КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 2. Программирование простейших фильтров нижних частот
|
|
|
|
Г
Программирование простейших фильтров нижних частот
1. Рекурсивные фильтры. Алгоритм экспоненциального сглаживания.
Простейший фильтр нижних частот это RC-цепочка. Если на входе действует дельта-функция 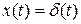 , то выход — импульсная характеристика фильтра — имеет вид:
, то выход — импульсная характеристика фильтра — имеет вид: 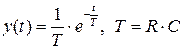 .
.
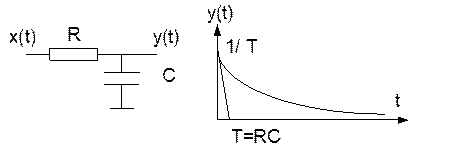
Цифровой аналог RC цепи — алгоритм экспоненциального сглаживания.
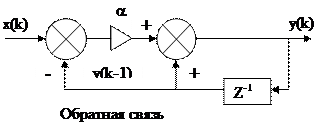
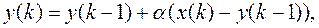 0< a <1 — коэффициент.
0< a <1 — коэффициент.
|

Пусть очередной входной отсчет  — положительное число с форматом 1 байт, помещается другой частью программы в ячейку с именем x. Коэффициент фильтра
— положительное число с форматом 1 байт, помещается другой частью программы в ячейку с именем x. Коэффициент фильтра 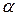 находится в ячейке памяти с именем alpha. Очередной выходной отсчет
находится в ячейке памяти с именем alpha. Очередной выходной отсчет 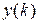 должен быть помещен в ячейку памяти с именем y. Взаимодействие с АЦП и ЦАП рассматривать не будем. Заметим только, что срочная задача с именем Main вызывается по прерыванию от АЦП.
должен быть помещен в ячейку памяти с именем y. Взаимодействие с АЦП и ЦАП рассматривать не будем. Заметим только, что срочная задача с именем Main вызывается по прерыванию от АЦП.
x: DS 1;место для очередного отсчета входного сигнала
alpha: DS 1;место для коэффициента
y: DS 1;место для очередного отсчета выходного сигнала
Обозначим 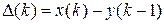 , тогда выражение для экспоненциального сглаживания примет вид:
, тогда выражение для экспоненциального сглаживания примет вид: 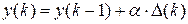 .
.
Разность 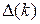 может быть как положительной, так и отрицательной.
может быть как положительной, так и отрицательной.
Разность отрицательная:
1. Найти модуль разности.
2. Умножить модуль на значение в ячейке alpha. В результате умножения получится 2-х байтовое число. Отбрасывание младшего байта произведения означает деление на 256:
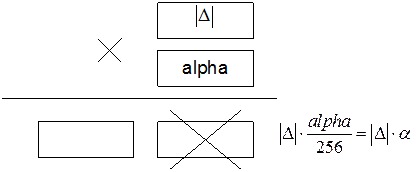
Если учесть, что 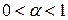 , то число в ячейке alpha следует выбирать в диапазоне:
, то число в ячейке alpha следует выбирать в диапазоне: 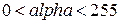 , например 100, что соответствует
, например 100, что соответствует 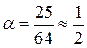 . Т.е. проводится неявное масштабирование.
. Т.е. проводится неявное масштабирование.
3. Вычесть старший байт произведение из значения  .
.
В случае положительной разности нет необходимости находить модуль и значение произведения следует прибавлять к .
Дополнение к блоку инициализации:
|
|
|
mov alpha, #100;задать коэффициент
mov y, #0;начальные условия нулевые
Дополнение к срочной задаче Main:
mov A, x;взять вх. отсчет
clr С;подготовить вычитание
subb A, y;вычесть
mov F0, c;запомнить знак D
jnc Dp;переход по дельта плюс
cpl A;обратный код разности
inc A;модуль разности
Dp: mov B, alpha;загружаем альфа
mul AB;мл. байт произведения в А, ст. — в В
jnb Aсс.7, Nс;перейти если в аккумуляторе
;маленькое число
inc B;округляем произведение в В
Nс: mov A, y;взять предыдущий выходной отсчет
jnb F0, Pos;перейти, если нужно прибавлять
clr С;подготовка вычитания
subb A, B;вычесть приращение
sjmp Store;перейти на запоминание
Pos: add A, B;прибавить D, умноженное на a
Store: mov y, A;запомнить текущий выходной отсчет
2. Нерекурсивный фильтр
 Медленно меняющийся сигнал
Медленно меняющийся сигнал
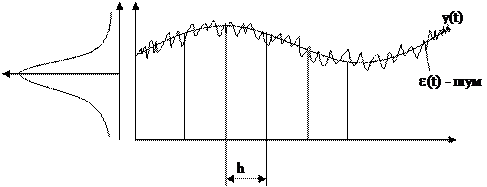
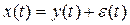 — наблюдаемый сигнал,
— наблюдаемый сигнал, 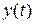 — полезный сигнал,
— полезный сигнал, 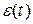 — шум.
