровня, управляющая потоками информации в УРВ;
ПДП – процессор динамического программирования, осуществляющий вычисление мер сходства между реализациями и эталонами;
Кл – клавиатура;
ИБ – интерфейсный блок (интерфейс), связывающий УРВ с ЭВМ верхнего уровня.
Данная структура функционирует в полном соответствии с моделью устройства речевого ввода, рассмотренного выше.
Определённую специфику в данную структуру вносит предпроцессор, который реализует начальную стадию работы устройства как в режиме обучения (создания словаря), так и в режиме распознавания. Структура предпроцессора во многом определяет работу УРВ в целом.
2.3 Структура и функции предпроцессора.
Как уже отмечалось выше, предпроцессор, являясь специализированным вычислительным устройством аналого-цифрового типа, выполняет первичную обработку и преобразование речевого сигнала.
В основу алгоритма работы предпроцессора могут быть положены различные методы образования признаковых параметров, характеризующих аналоговый речевой сигнал. В зависимости от выбранного метода изменяется не только структура предпроцессора, но и в той или иной мере и структура всего УРВ. В приведённой на рис. 5 структурной схеме предпроцессора используется метод разложения речевого сигнала на его спектральные составляющие с последующим преобразованием составляющих спектра в цифровую форму.
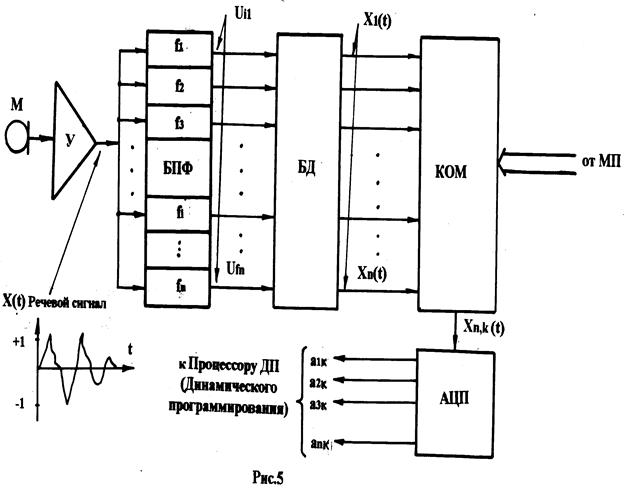
В структуре предпроцессора можно выделить несколько основных блоков (второстепенные блоки опущены, так как они играют вспомогательную роль). На структуре предпроцессора приняты следующие обозначения:
М – микрофон диктора;
У – усилитель, осуществляющий усиление сигнала, поступающего с микрофона и нормирующего амплитуду (размах) речевого сигнала до необходимого уровня, принятого в данном устройстве (ПП);
БПФ – блок полосовых фильтров «вырезающих» из широкополосного речевого сигнала ряд гармонических сигналов с частотами f1, f2, f3, …,fn.
В блоке полосовых фильтров (БПФ) количество элементов выбирается в зависимости от заданного диапазона частот речевого сигнала и составляет для разных вариантов УРВ величину n =5 или 12 или 16, а иногда значительно больше. Частота f1 является (как правило) частотой основного тона речевого сигнала.
На выходах БПФ образуется n напряжений синусоидальной формы Uf,i, которые по частоте равномерно распределены в диапазоне f1 – fn. Этот набор «гармоник» представляет собой спектр речевого сигнала, зафиксированного в ряде точек частотного диапазона речевого сигнала. Гармонические колебания Uf,i подаются на соответствующие входы блока детектирования для дальнейшей обработки спектральных составляющих речевого сигнала.
БД – блок детектирования; осуществляет образование и запоминание максимальных амплитуд сигналов Uf,i в каждом из частотных каналов (или амплитуд этих сигналов, превышающих заданный уровень).
КОМ – высокочастотный коммутатор, осуществляющий (под управлением МП) подачу компонентов X1,к – Xn,к на АЦП.
АЦП – аналого-цифровой преобразователь; преобразует двоичный код в к- ом столбце в вектор-столбец – набор цифровых данных а1к – аnк.
