КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм FIFO
|
|
|
|
Сокети
Канали
Канал – це найпростіший засіб передавання повідомлень. Він є циклічним буфером, записування у який виконують за допомогою одного процесу, а читання – за допомогою іншого. У конкретний момент часу до каналу має доступ тільки один процес. Операційна система забезпечує синхронізацію згідно правилу: якщо процес намагається записувати в канал, у якому немає місця, або намагається зчитувати більше даних, ніж поміщено в канал, він переходить у стан очікування.
Розрізняють безіменні та поіменовані канали.
До безіменних каналів немає доступу за допомогою засобів іменування, тому процес не може відкрити вже наявний безіменний канал без його дескриптора. Це означає, що такий процес має отримати дескриптор каналу від процесу, що його створив, а це можливо тільки для зв’язаних процесів.
До поіменованих каналів (named pipes) є доступ за іменем. Такому каналу може відповідати, наприклад, файл у файловій системі, при цьому будь-який процес, який має доступ до цього файлу, може обмінюватися даними через відповідний канал. Поіменовані канали реалізують непрямий обмін даними.
Обмін даними між каналами може бути однобічним і двобічним.
Черги повідомлень
Іншою технологією асинхронного непрямого обміну даними є застосування черг повідомлень (message queues). Для таких черг виділяють спеціальне місце в системній пам’яті ОС, доступне для застосувань користувача. Процеси можуть створювати нові черги, відсилати повідомлення в конкретну чергу й отримувати їх звідти. Із чергою одночасно може працювати кілька процесів. Повідомлення – це структури даних змінної довжини. Для того щоб процеси могли розрізняти адресовані їм повідомлення, кожному з них присвоюють тип. Відіслане повідомлення залишається в черзі доти, поки не буде зчитане. Синхронізація під час роботи з чергами схожа на синхронізацію для каналів.
|
|
|
Найрозповсюдженим методом обміну повідомленнями є використання сокетів (sockets). Ця технологія насамперед призначена для організації мережного обміну даними, але може бути використана й для взаємодії між процесами на одному комп’ютері (власне, мережну взаємодію можна розуміти як узагальнення IPC).
Сокет – це абстрактна кінцева точка з’єднання, через яку процес може відсилати або отримувати повідомлення. Обмін даними між двома процесами здійснюють через пару сокетів, по одному на кожен процес. Абстрактність сокету полягає в тому, що він приховує особливості реалізації передавання повідомлень – після того як сокет створений, робота з ним не залежить від технології передавання даних, тому один і той самий код можна без великих змін використовувати для роботи із різними протоколами зв’язку.
Особливості протоколу передавання даних і формування адреси сокету визначає комунікаційний домен; йому потрібно зазначити під час створення кожного сокету. Прикладами доменів можуть бути домен Інтернету (який задає протокол зв’язку на базі TCP/IP) і локальний домен або домен UNIX, що реалізує зв’язок із використанням імені файлу (подібно до поіменованого каналу). Сокет можна використовувати у поєднанні тільки з одним комунікаційним доменом. Адреса сокету залежить від домену (наприклад, для сокетів домену UNIX такою адресою буде ім’я файлу).
Способи передавання даних через сокет визначаються його типом. У конкретному домені можуть підтримуватися або не підтримуватися різні типи сокетів. Наприклад, і для домену Інтернету, і для домену UNIX підтримуються сокети таких типів:
· потокові (stream sockets) – задають надійний двобічний обмін даними суцільним потоком без виділення меж (операція читання даних повертає стільки даних, скільки запитано або скільки було на цей момент передано);
|
|
|
· дейтаграмні (datagram sockets) – задають ненадійний двобічний обмін повідомлення із виділенням меж (операція читання даних повертає розмір того повідомлення, яке було відіслано).
Під час обміну даними із використанням сокетів зазвичай застосовується технологія клієнт-сервер, коли один процес (сервер) очікує з’єднання, а інший (клієнт) з’єднують із ним.
Перед тим як почати працювати з сокетами, будь-який процес (і клієнт, і сервер) має створити сокет за допомогою системного виклику socket(). Параметрами цього виклику задають комунікаційний домен і тип сокету. Цей виклик повертає дескриптор сокету – унікальне значення, за яким можна буде звертатися до цього сокету.
Подальші дії відрізняються для сервера і клієнта. Спочатку розглянемо послідовність кроків, яку потрібно виконати для сервера.
1. Сокет пов’язують з адресою за допомогою системного виклику bind(). Для сокетів домену UNIX як адресу задають ім’я файлу, для сокетів домену Інтернету – необхідні характеристики мережного з’єднання. Далі клієнт для встановлення з’єднання й обміну повідомленнями має буде вказати цю адресу.
2. Сервер дає змогу клієнтам встановлювати з’єднання, виконавши системний виклик listen() для дескриптора сокету, створеного раніше.
3. Після виходу із системного виклику listen() сервер готовий приймати від клієнтів запити на з’єднання. Ці запити вишиковуються в чергу. Для отримання запиту із цієї черги і створення з’єднання використовують системний виклик accept(). Внаслідок його виконання в застосування повертають новий сокет для обміну даними із клієнтом. Старий сокет можна використовувати далі для приймання нових запитів для з’єднання. Якщо під час виклику accept() запити на з’єднання в черзі відсутні, сервер переходить у стан очікування.
Для клієнта послідовність дій після створення сокету зовсім інша. Замість трьох кроків досить виконати один – встановлення з’єднання із використанням системного виклику connect(). Параметрами цього виклику задають дескриптор створеного раніше сокету, а також адресу, подібну до вказаної на сервері для виклику bind().
|
|
|
Після встановлення з’єднання (і на клієнті, і на сервері) з’явиться можливість передавати і приймати дані з використанням цього з’єднання. Для передавання даних застосовують системний виклик send(), а для приймання – recv().