— шум.
h – интервал дискретизации.
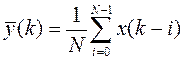 - текущее среднее значение,
- текущее среднее значение, 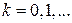 . Очевидно, что пока
. Очевидно, что пока 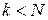 в фильтре будет наблюдаться переходной процесс. Если распределение шума нормальное, то текущее среднее значение является наилучшей оценкой для сигнала . Пусть окно для усреднения содержит N=8 отсчетов, i=0,1,…,7.
в фильтре будет наблюдаться переходной процесс. Если распределение шума нормальное, то текущее среднее значение является наилучшей оценкой для сигнала . Пусть окно для усреднения содержит N=8 отсчетов, i=0,1,…,7.
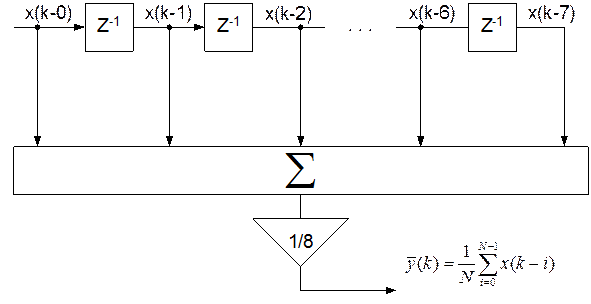
Для вычисления текущего отсчета 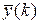 потребуется текущий входной отсчет
потребуется текущий входной отсчет 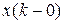 и 7 предыдущих входных отсчетов
и 7 предыдущих входных отсчетов  .
.
Пусть x(k) имеет формат 12-ть бит и помещается в регистры R1и R0.
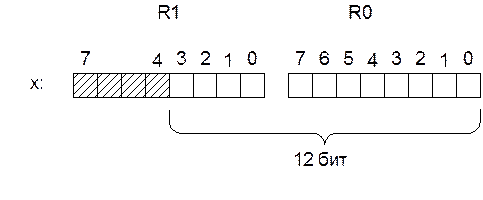
Для хранения 8-ми входных отсчетов по два байта в каждом организуем кольцевой буфер размером 16-ть байтов. Пометим начало буфера меткой Buf. Вновь пришедший отсчёт всегда будем записывать на место самого старого. Для этого выделим указатель смещения в буфере — байт памяти с именем Pbuf. Значение этого указателя будет меняться от 0 до 7.
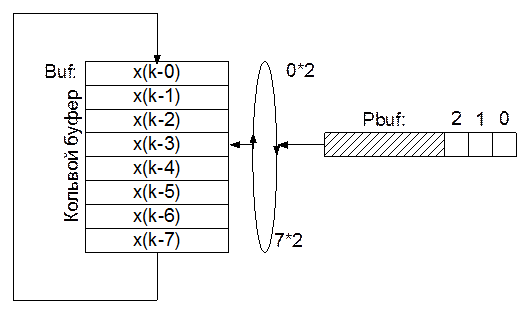
Учитывая, что до полного заполнения буфера в фильтре идет переходной процесс, начальное значение указателя Pbuf никакого значения не имеет. Нужно только обнулить незначащие биты с номерами от 3 до 7.
Резервируем место для кольцевого буфера и указателя смещения в буфере:
Buf: DS 16;16 байтов кольцевого буфера
|
|
|
Pbuf: DS 1;1 байт указателя
Адрес входного отсчета в кольцевом буфере формируется как сумма начального адреса буфера Buf и содержимого указателя Pbuf, умноженного на 2 (учет 2-х байтового формата входного отсчета).
Вызов срочной задачи Main по прежнему осуществляется по прерыванию от АЦП. Результат фильтрации помещаем в пару регистров А — младший байт, В — старший байт.
Дополнение к задаче Main:
………………………………………..
