КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коэффициенты корреляции
|
|
|
|
Коэффициенты корреляции рангов – это менее точные, но более простые по расчету непараметрические показатели для измерения тесноты связи между двумя коррелируемыми признаками. К ним относятся коэффициенты Спирмэна (ρ) и Кендэла (τ), основанные на корреляции не самих значений коррелируемых признаков, а их рангов – порядковых номеров, присваиваемых каждому индивидуальному значению х и у (отдельно) в ранжированном ряду. Оба признака необходимо ранжировать (нумеровать) в одном и том же порядке: от меньших значений к большим и наоборот. Если встречается несколько значений х (или у), то каждому из них присваивается ранг, равный частному от деления суммы рангов (мест в ряду), приходящихся на эти значения, на число равных значений. Ранги признаков х и у обозначают символами Rx и Ry (иногда Nx и Ny). Суждение о связи между изменениями значений х и у основано на сравнении поведения рангов по двум признакам параллельно. Если у каждой пары х и у ранги совпадают, это характеризует максимально тесную связь. Если же наблюдается полная противоположность рангов, т.е. в одном ряду ранги возрастают от 1 до n, а в другом – убывают от n до 1, это максимально возможная обратная связь. Подходы для оценки тесноты связи у Спирмэна и Кендэла несколько различаются. Для расчета коэффициента Спирмэна значения признаков х и у нумеруют (отдельно) в порядке возрастания от 1 до n, т.е. им присваивают определенный ранг (Rx и Ry) – порядковый номер в ранжированном ряду. Затем для каждой пары рангов находят их разность (обозначается как d = Rx – Ry), и квадраты этой разности суммируют.
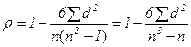 , (21)
, (21)
где d – разность рангов х и у;
n – число наблюдаемых пар значений х и у.
|
|
|
Коэффициент ρ может принимать значения от 0 до ±1. Следует иметь в виду, что, поскольку коэффициент Спирмэна учитывает разность только рангов, а не самих значений х и у, он менее точен по сравнению с линейным коэффициентом. Поэтому его крайние значения (1 или 0) нельзя безоговорочно расценивать как свидетельство функциональной связи или полного отсутствия зависимости между х и у. Во всех других случаях, т.е. когда ρ не принимает крайних значений, он довольно близок к r.
Формула (21) применима строго теоретически только тогда, когда отдельные значения х (и у), а следовательно, и их ранги не повторяются. Для случая повторяющихся (связанных) рангов есть другая, более сложная формула, скорректированная на число повторяющихся рангов. Однако опыт показывает, что результаты расчетов по скорректированной формуле для связанных рангов мало отличаются от результатов, полученных по формуле для неповторяющихся рангов. Поэтому на практике формула (21) успешно применяется как для неповторяющихся, так и для повторяющихся рангов.
Коэффициент корреляции рангов Кендэла τ строится несколько по-другому, хотя его расчет также начинается с ранжирования значений признаков х и у. Ранги х (Rx) располагают строго в порядке возрастания и параллельно записывают соответствующее каждому Rx значение Ry. Поскольку Rx записаны строго по возрастанию, то ставится задача определить меру соответствия последовательности Ry «правильному» следованию Rx. При этом для каждого Ry последовательно определяют число следующих за ним рангов, превышающих его значение, и число рангов, меньших по значению. Первые («правильное» следование) учитываются как баллы со знаком «+», и их сумма обозначается буквой Р. Вторые («неправильное» следование) учитываются как баллы со знаком «–», и их сумма обозначается буквой Q. Очевидно, что максимальное значение Р достигается в том случае, если ранги y (Ry) совпадают с рангами х (Rx) и в каждом ряду представляют ряд натуральных чисел от 1 до п. Тогда после первой пары значений Rx = 1 и Ry = 1 число превышения данных значений рангов составит (n – 1), после второй пары, где Rx = 2 и Ry = 2, соответственно (п – 2) и т.д. Таким образом, если ранги х и у совпадают и число пар рангов равно n, то
|
|
|
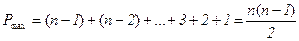 .
.
Если же последовательность рангов х и у имеет обратную тенденцию по отношению к последовательности рангов х, то Q будет такое же максимальное значение по модулю:
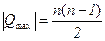 .
.
Если же ранги у не совпадают с рангами х, то суммируются все положительные и отрицательные баллы (S=P+Q); отношение этой суммы S к максимальному значению одного из слагаемых и представляет собой коэффициент корреляции рангов Кендэла τ, т.е.
