КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Экспериментальные результаты
Комбинированный алгоритм, использующий обратное распространение и обучение Коши, применялся для обучения нескольких больших сетей. Например, этим методом была успешно обучена система, распознающая рукописные китайские иероглифы. Все же время обучения оказалось отнюдь не маленьким (было потрачено приблизительно 36 часов машинного времени).
В другом эксперименте эта сеть обучалась на задаче ИСКЛЮЧАЮЩЕЕ ИЛИ, которая была использована в качестве теста для сравнения с другими алгоритмами. Для сходимости сети в среднем требовалось около 76 предъявлений обучающего множества. В качестве сравнения можно указать, что при использовании обратного распространения в среднем требовалось около 245 предъявлений для решения этой же задачи и 4986 итераций при использовании обратного распространения второго порядка.
Ни одно из обучений не привело к локальному минимуму. Более того, ни одно из 160 обучений не обнаружило неожиданных патологий, сеть всегда правильно обучалась.
Эксперименты же с чистой машиной Коши потребовали значительно большх времен обучения. Например, при 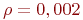 для обучения сети в среднем требовалось около 2284 предъявлений обучающего множества.
для обучения сети в среднем требовалось около 2284 предъявлений обучающего множества.
Несмотря на такие обнадеживающие результаты, метод еще не исследован до конца, особенно на больших задачах. Значительно большая работа потребуется для определения его достоинств и недостатков.
44. Генетические алгоритмы.
http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BD%D0%B5%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC
http://habrahabr.ru/post/128704/
http://mathmod.aspu.ru/images/File/ebooks/GAfinal.pdf
http://www.math.nsc.ru/AP/benchmarks/UFLP/uflp_ga.html
Генетические алгоритмы
Идея генетических алгоритмов заимствована у живой природы и состоит в организации эволюционного процесса, конечной целью которого является получение оптимального решения в сложной комбинаторной задаче. Разработчик генетических алгоритмов выступает в данном случае как "создатель", который должен правильно установить законы эволюции, чтобы достичь желаемой цели как можно быстрее. Впервые эти нестандартные идеи были применены к решению оптимизационных задач в середине 70-х годов [7, 12]. Примерно через десять лет появились первые теоретические обоснования этого подхода [16, 21, 22]. На сегодняшний день генетические алгоритмы доказали свою конкурентноспособность при решении многих NP-трудных задач [6, 15] и особенно в практических приложениях, где математические модели имеют сложную структуру и применение стандартных методов типа ветвей и границ, динамического или линейного программирования крайне затруднено.
Ежегодно в мире проводится несколько конференций по этой тематике, информацию о которых можно найти в Интернет по адресам:
http://www.natural-selection.com/eps/
http://mat.gsia.cmu.edu/Conferences/.
Общую схему генетических алгоритмов проще всего понять, рассматривая задачи безусловной оптимизации
max { f (i) | i 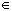 {0,1} n }.
{0,1} n }.
Примерами служат задачи размещения, стандартизации, выполнимости и другие [2, 5, 19]. Стандартный генетический алгоритм начинает свою работу с формирования начальной популяции I 0 = { i 1, i 2, …, is } — конечного набора допустимых решений задачи. Эти решения могут быть выбраны случайным образом или получены с помощью вероятностных жадных алгоритмов [1, 3, 4]. Как мы увидим ниже, выбор начальной популяции не имеет значения для сходимости процесса в асимптотике, однако формирование "хорошей" начальной популяции (например из множества локальных оптимумов) может заметно сократить время достижения глобального оптимума.
На каждом шаге эволюции с помощью вероятностного оператора селекции выбираются два решения, родители i 1, i 2. Оператор скрещивания по решениям i 1, i 2 строит новое решение i', которое затем подвергается небольшим случайным модификациям, которые принято называть мутациями. Затем решение добавляется в популяцию, а решение с наименьшим значением целевой функции удаляется из популяции. Общая схема такого алгоритма может быть записана следующим образом.
|
|
Дата добавления: 2014-01-04; Просмотров: 238; Нарушение авторских прав?; Мы поможем в написании вашей работы!