Start: inc Pbuf;приращение указателя
anl Pbuf, #07h;ограничивает приращение,
;организация кольцевого буфера
mov A, Pbuf;для формирования адреса
rl A;сдвиг влево на 1 разряд,
;учёт 2х байтового формата
add A, #Buf;формирование адреса в буфере
xch A, R0;загрузка в R0 адреса буфера,
;в А мл. байт входного отсчета
mov @R0, A;поместить мл. байт в буфер
inc R0;скорректировать адрес
mov A, R1;старший байт в А
mov @R0, A;запись старшего байта в буфер
;После обновления буфера можно просуммировать все хранящиеся в нем;отсчёты входного сигнала.
clr A;для накопления младших байтов
mov B, A;для накопления старших байтов
mov R1, #8;для счёта количества циклов
mov R0, #Buf;для чтения из буфера
Next: add A, @R0;накопление младших байтов
xch A, B;
inc R0;
addc A, @R0;накопление старших байтов
xch A, B;в А мл. байт суммы, в В — старший
inc R0;скорректировать адрес в буфере
djnz R1,Next;декрементировать счетчик
;и если не все вернуться
;Получить среднее значение можно посредством 3х сдвигов вправо
clr C;подготовка сдвига
xch A, B;начнем сдвиг со старшего байта
rrc A;поделим на 2
xch A, B;теперь младший
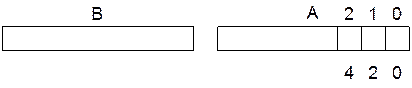
add A, #4;округление перед делением
jnc Car
inc B
Car: anl A, #11111000b;очистка лишних разрядов
clr C
rrc A;сумму поделили на 2
xch A, B;
rrc A;
xch A, B;
rrc A;еще раз на 2 (уже на 4)
xch A, B;
rrc A;
xch A, B;
rrc A;сумму поделили на 8

1. Классификация лингвистических методов.
2. Верификация, доказательство и аргументация в лингвистике
3. Методы смежных наук, используемые в лингвистике.
1. Метод- совокупность приемов, а также средство добывания знаний для новой теории. Методика- совокупность приемов, средств для получения новых знаний. Методология- общее учение о методах, их систематизация, которая включает предпосылки, исходные принципы и средства реализации. Гипотеза – это научное предположение, выдвигаемое перед исследованием в целях верификации.
|
|
|
Теория – система гипотез, проверяемых и корректируемых практикой. Она имеет вероятностный характер, развивается по спирали и является высшей формой обобщения знаний. Это комплекс взглядов, представлений, идей, объясняющих какое-либо явление.
2. Лингвистические методы не представляет собой единого набора принципов и способов исследования и описания языковых сущностей. Скорее это некоторое «меню» взаимодополняющих и/или взаимоисключающих методов, используемых в различных комбинациях и в различных пропорциях в частных лингвистиках и в конкретных лингвистических исследованиях. Более того, этот набор не является постоянным. Непрерывно происходит его обогащение, изменяется также отношение к тем или иным методам: в различные исторические периоды и в различных научных школах один и тот же метод может быть доминирующим в лингвистической практике или же, напротив, научно дискредитированным. Каждая научная школа характеризуется, наряду с исходными презумпциями и целями, своим репертуаром престижных методов. В то же время конкретные исследовательские методы в общем случае долговечнее научных школ, и при их смене многие из методов наследуются новой парадигмой. Из сказанного выше очевидно, что дать исчерпывающее перечисление лингвистических методов для всех «частных лингвистик» и для всех научных парадигм не представляется возможным. Ограничимся, прежде всего, методами, направленными на решение проблем описательной и теоретической лингвистики, и будем исходить из некоторого обобщенного представления о современном состоянии лингвистики и ее методических предпочтений.
Индукция и дедукция. Известно логическое противопоставление индуктивного и дедуктивного методов исследования. В эмпирических науках, к которым относится и лингвистика, это противопоставление связано с противоречием между природой изучаемого объекта (сущностью) и имеющимся в распоряжении исследователя эмпирическим материалом (фактами). Как уже было замечено выше, объект лингвистики – язык – не дан исследователю в непосредственном наблюдении. Наблюдаемым эмпирическим материалом исследователя являются косвенные свидетельства о языке, а именно – продукты языковой деятельности (языковые выражения). Количество единичных языковых фактов бесконечно, поэтому сбор всех фактов является принципиально неразрешимой задачей и не может быть конечной целью исследования. Факты необходимы исследователю лишь как носители сущностных свойств языка, так как бесконечное множество фактов есть реализация конечного и весьма ограниченного множества стоящих за ними сущностей. Таким образом, целью лингвистики является обнаружение этих сущностей и описание бесконечного множества наблюдаемых фактов через обращение к этим сущностям.
|
|
|
Процесс научного исследования в такой ситуации может быть двунаправленным: от фактов к сущностям или от сущностей к фактам. Индуктивный метод организации научного процесса в целом состоит в сборе и документации конкретных явлений (фактов) с последующим их обобщением и переходом от фактов к лежащим в их основе сущностям. Дедуктивный метод в качестве отправного пункта предполагает, напротив, основанное на определенных допущениях постулирование сущностей и проверку реальности этих сущностей их соответствием (или несоответствием) наблюдаемым фактам.