Зазначену послідовність кроків використовують для встановлення надійного з’єднання. Якщо все, що нам потрібно – це відіслати і прийняти конкретне повідомлення фіксованої довжини, то з’єднання можна й не створювати зовсім. Для цього як відправник, так і одержувач повідомлення мають попередньо зв’язати сокети з адресами через виклик bind(). Потім можна скористатися викликами прямого передавання даних: sendto() – для відправника і recvfrom() – для одержувача. Параметрами цих викликів задають адреси одержувача і відправника, а також адреси буферів для даних.
Віддалений виклик процедур
Технологія віддаленого виклику процедур (Remote Procedure Call, RPC) є прикладом синхронного обміну повідомленнями із підтвердженням отримання.
Розглянемо послідовну кроків, необхідних для обміну даними в цьому разі.
1. Операцію send оформлюють як виклик процедури із параметрами.
2. Після виклику такої процедури відправник переходить у стан очікування, а дані (ім’я процедури і параметри) доставляються одержувачеві. Одержувач може перебувати на тому самому комп’ютері, чи на віддаленій машині; технологія RPC приховує це. Класичний віддалений виклик процедур передбачає, що процес-одержувач створено внаслідок запиту.
3. Одержувач виконує операцію receive і на підставі даних, що надійшли, виконує відповідні дії (викликає локальну процедуру за іменем, передає їй параметри і обчислює результат).
4. Обчислений результат повертають відправникові як окреме повідомлення.
5. Після отримання цього повідомлення відправник продовжує своє виконання, розглядаючи обчислений результат як наслідок виклику процедури.
Розділ 8
Керування оперативною пам’яттю
Під пам’яттю розумітимемо ресурс комп’ютера, призначений для зберігання програмного коду і даних. Пам’ять зображають як масив машинних слів або байтів з їхніми адресами. У фон-нейманівській архітектурі комп’ютерних систем процесор вибирає інструкції і дані з пам’яті та може зберігати в ній результати виконання операцій.
|
|
|
Різні види пам’яті організовані в ієрархію. На нижніх рівнях такої ієрархії перебуває дешевша і повільніша пам’ять більшого обсягу, а в міру просування ієрархією нагору пам’ять стає дорожчою і швидшою (а її обсяг стає меншим). Найдешевшим і найповільнішим запам’ятовуючим пристроєм є жорсткий диск комп’ютера. Його називають також допоміжним запам’ятовуючим пристроєм (secondary storage). Швидшою й дорожчою є оперативна пам’ять, що зберігається в мікросхемах пам’яті, встановлених на комп’ютері, - таку пам’ять називатимемо основною пам’яттю (main memory). Ще швидшими засобами зберігання даних є різні кеші процесора, а обсяг цих кешів ще обмеженіший.
Керування пам’яттю в ОС – досить складне завдання. Потрібної за характеристиками пам’яті часто виявляється недостатньо, і щоб це не заважало роботі користувача, необхідно реалізовувати засоби координації різних видів пам’яті. Так, сучасні застосування можуть не вміщатися цілком в основній пам’яті, тоді невикористовуваний код застосування може тимчасово зберігатися на жорсткому диску.
8.1. Основи технології віртуальної пам’яті
Спочатку розглянемо передумови введення концепції віртуальної пам’яті. Наведемо найпростіший з можливих способів спільного використання фізичної пам’яті кількома процесами (рис. 8.1).
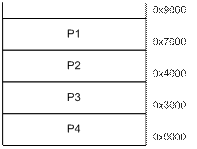
Рис. 8.1. Спільне використання фізичної пам’яті процесами
За цієї ситуації кожний процес завантажують у свою власну неперервну ділянку фізичної пам’яті, ділянка наступного процесу починається відразу після ділянки попереднього. На рис. 8.1 праворуч позначені адреси фізичної пам’яті, починаючи з яких завантажуються процеси.
Якщо проаналізувати особливості розподілу пам’яті на основі цього підходу, можуть виникнути такі запитання.
· Як виконувати процеси, котрим потрібно більше фізичної пам’яті, ніж встановлено на комп’ютері?
· Що відбудеться, коли процес виконає операцію записування за невірною адресою (наприклад, процес Р2 – за адресою 0х7500)?
· Що робити, коли процесу (наприклад, процесу Р1) буде потрібна додаткова пам’ять під час його виконання?
· Коли процес отримає інформацію про конкретну адресу фізичної пам’яті, що з неї розпочнеться його виконання, і як мають бути перетворені адреси пам’яті, використані в його коді?
· Що робити, коли процесу не потрібна вся пам’ять, видалена для нього?
Пряме завантаження процесів у фізичну пам’ять не дає змогу дати відповіді на ці запитання. Очевидно, що потрібно деякі засоби трансляції пам’яті, які давали б змогу процесам використовувати набори адрес, котрі відрізняються від адрес фізичної пам’яті. Перш ніж розібратися в особливостях цих адрес, коротко зупинимося на особливостях компонування і завантаження програм.
Програма зазвичай перебуває на диску у вигляді двійкового виконуваного файлу, отриманого після компіляції та компонування. Для свого виконання вона має бути завантажена у пам’ять (адресний простір процесу). Сучасні архітектури дають змогу процесам розташовуватися у будь-якому місці фізичної пам’яті, при цьому одна й та сама програма може відповідати різним процесам, завантаженим у різні ділянки пам’яті. Заздалегідь невідомо, в яку ділянку пам’яті буде завантажена програма.
Під час виконання процес звертається до різних адрес, зокрема в разі виклику функції використовують її адресу (це адреса коду), а звертання до глобальної змінної відбувається за адресою пам’яті, призначеною для зберігання значення цієї змінної (це адреса даних).
