КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Передумови застосування МНК
|
|
|
|
Розглянемо припущення, які складають основу класичного регресійного аналізу. Для простої лінійної регресії вони мають такий вигляд:
1) математичне сподівання залишків дорівнює нулю, тобто
M (U) = 0
Якщо математичне сподівання залишків не дорівнює нулю, то це означає, що існує систематичний вплив на залежну змінну, а до моделі не введено всіх основних незалежних змінних. Якщо ця передумова не виконується, то йдеться про помилку специфікації.
2) значення uі вектора залишків U незалежні між собою і мають постійну дисперсію
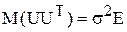 ,
,
де Е – одинична матриця.
Ця умова передбачає наявність сталої дисперсії залишків. Цю властивість називають гомоскедистичною. Проте, вона може виконуватися тоді, коли залишки uі є помилками вимірювання. Якщо залишки акумулюють загальний вплив змінних, які не враховані в моделі, то,звичайно, дисперсія залишків не може бути сталою величиною, вона змінюється для окремих груп спостережень. В такому разі йдеться про явище гетероскедастичності, що впливає на методи оцінювання параметрів.
3) незалежні змінні моделі не пов’язані з залишками
M (xTU) = 0
Ця умова порушується, як правило, тоді, коли економетрична модель будується на базі одночасних структурних рівнянь або має лагові змінні. Тоді для оцінювання параметрів моделі використовують двокрокові або трикрокові МНК.
4) незалежні змінні економетричної моделі утворюють лінійно-незалежну систему векторів, або, іншими словами, незалежні змінні не повинні бути мультиколінеарними.
Це означає, що всі пояснювальні змінні, які входять до економетричної моделі, мають бути незалежними між собою. Проте досить важко виділити такий масив даних, які зовсім не пов’язані між собою. Залежність пояснювальних змінних (мультиколінеарність) негативно впливає на оцінки параметрів моделі або робить побудову моделі взагалі неможливою.
|
|
|
6.4. Коефіцієнти кореляції та детермінації
Коефіцієнт кореляції характеризує ступінь щільності та лінійної залежності між випадковими величинами X і Y.
Коефіцієнти кореляції можна визначити за формулою:
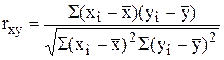 (6.6)
(6.6)
 Коефіцієнт кореляції змінюються в межах [-1;1], при чому якщо rxy > 0, то зв'язок є прямим, якщо rxy<0, то зв'язок є оберненим.
Коефіцієнт кореляції змінюються в межах [-1;1], при чому якщо rxy > 0, то зв'язок є прямим, якщо rxy<0, то зв'язок є оберненим.
Коли коефіцієнт кореляції прямує за абсолютною величиною до l, тобто 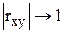 , то це свідчить про наявність сильного зв'язку. В протилежному випадку, коли
, то це свідчить про наявність сильного зв'язку. В протилежному випадку, коли 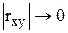 , то зв'язок слабкий або відсутній.
, то зв'язок слабкий або відсутній.
Зазначимо, що параметр а1 має такий самий знак, що й коефіцієнт кореляції.
.
Частина регресії, яку можна пояснити через регресійний зв'язок називається коефіцієнтом детермінації:
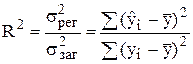 (6.7)
(6.7)
Коефіцієнт детермінації має додатне значення і знаходиться в межах [0;1]. Коефіцієнт детермінації дає інформацію про тісноту зв'язку. Якщо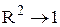 , то зв'язок тісний; якщо
, то зв'язок тісний; якщо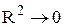 , то зв'язок слабкий або відсутній.
, то зв'язок слабкий або відсутній.
Для лінійних моделей має місце співвідношення:
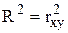 (6.8)
(6.8)
6.5. Коректність побудови економетричної моделі та перевірка значущості оцінки параметрів та моделей загалом.
6.5.1. Поняття про ступені вільності
Розглянемо рівняння:
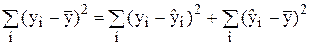
Кожна сума квадратів пов'язана з числом, яке називають її «ступенем вільності». Це число показує, скільки незалежних елементів інформації, що утворилось з елементів y1, y2, y3,…, yn потрібно для розрахунку даної суми квадратів. У статистиці кількістю ступеня вільності називають різницю між кількістю різних дослідів і кількістю констант, які знайдено завдяки цим дослідам незалежно один від одного.