В реальной лингвистической практике применение индуктивного или дедуктивного метода в чистом виде невозможно, хотя определенное предпочтение того или иного метода в конкретных научных школах наблюдается нередко. Наиболее продуктивным, скорее всего, является цикличное применение дедуктивного и индуктивного метода с последовательным уточнением представления об изучаемом объекте. А именно, на начальной стадии дедуктивно выдвигаются некоторые гипотезы о языковых сущностях, которые затем индуктивно проверяются в процессе эмпирической работы с наблюдаемым языковым материалом и индуктивных обобщений. Как правило, при этом обнаруживается определенное (порою значительное) несоответствие постулированных сущностей и индуктивно полученных обобщений. Это требует на очередном цикле новых дедуктивных построений и их последующей индуктивной проверки.
Эвристические методы. Эвристические методы связаны со сбором и документацией фактов. Сам процесс получения фактов может быть пассивным или активным. Метод пассивного наблюдения (иначе именуемый регистрационным) предпочитается тогда, когда необходимо получить максимально достоверный языковой материал, независимый от воли исследователя и процесса извлечения языковых данных. Таким материалом является спонтанная речь носителей языка в естественной коммуникативной ситуации. Исследователь является лишь регистратором этой речи или использует ранее зафиксированную речь (например, письменные тексты). Широко распространенной практикой является использование примеров из литературных текстов, однако в целом данный метод не обеспечивает абсолютной чистоты языкового материала, поскольку письменные литературные тексты создаются в искусственной коммуникативной ситуации, когда автор текста имеет возможность обдумывать и изменять написанный текст. Первичной формой реализации языковой деятельности является спонтанная и, прежде всего, диалогическая речь. В последние десятилетия технические средства автоматической фиксации устной речи предоставили исследователям неограниченный доступ к таким фактам; особенно значительный их объем был собран японскими исследователями, принадлежащими так называемой «школе языкового существования» (см. ЯЗЫКОВОГО СУЩЕСТВОВАНИЯ ШКОЛА). Кроме того, новые компьютерные технологии создали условия для появления так называемой корпусной лингвистики, являющейся инструментальным средством усиления пассивного метода, позволяющим обследовать огромные массивы текстов и извлекать из них нужные факты.
Активный (он же экспериментальный) метод состоит в применении всевозможных процедур, управляющих речевым поведением говорящего, с целью получения необходимых исследователю фактов. Например, при изучении словоизменения или словообразования может использоваться парадигматический опрос, предъявление определенным образом модифицированных или специально сконструированных предложений для проверки их грамматической правильности или грамматической интерпретации, предъявление некоторого контекста с предложением его продолжить, перевод с языка-стимула на исследуемый язык и т.д. В качестве стимула для речевого действия могут предъявляться различные объекты или ситуации реального мира: предметы и комбинации предметов, действия с предметами, картинки, фрагменты видеофильмов или компьютерных фильмов – с целью вербального описания испытуемым этого стимула и т.д. Экспериментальный метод является ведущим в психолингвистике и полевой лингвистике.
Интроспективный метод используется, когда языковые факты исследователь не регистрирует, а создает сам, используя себя как носителя языка.
В последние десятилетия в лингвистике все более активно используются различные инструментальные методы. Классической областью их применения (еще с конца 19 в.) является экспериментальная фонетика, в которой исследование осуществляется с помощью различных приборов, фиксирующих артикуляторные и акустические параметры звуковых последовательностей. Весьма разнообразной является инструментальная технология и в психолингвистике. Современные компьютерные технологии позволяют также расширить эмпирическую базу лингвистики.
Метод моделирования является важным компонентом дедуктивного подхода к языку. Моделирование в общем случае является особенно эффективным средством изучения объектов, не данных в непосредственном наблюдении; язык как раз и относится к их числу. Модель в идеале является теоретическим конструктом, отражающим сущностные свойства исследуемого объекта. Проверка адекватности модели объекту осуществляется экспериментально: модель должна вести себя как оригинал в тождественных условиях.