Програміст у своїй програмі звичайно не використовує адреси пам’яті безпосередньо, замість них вживають символічні імена (функцій, глобальних змінних тощо). Внаслідок компіляції та компонування ці імена прив’язують до переміщуваних адрес (такі адреси задають у відносних одиницях, наприклад «100 байт від початку модуля»). Під час виконання програми переміщувані адреси, своєю чергою, прив’язують до абсолютних адрес у пам’яті. По суті, кожна прив’язка – це відображення одного набору адрес на інший.
До адрес, використовуваних у програмах, ставляться такі вимоги.
· Захист пам’яті. Помилки в адресації, що трапляються в коді процесу, повинні впливати тільки на виконання цього процесу. Коли процес Р2 зробить операцію записування за адресою 0х7500, то він і має бути перерваний за помилкою. Стратегія захисту пам’яті зводиться до того, що для кожного процесу зберігається діапазон коректних адрес, і кожна операція доступу до пам’яті перевіряється на приналежність адреси цьому діапазону.
· Відсутність прив’язання до адрес фізичної пам’яті. Процес має можливість виконуватися незалежно від його місця в пам’яті та від розміру фізичної пам’яті. Адресний простір процесу виділяється як великий статичний набір адрес, при цьому кожна адреса такого набору є переміщуваною. Процесор і апаратне забезпечення повинні мати змогу перетворювати такі адреси у фізичні адреси основної пам’яті (при цьому одна й та сама переміщувана адреса в різний час або для різних процесів може відповідати різним фізичним адресам).
8.1.1. Поняття віртуальної пам’яті
Віртуальна пам’ять – це технологія, в якій вводиться рівень додаткових перетворень між адресами пам’яті, використовуваних процесом, і адресами фізичної пам’яті комп’ютера. Такі перетворення мають забезпечувати захист пам’яті та відсутність прив’язування процесу до адрес фізичної пам’яті.
Завдяки віртуальній пам’яті фізична пам’ять адресного простору процесу може бути фрагментованою, оскільки основний обсяг пам’яті, яку займає процес, більшу частину часу залишається вільним. Є так зване правило «дев’яносто до десяти», або правило локалізації, яке стверджує, що 90% звертань до пам’яті у процесі припадає на 10% його адресного простору. Адреси можна переміщати так, щоб основній пам’яті відповідали тільки ті розділи адресного простору процесу, які справді використовуються у конкретний момент.
При цьому невикористовувані розділи адресного простору можна ставити у відповідність повільнішій пам’яті, наприклад простору на жорсткому диску, а в цей час інші процеси можуть використовувати основну пам’ять, у яку раніше відображалися адреси цих розділів. Коли ж розділ знадобиться, його дані завантажують з диска в основну пам’ять, можливо, замість розділів, які стали непотрібними в конкретний момент (і які, своєю чергою, тепер збережуться на диску). Дані можуть зчитуватися з диска в основну пам’ять під час звертання до них.
У такий спосіб можна значно збільшити розмір адресного простору процесу і забезпечити виконання процесів, що за розміром перевищують основну пам’ять.
8.1.2. Проблеми реалізації віртуальної пам’яті. Фрагментація пам’яті
Основна проблема, що виникає у разі використання віртуальної пам’яті, стосується ефективності її реалізації. Оскілки перетворення адрес необхідно робити під час кожного звертання до пам’яті, недбала реалізація цього перетворення може призвести до найгірших наслідків для продуктивності всієї системи. Якщо для більшості звертань до пам’яті система буде змушена насправді звертатися до диска (який у десятки тисяч разів повільніший, ніж основна пам’ять0, працювати із такою системою стане практично неможливо.
Ще однією проблемою є фрагментація пам’яті, що виникає за ситуації, коли неможливо використати вільну пам’ять. Розрізняють зовнішню і внутрішню фрагментацію пам’яті (рис. 8.2).

Рис. 8.2. Зовнішня і внутрішня фрагментація
Зовнішня зводиться до того, що внаслідок виділення і наступного звільнення пам’яті в ній утворюються вільні блоки малого розміру – діри (holes). Через це може виникнути ситуація, за якої неможливо виділити неперервний блок пам’яті розміру N, оскільки немає жодного неперервного вільного блоку, розмір якого S³N, хоча загалом обсяг вільного простору пам’яті перевищує N. Так, на рис. 8.2 для виконання процесу Р5 місця через зовнішню фрагментацію не вистачає.
Внутрішня фрагментація зводиться до того, що за запитом виділяють блоки пам’яті більшого розміру, ніж насправді будуть використовуватися, у результаті всередині виділених блоків залишаються невикористовувані ділянки, які вже не можуть бути призначені для чогось іншого.
8.1.3. Логічна і фізична адресація пам’яті
Найважливішими поняттями концепції віртуальної пам’яті є логічна і фізична адресація пам’яті.
Логічна або віртуальна адреса – адреса, яку генерує програми, запущена на деякому процесорі. Адреси, що використовують інструкції конкретного процесора, є логічними адресами. Сукупність логічних адрес становить логічний адресний простір.
Фізична адреса – адреса, якою оперує мікросхема пам’яті. Прикладна програма в сучасних комп’ютерах ніколи не має справи з фізичними адресами. Спеціальний апаратний пристрій MMU (memory management unit – пристрій керування пам’яттю) відповідає за перетворення логічних адрес у фізичні. Сукупність усіх доступних фізичних адрес становить фізичний адресний простір. Отже, якщо в комп’ютері є мікросхеми на 128 Мбайт пам’яті, то саме такий обсяг адресують фізично. Логічно зазвичай адресують значно більше пам’яті.