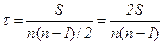 . (22)
. (22)
Формула коэффициента корреляции рангов Кендэла (22) применяется для случаев, когда отдельные значения признака (как х, так и у) не повторяются и, следовательно, их ранги не объединены. Если же встречается несколько одинаковых значений х (или у), т.е. ранги повторяются, становятся связанными, коэффициент корреляции рангов Кендэла определяется по формуле
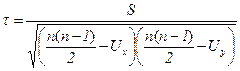 , (23)
, (23)
где S – фактическая общая сумма баллов при оценке +1 каждой пары рангов с одинаковым порядком изменения и –1 каждой пары рангов с обратным порядком изменения;
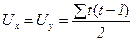 – число баллов, корректирующих (уменьшающих) максимальную сумму баллов за счет повторений (объединений) t рангов в каждом ряду.
– число баллов, корректирующих (уменьшающих) максимальную сумму баллов за счет повторений (объединений) t рангов в каждом ряду.
Отметим, что случаи следования одинаковых повторяющихся рангов (в любом ряду) оцениваются баллом 0, т.е. они не учитываются при расчете ни со знаком «+», ни со знаком «–».
Преимущества ранговых коэффициентов корреляции Спирмэна и Кендэла: они легко вычисляются, с их помощью можно изучать и измерять связь не только между количественными, но и между качественными (атрибутивными) признаками, ранжированными определенным образом. Кроме того, при использовании ранговых коэффициентов корреляции не требуется знать форму связи изучаемых явлений.
Если число ранжируемых признаков (факторов) больше двух, то для измерения тесноты связи между ними можно использовать предложенный М. Кендэлом и Б. Смитом коэффициент конкордации (множественный коэффициент ранговой корреляции)
|
|
|
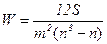 , (24)
, (24)
где S — сумма квадратов отклонений суммы т рангов от их средней величины;
т — число ранжируемых признаков;
п — число ранжируемых единиц (число наблюдений).
Формула (24) применяется для случая, кода ранги по каждому признаку не повторяются. Если же есть связанные ранги, то коэффициент конкордации рассчитывается с учетом числа таких повторяющихся (связанных) рангов по каждому фактору:
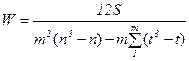 , (25)
, (25)
где t – число одинаковых рангов по каждому признаку.
Коэффициент конкордации W может принимать значения от 0 до 1. Однако, необходимо проверить его на существенность (значимость) с помощью критерия χ2:
при отсутствии связанных рангов 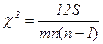 (26)
(26)
при наличии связанных рангов 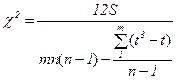 (27)
(27)
Фактическое значение χ2 сравнивается с табличным, соответствующим принятому уровню значимости α (0,05 или 0,01) и числу степеней свободы v = п – 1. Если χ2факт > χ2табл, то W – существенен (значим).
Коэффициент конкордации особенно часто используется в экспертных оценках, например, для того, чтобы определить степень согласованности мнений экспертов о важности того или иного оцениваемого показателя или составить рейтинг отдельных единиц по какому-либо признаку.
В формуле (24) в этих случаях т означает число экспертов, а n — число ранжируемых единиц (или признаков).
[1] Термин «стохастический» происходит от греч. «stochos» – мишень. Стреляя в мишень, даже хороший стрелок редко попадает в ее центр, выстрелы ложатся в некоторой близости от него. Другими словами стохастическая связь означает приблизительный характер значений признака
[2] Проявление стохастических связей подвержено действию закона больших чисел: лишь в достаточно большом числе единиц индивидуальные особенности сгладятся, случайности взаимопогасятся и зависимость, если она имеет существенную силу, проявится достаточно отчетливо
[3] Термин «корреляция» ввел в статистику английский биолог и статистик Ф. Гальтон в конце XIX в., под которым понималась «как бы связь», т.е. связь в форме, отличающейся от функциональной. Еще ранее этот термин применил француз Ж.Кювье в палеонтологии, где под законом корреляции частей животных он понимал возможность восстановить по найденным в раскопках частям облик всего животного
|
|
|
[4] Множественная корреляция изучается в курсе эконометрики на основе применения компьютерных программ (напр., специальная надстройка к Excel, SPSS и др.), в курсе статистики изучается только парная корреляция
[5] Формула (6) непосредственно выведена из формулы (5)
[6] По значению коэффициент контингенции всегда меньше коэффициента ассоциации
[7] Формула (12) получена из формулы (11) вынесением и за знак суммы (как постоянные величины)
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 406; Нарушение авторских прав?; Мы поможем в написании вашей работы!