В 1960–1980-е годы весьма популярным был редукционистский вариант метода моделирования, известный как кибернетический метод «черного ящика». Под «черным ящиком» понимается объект, чье реальное внутреннее устройство в принципе не может быть изучено. Метод «черного ящика» исходит из презумпции существования функционально тождественных объектов разной материальной природы и, что особенно существенно, презумпции принадлежности языка именно к такого рода объектам. Метод «черного ящика» оправдывает себя для описания сравнительно элементарных объектов, однако язык к таковым не относится. Поэтому в лингвистике моделирование должно учитывать собственную природу естественного языка.
Описательные методы. В лингвистике используются различные способы представления языковых сущностей и фактов. Традиционная (в том числе структурная) лингвистика исходит из презумпции, что язык состоит из иерархически упорядоченных дискретных сущностей (языковых единиц), каждая из которых обладает уникальным набором признаков (свойств) и образует особый класс, соотносимый по определенным правилам с бесконечным множеством наблюдаемых фактов. Например, в языке на уровне слов выделяются лексические классы, именуемые частями речи – это существительное, глагол, прилагательное и т.д. Каждая часть речи характеризуется множеством грамматических категорий (например, падежа и числа для существительных), которые в свою очередь характеризуются множеством значений (именительный, родительный, винительный и т.д. для падежа, единственное и множественное для числа). Значения грамматических категорий также часто являются множеством более частных значений (например, именительный подлежащего, именительный именного сказуемого и т.д.).
Такое описание языка, называемое таксономическим, по существу является особого рода классификацией, к которой предъявляются определенные требования. Таксономическое описание предполагает установление классов языковых единиц и связей, существующих между ними. Языковые единицы определяются посредством системы необходимых и достаточных признаков. Эта система признаков должна быть максимально полной, т.е. покрывать все объекты, входящие в данный класс, и в то же время максимально узкой, т.е. исключать все объекты, в данный класс не входящие.
В рамках структурной парадигмы к описанию предъявляется требование полноты, т.е. выделения всех сущностей, имеющихся в языке или в его компоненте. Например, на уровне падежей – определение всех падежей, входящих в систему именного склонения или всех словоформ спрягаемого глагола. Если классы в множестве определяются по нескольким основаниям, то обнаружение классов основывается на методе исчисления. Например, максимальное множество словоформ глагола есть результат перемножения всех значений всех сочетающихся словоизменительных грамматических категорий глагола. В полном описании должны быть выделены все реальные элементы этого множества. Например, в русском языке выделяется три времени и два вида, т.е. максимальное число классов, различимых по этому основанию, равно шести. Однако один из классов в русском языке отсутствует (настоящее время совершенного вида). В языках, где глагол различает много категорий, обнаружение всех классов словоформ без использования метода исчисления часто приводит к неполному описанию, так как редко встречающиеся словоформы могут не встретиться исследователю в текстовой выборке.
Наряду с таксономическим возможно и так называемое динамическое описание, к которому предъявляется требование описать все правила, порождающие правильные языковые выражения и только их. Такой тип описания представлен, в частности, в порождающей грамматике или в модели «смысл текст». Он исходит из презумпции, что язык – это не просто свод языковых единиц, но и некоторый механизм, создающий последовательности этих единиц, соответствующих наблюдаемым языковым выражениям. Наряду с классификацией языковых единиц в таком описании описывается процедура вывода правильных языковых выражений. В динамическом описании значительное внимание уделяется языковым правилам.
Для всякого описания стоит проблема адекватности описания объекту. Описание обобщает представительный материал некоторой конечной выборки данных, которую оно в идеале должно описывать адекватно. Проверка адекватности осуществляется на дополнительной контрольной выборке. Если описание удовлетворяет произвольной контрольной выборке, то с определенной вероятностью можно полагать, что описание адекватно. В противном случае необходима модификация описания и проверка на новой выборке и т.д.
Объяснительные описания. Таксономические и динамические описания отвечают на вопрос, как устроен язык. В последние десятилетия к описанию предъявляется также требование объяснения того, почему язык устроен именно таким, а не другим образом. Такие описания называются объяснительными.
Объяснения могут быть внутриязыковыми (обращение к системным или историческим факторам, в частности, объяснения через аналогию, через процессы языковых контактов; к ареальным или генетическим связям исследуемого языка; к типологическим закономерностям) и внеязыковыми (например, апелляция к когнитивным структурам и механизмам; к устройству внеязыковой действительности; к социальным, психическим, культурным факторам). Возможности объяснительного подхода еще далеко не исчерпаны, и в настоящее время идет активная его разработка. Очевидно, что именно в рамках этого подхода лингвистика вплотную приближается к пониманию своего объекта.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 604; Нарушение авторских прав?; Мы поможем в написании вашей работы!