Найпростіша схема перетворення адрес зображена на рис. 8.3.

Рис. 8.3. Перетворення логічних адрес пам’яті у фізичні адреси
Специфіку перетворення логічних адрес у фізичні визначають різні підходи до керування оперативною пам’яттю.
8.1.4. Підхід базового та межового регістрів
Під час реалізації віртуальної пам’яті необхідно забезпечити захист пам’яті, переміщення процесів у пам’яті та спільне використання пам’яті кількома процесами.
Одним з найпростіших способів задовольнити ці вимоги є підхід базового та межового регістрів. Для кожного процесу в двох регістрах процесора зберігають два значення – базової адреси (base) і межі (bounds). Кожний доступ до логічної адреси апаратно перетворюються у фізичну адресу шляхом додавання логічної адреси до базової. Якщо отримувана фізична адреса не потрапляє в діапазон (base, base+bounds), вважають, що адреса невірна, і генерують помилку (рис. 8.4).
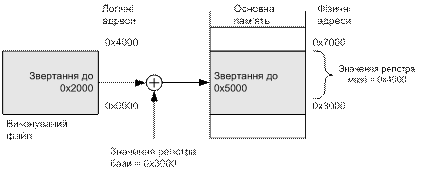
Рис. 8.4. Використання базового і межового регістрів
Такий підхід є найпростішим прикладом реалізації динамічного переміщення процесів у пам’яті. Усі інші підходи є різними варіантами розвитку цієї схеми. Наприклад, те, що кожний процес у разі використання цього підходу має свої власні значення базового і межового регістрів, є найпростішою реалізацією концепції адресного простору процесу, яка ґрунтується на тому, що кожний процес має власне відображення пам’яті.
Для організації захисту пам’яті в цій ситуації необхідно, щоб застосування користувача не могли змінювати значення базового і межового регістрів. Достатньо інструкції такої зміни зробити доступними тільки у привілейованому режимі процесора.
До переваг цього підходу належать простота, скромні вимоги до апаратного забезпечення (потрібні тільки два регістри), висока ефективність. Однак сьогодні його практично не використовують через низку недоліків, пов’язаних насамперед з тим, що адресний простір процесу все одно відображається на один неперервний блок фізичної пам’яті: незрозуміло, як динамічно розширювати адресний простір процесу: різні процеси не можуть спільно використовувати пам’ять; немає розподілу коду і даних.
За такого підходу для процесу виділяють тільки одну пару значень «базова адреса-межа». Природним розвитком цієї ідеї стало відображення адресного простору процесу за допомогою кількох діапазонів фізичної пам’яті, кожен з яких задають власною парою значень базової адреси і межі. Так виникла концепція сегментації пам’яті.
8.2. Сегментація пам’яті
8.2.1. Особливості сегментації пам’яті
Сегментація пам’яті дає змогу зображати логічний простір як сукупність незалежних блоків змінної довжини, які називають сегментами. Кожний сегмент звичайно містить дані одного призначення, наприклад в одному може бути стек, в іншому – програмний код і т.д.
У кожного сегмента є ім’я і довжина (для зручності реалізації поряд з іменами використовують номери). Логічна адреса складається з номера сегмента і зсуву всередині сегмента; з такими адресами працює прикладна програма. Компілятори часто створюють окремі сегменти для різних даних програми (сегмент коду, сегмент даних,сегмент стека). Під час завантаження програми у пам’ять створюють таблицю дескрипторів сегменту процесу, кожний елемент якої відповідає одному сегменту і складається із базової адреси, значення межі та прав доступу.
Під час формування адреси її сегментна частина вказує на відповідний елемент таблиці дескрипторів сегментів процесу. Якщо зсув більший, ніж задане значення межі (або якщо права доступу процесу не відповідають правам, заданим для сегмента), то апаратне забезпечення генерує помилку. Коли ж усе гаразд, сума бази і зсуву в разі чистої сегментації дасть у результаті фізичну адресу в основній пам’яті. У підсумку кожному сегменту відповідає неперервний блок пам’яті такої самої довжини, що перебуває в довільному місці фізичної пам’яті або на диску. Загальний підхід до перетворення адреси у разі сегментації показаний на рис. 8.5.
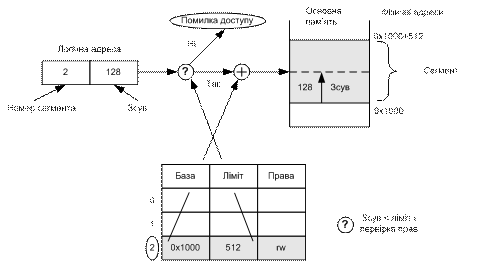
Рис. 8.5. Перетворення адреси у разі сегментації
Загальний вигляд пам’яті у разі сегментації показано на рис. 8.6.
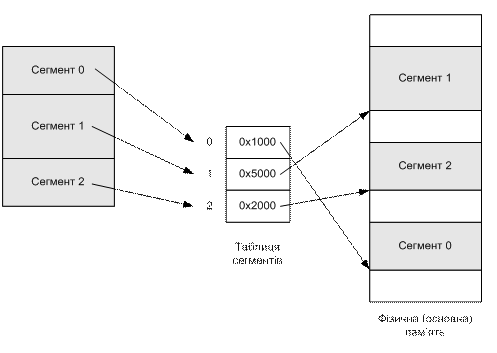
Рис. 8.6. Логічний і фізичний адресний простір у разі сегментації
Наведемо переваги сегментації пам’яті.
· З’явилася можливість організовувати кілька незалежних сегментів пам’яті для процесу і використати їх для зберігання даних різної природи. При цьому права доступу до кожного такого сегмента можуть бути задані по-різному.