Таблиця 6.1
Ступені вільності
| Джерела варіації | Кількість ступенів вільності | Сума квадратів |
Зумовлене регресією 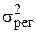
| m | 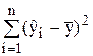
|
Не пояснюване за допомогою регресії 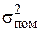
| n - m - 1 | 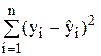
|
Загальне 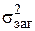
| n - 1 | 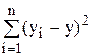
|
|
|
|
6.5.2. Поняття F критерію Фішера
Адекватність простої лінійної регресії можна перевірити за допомогою коефіцієнта детермінації. Якщо , то можна вважати, що модель адекватна, якщо , то модель неадекватна, тобто немає лінійного зв'язку між змінними x та y. В багатьох випадках не можна зробити однозначний висновок про щільність зв'язку (наприклад, при R2 = 0,5 0,6…). Однозначно може дати відповідь про адекватність моделі може критерій Фішера (F-критерій). Перевірка моделі на адекватність за F-критерієм складається з певних етапів:
1) Розрахуємо величину F:
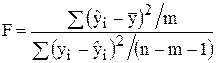 (6.9)
(6.9)
де m – кількість незалежних змінних;
n - кількість спостережень.
2) задаємо рівень значимості α. Наприклад, якщо ми вважаємо що можлива помилка становить α = 0,05 (5%), це означає, що можна помилитись не більше, ніж у 5% випадків, а у 95% випадків наші висновки будуть правильні;
3) за статистичними таблицями F-розподілу з m та (n-m-1) ступенями вільності при рівні ймовірності 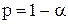 знаходимо значення Fтаб.
знаходимо значення Fтаб.
4) якщо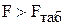 , то побудована регресійна модель адекватна статистичним даним генеральної сукупності.
, то побудована регресійна модель адекватна статистичним даним генеральної сукупності.
6.5.3. Значущість коефіцієнта кореляції і детермінації.
Коефіцієнт кореляції, визначений за вибірковими даними, є точковою оцінкою загального коефіцієнта кореляції, і в свою чергу є випадковою величиною. Отже, значущість коефіцієнта кореляції потребує перевірки. Ця перевірка базується на критерії Стьюдента (t критерій).
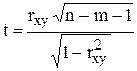 (6.10)
(6.10)
де 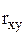 – коефіцієнт кореляції.
– коефіцієнт кореляції.
Для заданого рівняння ймовірності та n-m-1 ступенями вільності знаходять табличне значення t - статистики.
Якщо |t|>tтабл, то можна зробити висновок про значущість коефіцієнта кореляції між залежною і незалежною змінними моделі. (тобто про наявність залежності між змінними X та Y).
Запишемо альтернативну формулу для F- критерію:
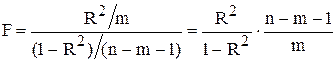 (6.11)
(6.11)
Згідно з цим критерієм можна перевірити значущість коефіцієнта детермінації для моделі загалом.
6.5.4. Перевірка значущості оцінок економетричної моделі та надійні інтервали
Перевіримо значущість аі згідно з t – критерієм:
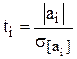 (6.12)
(6.12)
Обчислення значення t- критерію порівнюється з табличним при вибраному рівні ймовірності і n-m-1 ступенях вільності.
Якщо ti > tтабл, то відповідна оцінка параметра ai економетричної моделі є достовірною, тобто відповідний параметр статистично значущий.
|
|
|
1) стандартне відхилення кутового коефіцієнта a1 і його надійний інтервал
Стандартне (середнє квадратичне) відхилення ai знайдемо за формулою:
 (6.13)
(6.13)
де 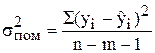 .
.
Якщо припустити, що розкид спостережень відносно лінії регресії розподілений за нормальним законом, то надійні межі для параметра a1 визначають за формулою:
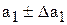 ,
,
де 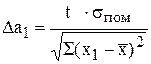 (6.14)
(6.14)
t – значення t - статистики, яке визначається за статистичними таблицями при заданій ймовірності і n-m-1 ступенями вільності.
2) стандартне відхилення a0 і його надійний інтервал
Стандартне відхилення a0 можна знайти за формулою:
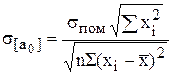 (6.15)
(6.15)
Надійні межі для a0 визначають за формулою:
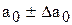 ,
,
де 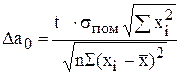 (6.16)
(6.16)
3) надійні інтервали регресії
Надійні інтервали базисних середніх значень 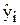 можна знайти за формулою:
можна знайти за формулою:
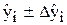 ,
,
де 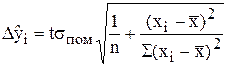 (6.17)
(6.17)
Сполучаючи неперервною лінією на графіку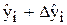 та
та 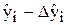 отримаємо надійну зону для базових даних. Графічно:
отримаємо надійну зону для базових даних. Графічно:
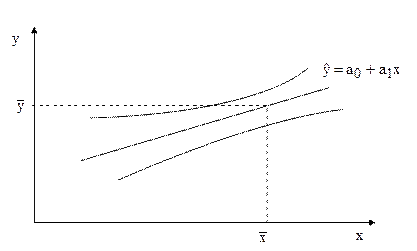
Рис. 6.3. Надійна зона для регресії 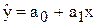
Зазначимо, що найкращі припущення із заданою ймовірністю слід очікувати в околі точки 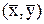 . Надійна зона збільшується при віддаленні хі від значення
. Надійна зона збільшується при віддаленні хі від значення 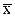 .
