КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Мультипроцессоры
|
|
|
|
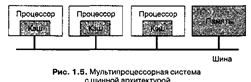
Мультипроцессорные системы обладают одной характерной особенностью: все процессоры имеют прямой доступ к общей памяти. Мультипроцессорные системы шинной архитектуры состоят из некоторого количества процессоров, подсоединенных к общей шине, а через нее — к модулям памяти. Простейшая конфигурация содержит плату с шиной или материнскую плату, в которую вставляются процессоры и модули памяти.
Поскольку используется единая память, когда процессор А записывает слово в память, а процессор В микросекундой позже считывает слово из памяти, процессор В получает информацию, записанную в память процессором А. Память, обладающая таким поведением, называется согласованной (coherent). Проблема такой схемы состоит в том, что в случае уже 4 или 5 процессоров шина оказывается стабильно перегруженной и производительность резко падает. Решение состоит в размещении между процессором и шиной высокоскоростной кэш-памяти (cache memory), как показано на рис. 1.5. В кэше сохраняются данные, обращение к которым происходит наиболее часто. Все запросы к памяти происходят через кэш. Если запрошенные данные находятся в кэш-памяти, то на запрос процессора реагирует она и обращения к шине не выполняются. Если размер кэш-памяти достаточно велик, вероятность успеха, называемая также коэффициентом кэш-попаданий (hit rate), велика и шинный трафик в расчете на один процессор резко уменьшается, позволяя включить в систему значительно больше процессоров. Общепринятыми являются размеры кэша от 512 Кбайт до 1 Мбайт, коэффициент кэш-попаданий при этом обычно составляет 90 % и более.
Однако введение кэша создает серьезные проблемы само по себе. Предположим, что два процессора, А и В, читают одно и то же слово в свой внутренний кэш. Затем А перезаписывает это слово. Когда процессор В в следующий раз захочет воспользоваться этим словом, он считает старое значение из своего кэша, а не новое значение, записанное процессором А. Память стала несогласованной, и программирование системы осложнилось. Кэширование, тем не менее, активно используется в распределенных системах, и здесь мы вновь сталкиваемся с проблемами несогласованной памяти.
|
|
|
Проблема мультипроцессорных систем шинной архитектуры состоит в их ограниченной масштабируемости, даже в случае использования кэша. Для построения мультипроцессорной системы с более чем 256 процессорами для соединения процессоров с памятью необходимы другие методы. Один из вариантов — разделить общую память на модули и связать их с процессорами через коммутирующую решетку (crossbar switch), как показано на рис. 1.6, а. Как видно из рисунка, с ее помощью каждый процессор может быть связан с любым модулем памяти. Каждое пересечение представляет собой маленький электронный узловой коммутатор (crosspoint switch), который может открываться и закрываться аппаратно. Когда процессор желает получить доступ к конкретному модулю памяти, соединяющие их узловые коммутаторы мгновенно открываются, организуя запрошенный доступ. Достоинство узловых коммутаторов в том, что к памяти могут одновременно обращаться несколько процессоров, хотя если два процессора одновременно хотят получить доступ к одному и тому же участку памяти, то одному из них придется подождать.
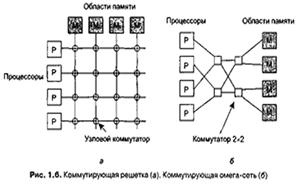
Недостатком коммутирующей решетки является то, что при наличии n процессоров и n модулей памяти нам потребуется n 2 узловых коммутаторов. Для больших значений n это число может превысить наши возможности. Обнаружив это, человечество стало искать и нашло альтернативные коммутирующие сети, требующие меньшего количества коммутаторов. Один из примеров таких сетей — омегасеть (omega network), представленная на рис. 1.6, б. Эта сеть содержит четыре коммутатора 2x2, то есть каждый из них имеет по два входа и два выхода. Каждый коммутатор может соединять любой вход с любым выходом. Если внимательно изучить возможные положения коммутаторов, становится ясно, что любой процессор может получить доступ к любому блоку памяти. Недостаток коммутирующих сетей состоит в том, что сигнал, идущий от процессора к памяти или обратно, вынужден проходить через несколько коммутаторов. Поэтому, чтобы снизить задержки между процессором и памятью, коммутаторы должны иметь очень высокое быстродействие, а дешево это не дается.
|
|
|
Люди пытаются уменьшить затраты на коммутацию путем перехода к иерархическим системам. В этом случае с каждым процессором ассоциируется некоторая область памяти. Каждый процессор может быстро получить доступ к своей области памяти. Доступ к другой области памяти происходит значительно медленнее. Эта идея была реализована в машине с неунифицированным доступом к памяти (NonUniform Memory Access, NUMA). Хотя машины NUMA имеют лучшее среднее время доступа к памяти, чем машины на базе омегасетей, у них есть свои проблемы, связанные с тем, что размещение программ и данных необходимо производить так, чтобы большая часть обращений шла к локальной памяти.
|
|
|
|
|
Дата добавления: 2013-12-14; Просмотров: 726; Нарушение авторских прав?; Мы поможем в написании вашей работы!