· Окремі сегменти можуть спільно використовуватися різними процесами, для цього їхні таблиці дескрипторів сегментів повинні міститися однакові елементи,що описують такий сегмент.
· Фізична пам’ять, що відповідає адресному простору процесу, тепер не обов’язково має бути неперервною. Справді. Сегментація дає змогу окремим частинам адресного простору процесу відображатися не в основну пам’ять, а на диск, і довантажуватися з нього за потребою, забезпечуючи виконання процесів будь-якого розміру.
· Цей підхід не позбавлений і недоліків
· Необхідність введення додаткового рівня перетворення пам’яті спричиняє зниження продуктивності (цей недолік властивий будь-який повноцінній реалізації віртуальної пам’яті). Для ефективної реалізації сегментації потрібна відповідна апаратна підтримка.
· Керування блоками пам’яті змінної довжини з урахуванням необхідності їхнього збереження на диску може бути досить складним.
· Вимога, щоб кожному сегменту відповідав неперервний блок фізичної пам’яті відповідного розміру, спричиняє зовнішню фрагментацію пам’яті. Внутрішньої фрагментації в цьому разі не виникає, оскільки сегменти мають змінну довжину і завжди можна виділити сегмент довжини, необхідної для виконання програми.
Сьогодні сегментацію застосовують доволі обмежено передусім через фрагментацію і складність реалізації ефективного звільнення пам’яті та обміну із диском. Ширше використання отримав розподіл пам’яті на блоки фіксованої довжини – сторінкова організація пам’яті.
8.2.2. Реалізація сегментації в архітектурі IA-32
В архітектурі IA-32 логічні адреси в програмі формуються із використанням сегментації й мають такий вигляд: «селектор-зсув». Значення селектора завантажують у спеціальний регістр процесора (сегментний регістр) і використовують як індекс у таблиці дескрипторів сегментів, що перебуває в пам’яті та є аналогом таблиці сегментів, описаної раніше. В архітектурі IA-32 підтримуються шість сегментних регістрів. Це означає, що виконуваний код в один і той самий час може адресувати шість незалежних сегментів.
Селектор містить індекс дескриптора в таблиці, біт індикатора локальної або глобальної таблиці та необхідний рівень привілеїв.
Для системи задають спільну глобальну таблицю дескрипторів (Global Description Table, GDT), а для кожної задачі – локальну таблицю дескрипторів (Local Description Table, LDT).
Дескриптори в IA-32 мають довжину 64 біти. Вони визначають властивості програмних об’єктів (наприклад, сегментів пам’яті або таблиць дескрипторів).
Дескриптор містить значення бази (base), яке відповідає адресі об’єкта (наприклад, початок сегмента); значення межі (limit); тип об’єкта (сегмент, таблиця дескрипторів тощо); характеристики захисту.
Звертання до таблиць дескрипторів підтримується апаратно. Якщо задані в дескрипторі характеристики захисту не відповідають рівню привілеїв, визначеному селектором, отримати доступ до пам’яті за його допомогою буде неможливо. Так забезпечують захист пам’яті.
Проте жодного разу не було згадано, що в дескрипторі зберігають фізичну адресу. Річ у тому, що для архітектури IA-32 внаслідок перетворення логічної адреси отримують не фізичну адресу, а ще один вид адреси, який називають лінійною адресою.
8.3. Сторінкова організація пам’яті
До основних технологій віртуальної пам’яті крім сегментації належить сторінкова організація пам’яті (paging). Її головна ідея – розподіл пам’яті блоками фіксованої довжини. Такі блоки називають сторінками.
Ця технологія є найпоширенішим підходом до реалізації віртуальної пам’яті в сучасних операційних системах.
8.3.1. Базові принципи сторінкової організації пам’яті
У разі сторінкової організації пам’яті логічну адресу називають також лінійною, або віртуальною, адресою. Такі адреси належать одній множині (наприклад, лінійною адресою може бути невід’ємне ціле число довжиною 32 біти).
Фізичну пам’ять розбивають на блоки фіксованої довжини – фрейми, або сторінкові блоки (frames). Логічну пам’ять, у свою чергу,розбивають на блоки такої самої довжини – сторінки (pages). Коли процес починає виконуватися, його сторінки завантажуються в доступні фрейми фізичної пам’яті з диска або іншого носія.
Сторінкова організація пам’яті повинна мати апаратну підтримку. Кожна адреса, яку генерує процесор, ділиться на дві частини: номер сторінки і зсув сторінки. Номер сторінки використовують як індекс у таблиці сторінок.
Таблиця сторінок – це структура даних, що містить набір елементів (page-table entries, PTE), кожен із яких містить інформацію про номер сторінки, номер відповідного їй фрейму фізичної пам’яті (або безпосередньо його базову адресу) та права доступу. Номер сторінки використовують як для пошуку елемента в таблиці. Після його знаходження до базової адреси відповідного фрейму додають зсув сторінки, чим і визначають фізичну адресу (рис. 8.7).
Розмір сторінки є ступенем числа 2, у сучасних ОС використовують сторінки розміром від 2 до 8 Кбайт. У спеціальних режимах адресації можна працювати зі сторінками більшого розміру.
Для кожного процесу створюють його власну таблицю сторінок. Коли процес починає своє виконання, ОС розраховує його розмір у сторінках і кількість фреймів у фізичній пам’яті. Кожну сторінку завантажують у відповідний фрейм, після чого його номер записують у таблицю сторінок процесу.