.

6.5.5. Прогноз за моделями просторової регресії.
Прогнозування – наукове передбачення ймовірності шляхів розвитку явищ та процесів.
Періодом упередження називається проміжок часу від моменту, ля якого є останні статистичні дані про досліджуваний об’єкт, до моменту, до якого належить прогноз.
Прогнозування показника отримаємо підстановкою a1 у знайдене рівняння в запланованих значеннях фактора:
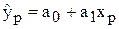 (6.18)
(6.18)
Знайдемо надійні межі прогнозу. Надійні інтервали (інтервали довіри) - це інтервали, у які з певною заданою ймовірністю потрапляє дійсне значення показника.
Запишемо межі надійних інтервалів індивідуальних прогнозованих значень:
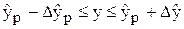 , (6.19)
, (6.19)
де 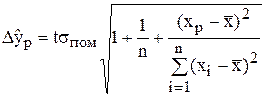 (6.20)
(6.20)
t2 - значення t - статистики Стьюдента, яка визначається за статистичними таблицями за даним рівнем ймовірності p=1-α і n-m-1 ступенями вільності.
 – середнє квадратичне відхилення залишків
– середнє квадратичне відхилення залишків
хp - прогнозне значення фактора.
6.6. Спряжені регресії
|
|
|
Серед економічних задач зустрічаються такі явища коли одна і та ж величина може бути як показником так і фактором. Парні регресії, у яких одна і та ж величина може бути показником, так і фактором, називаються логічно оберненими регресіями або спряженими регресіями. Прикладом спряженої регресії може бути залежність між обсягом виробництва та коефіцієнтом використання основних засобів. З одного боку можна розглянути залежність між обсягом виробництва та коефіцієнтом використання основних засобів, з іншого – залежність використання основних засобів від обсягу виробництва.
Припустимо, що між величинами економічних явищ х та у існує лінійна залежність і для тих можна побудувати спряжені регресії:
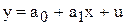 (6.21)
(6.21)
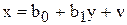 (6.22)
(6.22)
Припустимо, що прямі регресій (6.21) і (6.22) не співпадають. Використаємо МНК для оцінки параметрів a0, a1, b0, b1. Отримаємо:
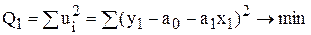
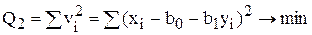
Після знаходження частини похідних по невідомих параметрах і прирівнявши їх до нуля, отримаємо систему нормальних рівнянь.
Наведемо графічну інтерпретацію спряжених регресій:
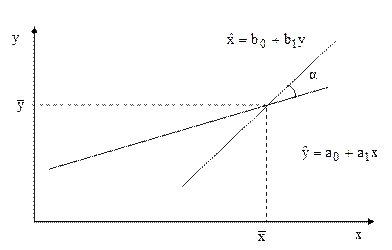
Рис. 6.4. Спряжені регресії
Спряжені регресії мають такі властивості:
- якщо взаємозв'язок змінних х та у відсутній, то регресії є перпендикулярними прямими;
- якщо взаємозв’язок змінних є функціональним, обидві лінії регресії зливаються в одну і всі точки спостережень лежать на одній прямій;
- якщо взаємозв'язок змінних є кореляцією, то лінії перетинаються в точці (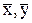 ) утворюють при цьому кут гострий кут α. При тісному зв'язку α – менший, при слабкому – кут α значний.
) утворюють при цьому кут гострий кут α. При тісному зв'язку α – менший, при слабкому – кут α значний.
Тіснота зв'язку між спряженими регресіями характеризується одним і тим самим коефіцієнтом кореляції.
Якщо відомі оцінки параметрів моделей (6.21) і (6.22) то коефіцієнти кореляції можна визначити як середні геометричних параметрів а1 і b1:
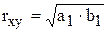 (6.23)
(6.23)
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 2832; Нарушение авторских прав?; Мы поможем в написании вашей работы!