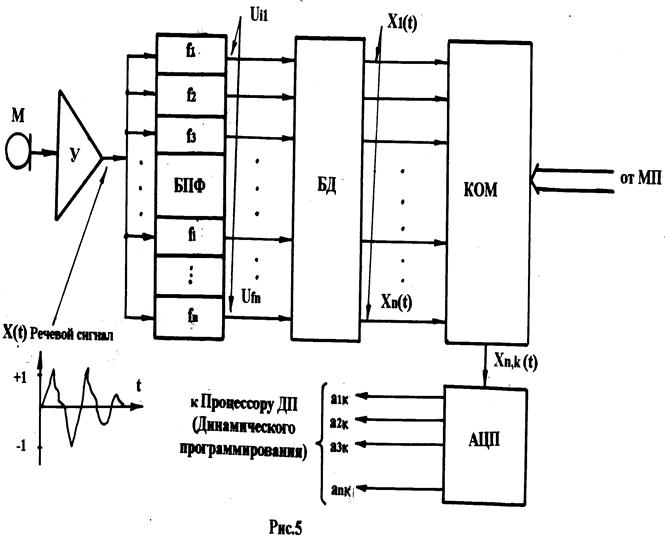
Временная диаграмма, иллюстрирующая работу предпроцессора, приведена на рис. 6. Временная диаграмма построена в сокращённом виде – всего для 3-х частотных каналов (1-го – 3-го из 16), что не влияет на общность рассмотрения.
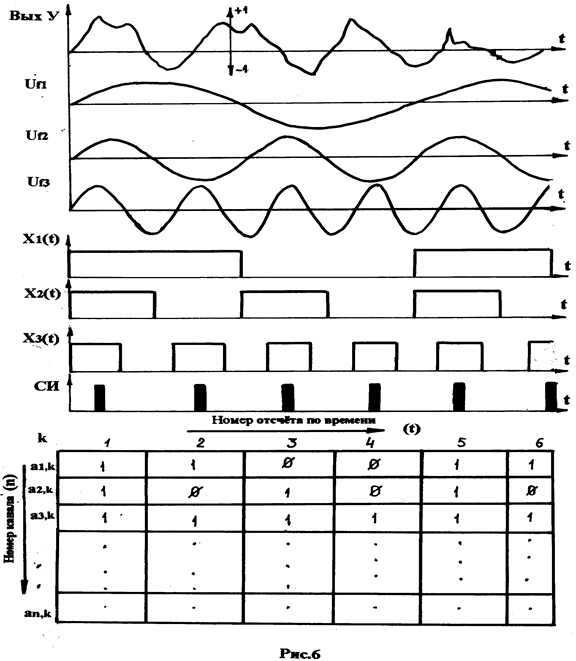
С выхода усилителя У (рис. 5), нормированный по амплитуде речевой сигнал X(t) поступает на блок полосовых фильтров (БПФ), на котором он преобразуется в гармонические составляющие Uf1 – Uf3. Синусоидальные сигналы поступают на блок детектирования БД, который преобразует
(детектирует) гармонические сигналы, то есть фиксирует максимальную амплитуду сигнала на отрезках времени, на которых гармонический сигнал положителен (Ufi >0). На выходах блока детектирования, таким образом, возникают прямоугольные сигналы X1(t) – Xn(t), где n – номер частотного канала. Длительность этих сигналов уменьшается в соответствии с возрастанием номера частотного канала.
Параллельно с образованием указанных выше сигналов производится формирование двоичной матрицы (рис. 6), которая представляет собой «цифровой портрет» речевого сигнала, состоящий из двоичных единиц и нулей. Каждый элемент матрицы образуется в момент появления синхроимпульса (СИ), который фиксирует номер отсчёта по времени.
Элемент матрицы принимает значение «1», если сигнал Xi (t) имеет высокий уровень и равен «0 в противном случае. Сформированный на очередном отсчёте столбец матрицы (а1, а2, а3,…,аn) записывается в ОЗУ-ЭТ (рис. 4).