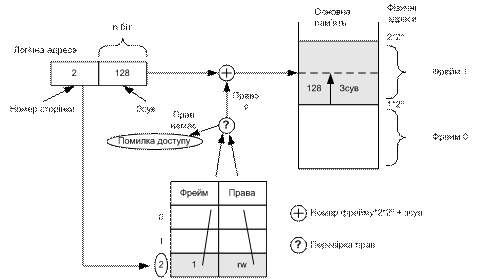
Рис. 8.7. Перетворення адреси у разі сторінкової організації пам’яті
Відображення логічної пам’яті для процесу відрізняється від реального стану фізичної пам’яті. На логічному рівні для процесу вся пам’ять зображується неперервним блоком і належить тільки цьому процесові, а фізично вона розосереджується по адресному простору мікросхеми пам’яті, чергуючись із пам’яттю інших процесів (рис. 8.8). Процес не може звернутися до пам’яті, адреса якої не вказана в його таблиці сторінок (так реалізований захист пам’яті).
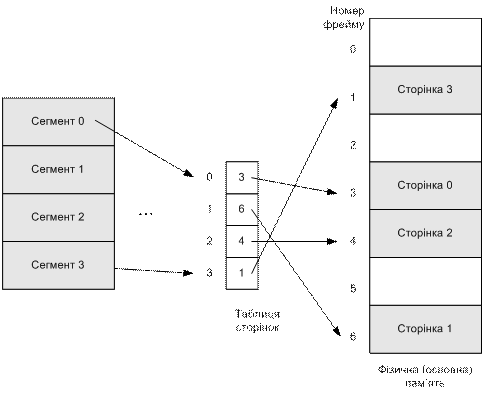
Рис. 8.8. Логічний і фізичний адресний простір у разі сторінкової організації пам’яті
ОС повинна мати інформацію про поточний стан фізичної пам’яті (про зайнятість і незайнятість фреймів, їхню кількість тощо). Цю інформацію звичайно зберігають у таблиці фреймів. Кожний її елемент відповідає фрейму і містить всі відомості про нього.
8.3.2. Порівняльний аналіз сторінкової організації пам’яті та сегментації
Сторінкова організація пам’яті та сегментація мають більше спільних рис, аніж відмінностей. Основна відмінність між цими двома підходами полягає в тому, що всі сторінки мають фіксовану довжину, а сегменти – змінну. Інші базові моменти (відсутність вимоги неперервності фізичної пам’яті, можливість вивантаження блоків пам’яті на диск, необхідність підтримувати таблиці перетворення тощо) принципово не відрізняються.
Розглянемо основні переваги сторінкової організації пам’яті порівняно із сегментацією. Вони визначаються насамперед тим, що всі сторінки мають одну й ту саму довжину.
· Реалізація розподілу і звільнення пам’яті спрощується. Усі сторінки з погляду процесу рівноправні, тому можна підтримувати список вільних сторінок і в разі необхідності виділяти першу сторінку із цього списку, а після звільнення повертати сторінку в список. Із сегментами так чинити не можна, оскільки кожен сегмент можна використати лише за його призначенням (спроба використати сегмент для іншої мети призведе швидше за все до того, що виникне потреба у сегменті іншої довжини).
· Реалізація обміну даними з диском також спрощується. Для організації такого обміну ділянка на диску, яку використовують для зберігання інформації про сторінки, вивантажені з пам’яті (простір підтримки, backing store) може бути теж розбита на блоки фіксованого розміру, рівного розмірові фрейму.
Сторінкова організація пам’яті не позбавлена й недоліків.
· Насамперед цей підхід спричиняє внутрішню фрагментацію, пов’язану з тим, що розмір сторінки завжди фіксований, і в разі необхідності виділення блоку пам’яті конкретної довжини його розмір буде кратним розміру сторінки. У середньому розмір не використовуваної пам’яті становить приблизно половину сторінки для кожного виділеного блоку пам’яті (аналогічно до сегмента). Така фрагментація може бути знижена зменшенням кількості та збільшення розміру блоків, що виділяються.
· Таблиці сторінок мають бути більші за розміром, ніж таблиці сегментів. Так, для виділення неперервного діапазону пам’яті розміром 100 Кбайт знадобиться один елемент таблиці сегментів, що описує сегмент, виділений для цього діапазону. З іншого боку, у разі використання сторінок розміром 4 Кбайт для опису такого діапазону нам знадобиться 25 елементів таблиці сторінок – по одному елементу для кожної сторінки.
8.3.3. Багаторівневі таблиці сторінок
Щоб адресувати логічний адресний простір значного обсягу за допомогою однієї таблиці сторінок, її доводиться робити дуже великою. Наприклад, в архітектурі IA-32 за стандартного розміру сторінки 4 Кбайт (для адресації всередині такої сторінки потрібні 12 біт) на індекс у таблиці залишається 20 біт, що відповідає таблиці сторінок на 1 мільйон елементів.
Щоб уникнути таких великих таблиць, запропоновано технологію б агаторівневих таблиць сторінок. Таблиці сторінок самі розбиваються на сторінки, інформацію про які зберігають в таблиці сторінок верхнього рівня. Кількість рівнів рідко перевищує 2, але може доходити й до 4.
Коли є два рівні таблиць, логічну адресу розбивають на індекс у таблиці верхнього рівня, індекс у таблиці нижнього рівня і зсув.
Ця технологія має дві основні переваги. По-перше, таблиці сторінок стають менші за розміром, тому пошук у них можна робити швидше. По-друге, не всі таблиці сторінок мають перебувати в пам’яті у конкретний момент часу. Наприклад, якщо процес не використовує якийсь блок пам’яті, то вміст усіх сторінок нижнього рівня невикористовуваного блоку може бути тимчасово збережений на диску.
8.3.4. Реалізація таблиць сторінок в архітектурі IA-32
Архітектура IA-32 використовує дворівневу сторінкову організацію, починаючи з моделі Intel 80386.
Таблицю верхнього рівня називають каталогом сторінок (page directory), для кожної задачі повинен бути заданий окремий каталог сторінок, фізичну адресу якого зберігають у спеціальному регістрі cr3 і куди він автоматично завантажується апаратним забезпеченням при перемиканні контексту. Таблицю нижнього рівня називають просто таблицею сторінок (page table).
Лінійна адреса поділяється на три поля:
· каталогу (Directory) – визначає елемент каталогу сторінок, що вказує на потрібну таблицю сторінок;
· таблиці (Table) – визначає елемент таблиці сторінок, що вказує на потрібний фрейм пам’яті;
· зсуву (Offset) – визначає зсув у межах фрейму, що у поєднанні з адресою фрейму формує фізичну адресу.
Розмір каталогу і таблиці становить 10 біт, що дає таблиці сторінок, які містять 1024 елементи, розмір поля зсуву – 12 біт, що дає сторінки і фрейми розміром 4 Кбайт. Одна таблиця сторінок нижнього рівня адресує 4 Мбайт пам’яті (1 Мбайт фреймів), а весь каталог сторінок – 4 Гбайт.
Елементи таблиць сторінок всіх рівнів мають однакову структуру. Виокремимо такі поля елемента:
· прапорець присутності (Present), дорівнює одиниці, якщо сторінка перебуває у фізичній пам’яті (їй відповідає фрейм); рівність цього прапорця нулю означає, що сторінки у фізичній пам’яті немає, при цьому операційна система може використати інші поля елемента для своїх цілей;
· 20 найбільш значущих бітів, які задають початкову адресу фрейму, кратну 4 Кбайт (може бути задано 1 Мбайт різних початкових адрес);
· прапорець доступу (Accessed), який покладають рівним одиниці під час кожного звертання пристрою сторінкової підтримки до відповідного фрейму;
· прапорець зміни (Dirty), який покладають рівним одиниці під час кожної операції записування у відповідний фрейм;
· прапорець читання-записування (Read/Write), що задає права доступу до цієї сторінки або таблиці сторінок (для читання і для записування або тільки для читання);
· прапорець привілейованого режиму (User/Supervisor), який визначає режим процесора, необхідний для доступу до сторінки. Якщо цей прапорець дорівнює нулю, сторінка може бути адресована тільки із привілейованого режиму, якщо одиниці – доступна також і з режиму користувача.
Прапорці присутності, доступу і зміни можна використовувати ОС для організації віртуальної пам’яті.
8.3.5. Асоціативна пам’ять
Під час реалізації таблиць сторінок для отримання доступу до байта фізичної пам’яті доводиться звертатися до пам’яті кілька разів. У разі використання дворівневих сторінок потрібні три операції доступу: до каталогу сторінок, до таблиці сторінок і безпосередньо за адресою цього байта, а для трирівневих таблиць – чотири операції. Це сповільнює доступ до пам’яті та знижує загальну продуктивність системи.
Як уже зазначалося, правило «дев’яносто до десяти» свідчить, що більша частина звертань до пам’яті процесу належить до малої підмножини його сторінок, причому склад цієї підмножини змінюється досить повільно. Засобом підвищення продуктивності у разі сторінкової організації пам’яті є кешування адрес фреймів пам’яті, що відповідають цій підмножині сторінок.
Для розв’язання цієї проблеми було запропоновано технологію асоціативної пам’яті або кеша трансляції (translation look-aside buffers, TLB). У швидкодіючій пам’яті (швидшій, ніж основна пам’ять) створюють набір із кількох елементів (різні архітектури відводять під асоціативну пам’ять від 8 до 2048 елементів, в архітектурі IA-32 таких елементів до Pentium 4 було 32, починаючи з Pentium 4 – 128). Кожний елемент кеша трансляції відповідає одному елементу таблиці сторінок.
Тепер під час генерування фізичної адреси спочатку відбувається пошук відповідного елемента таблиці в кеші (в IA-32 – за полем каталогу, полем таблиці та зсуву), і якщо він знайдений, стає доступною адреса відповідного фрейму, що негайно можна використати для звертання до пам’яті. Якщо ж у кеші відповідного елемента немає, то доступ до пам’яті здійснюють через таблицю сторінок, а після цього елемент таблиці сторінок зберігають в кеші замість найстарішого елемента (рис. 8.9).
На жаль, у разі перемикання контексту в архітектурі IA-32 необхідно очистити весь кеш, оскільки в кожному процесу є своя таблиця сторінок, і ті ж самі номери сторінок для різних процесів можуть відповідати різним фреймам у фізичній пам’яті. Очищення кеша трансляції є дуже повільною операцією, якої треба всіляко уникати.
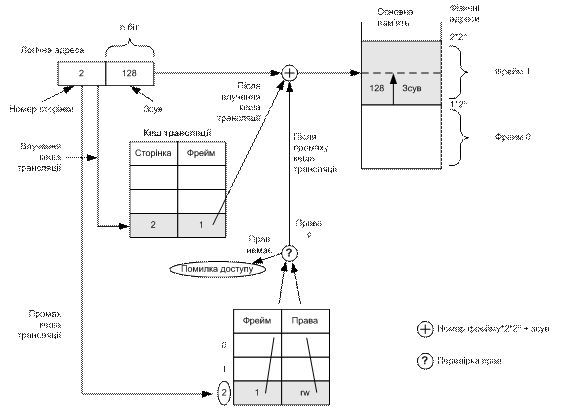
Рис. 8.9. Принцип роботи кеша трансляції
Важливою характеристикою кеша трансляції є відсоток влучень, тобто відсоток випадків, коли необхідний елемент таблиці сторінок перебуває в кеші і не потребує доступу до пам’яті. Відомо, що при 32 елементах забезпечується 89% влучень. Зазначимо також, що за такого відсотку влучень зниження продуктивності у разі використання дворівневих таблиць сторінок порівняно з однорівневими становить 28%, однак переваги, отримувані під час розподілу пам’яті, роблять таке зниження допустимим.