В результате обработки речевого фрагмента в ОЗУ эталонов формируется матрица эталонов. В режиме распознавания формирование матрицы речевого сигнала (матрицы реализации) осуществляется аналогично.
На рис. 7 приведена матрица признаков распознаваемого слова.

Строки матрицы (16 строк) соответствуют номеру частотного канала, а столбцы – номеру отсчёта по времени.
В режиме распознавания, выполняется последовательное сравнение всех эталонов словаря с набором аналогичных признаков, полученных при произнесении слова (команды) в микрофон УРВ. В результате формируются меры сходства (или несходства) со всеми эталонами.
По результатам анализа полученных мер сходства микропроцессор принимает решение и передаёт его на дисплей (Д) и в интерфейсный блок.
Сравнение эталонов и вычисление мер сходства сопряжены с трудностями. Например, возникает задача их нормализации по длительности, так как при речевом вводе одного и того же сообщения могут быть значительные отличия формы и величины исходного сигнала с микрофона из-за нелинейного изменения темпа речи или силы голоса.
Амплитудные изменения учитываются при обработке речевого сигнала в предпроцессоре (ПП). Изменения в темпе произнесения учитываются более сложным путём, например, нормализацией сигнала по времени, разбиением его на определённое число интервалов.
Используются, так же алгоритмы динамического программирования ( ДП), обеспечивающие наилучшее возможное выравнивание между неизвестным высказыванием и эталоном.
Для реализации процедуры ДП составляется матрица различия двух образов: реализации (распознаваемого слова) и очередного эталона, с которым производится сравнение. Для выполнения процедуры ДПпервый столбец матрицы признаков слова сравнивается со всеми столбцами признаков эталона. Оцениваются меры близости этих отдельных отсчётов – частичные меры. Они заносятся в первую строку формируемой таким образом матрицы различия образцов.
Для определения частичной меры схожести можно воспользоваться, например, простейшим правилом: при полном совпадении кодов в каждом из разрядов столбцов результат равен сумме разрядов столбцов (16 в нашем случае, рис. 7), при совпадении в половине разрядов – 8 и так далее. В случае определения меры отличия (несходства) – картина обратная – результат равен нулю при полном совпадении кодов и нарастает в зависимости от степени отличия.
Затем, берутся остальные столбцы матрицы признаков слова, и каждый из них последовательно сравнивается со столбцом матрицы признаков эталона. В ходе такой процедуры последовательно заполняется вторая и остальные строки матрицы различия образов.
Чтобы определить меру различия двух образов, необходимо просуммировать частичные меры различия по любому пути, соответствующему возможным деформациям оси времени. При этом оптимальная деформация даёт минимальную меру различия образов.
Для нахождения оптимального пути используют аппарат ДП. Один из возможных вариантов процедуры ДП выглядит так:
М (i, j) = min{M(i-1,j) + m(i, j);
M(i-1, j-1) +2m(i, j); (3)
M(i, j-1) +m(i, j), где:
I - Координата по оси ординат – номер отсчёта признаков распознаваемого слова;
J -Координатапо осиабсцисс – номер отсчётов признаков эталона;
M -Полная мера различия в точках матрицы;
m- Частичная мера различия.
На основе выражения (3) строится матрица оптимального пути и подсчитывается мера M(I,J) в его конце.
Как видно из изложенного выше процесс распознавания, состоящий из вычисления мер сходства (различия) реализации и эталона очень трудоёмкий процесс. Поэтому для реализации алгоритмов ДП используется специализированный процессор, так как решение этой задачи программными средствами приводит к большим затратам времени.
Учитывая относительно большой словарь УРВ, а также тот факт, что каждое слово произносится некоторое время (разное для разных слов), ДП - процессор, кроме того, должен нормировать время произнесения и слова и в приемлемое время дать ответ о сходстве (несходстве) произнесённого слова и эталона. Поэтому ДП - процессор реализуется аппаратно.
|
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 694; Нарушение авторских прав?; Мы поможем в написании вашей работы!