8.4. Сторінково-сегментна організація пам’яті
Базові принципи
Оскільки сегменти мають змінну довжину і керувати ними складніше, чиста сегментація зазвичай не настільки ефективна, як сторінкова організація. З іншого боку, видається цінною сама можливість використати сегменти як блоки пам’яті різного призначення змінної довжини.
Для того щоб об’єднати переваги обох підходів, у деяких апаратних архітектурах (зокрема, в IA-32) використовують комбінацію сегментної та сторінкової організації пам’яті. За такої організації перетворення логічної адреси у фізичну відбувається за три етапи.
- У програмі задають логічну адресу із використанням сегменту і зсуву.
- Логічну адресу перетворюють у лінійну (віртуальну) адресу за правилами, заданими для сегментації.
- Віртуальну адресу перетворюють у фізичну за правилами, заданими для сторінкової організації.
Таку архітектуру називають сторінково-сегментною організацією пам’яті.
Перетворення адрес в архітектурі IA-32
Розглянемо особливості реалізації описаних трьох етапів перетворення адреси в архітектурі IA-32.
- Машинна мова архітектури IA-32 (а, отже, будь-яка програма, розроблена для цієї архітектури) оперує логічними адресами. Логічна адреса, як було зазначено раніше, складається із селектору і зсуву.
- Лінійна або віртуальна адреса – це ціле число без знака завдовжки 32 біти. За його допомогою можна дістати доступ до 4 Гбайт комірок пам’яті. Перетворення логічної адреси в лінійну відбувається всередині пристрою сегментації (segmentation unit) за правилами перетворення адреси на базі сегментації, описаними раніше.
- Фізичну адресу використовують для адресації комірок пам’яті в мікросхемах пам’яті. ЇЇ теє зображають 32-бітовим числом без знака. Перетворення лінійної адреси у фізичну відбувається всередині пристрою сторінкової підтримки (paging unit) за правилами для сторінкової організації пам’яті (лінійну адресу розділяють апаратурою на адресу сторінки і сторінковий зсув, а потім перетворюють у фізичну адресу із використанням таблиць сторінок, кеша трансляції тощо).
Формування адреси у разі сторінково-сегментної організації пам’яті показане на рис. 8.10.
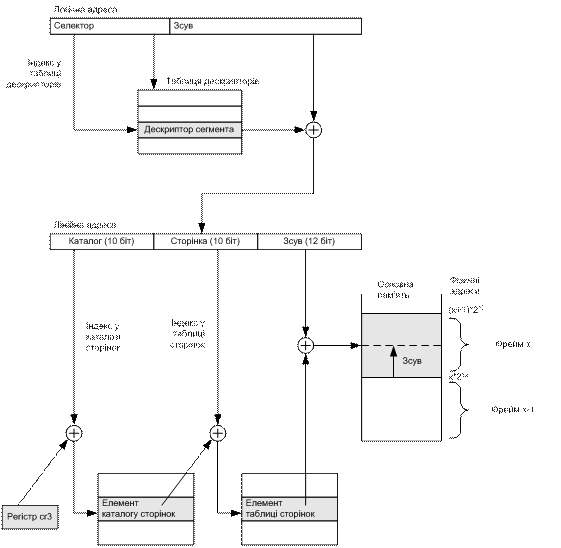
Рис. 8.10. Сторінково-сегментна організація пам’яті в архітектурі IA-32
Необхідність підтримки сегментації в IA-32 значною мірою є даниною традиції (це пов’язано з необхідністю зворотньої сумісності зі старими моделями процесорів, у яких була відсутня підтримка сторінкової організації пам’яті). Сучасні ОС часто обходять таку сегменту організацію майже повністю, використовуючи в системі лише кілька загальних сегментів, причому кожен із них задають селектором, у дескрипторі поле base дорівнює нулю, а поле limit – максимальній адресі лінійної пам’яті. Зсув логічної адреси завжди буде рівний лінійній адресі, а отже, лінійну адресу можна буде формувати у програмі, фактично переходячи до чисто сторінкової організації пам’яті.
8.5. Реалізація керування основною пам’яттю: Windows XP
8.5.1. Сегментація у Windows XP
Система Windows XP використовує загальні сегменти пам’яті. Для всіх сегментів у програмі задають однакові значення бази і межі, тому роботу з керування пам’яттю аналогічним чином передають на рівень лінійних адрес (які є зсувом у цих загальних сегментах).
8.5.2. Сторінкова адресація у Windows XP
Під час роботи з лінійними адресами у Windows XP використовують дворівневі таблиці сторінок, повністю відповідні архітектурі IA-32. У кожного процесу є свій каталог сторінок,кожен елемент якого вказує на таблицю сторінок. Таблиці сторінок усіх рівнів місять по 1024 елементи таблиці сторінок, кожний такий елемент вказує на фрейм фізичної пам’яті. Фізичну адресу каталогу сторінок зберігають у блоці KPROCESS.
Розмір лінійної адреси, з якою працює система, становить 32 біти. З них 10 біт відповідають адресі в каталозі сторінок, ще 10 – це індекс елемента в таблиці, останні 12 біт адресують конкретний байт сторінки (і є зсувом).
Розмір елементи таблиці сторінок теж становить 32 біти. Перші 20 біт адресують конкретний фрейм (і використовується разом із останніми 12 біт лінійної адреси), а інші 12 біт описують атрибути сторінки (захист, стан сторінки в пам’яті, який файл підкачування використовує). Якщо сторінка не перебуває у пам’яті, то в перших 20 біт зберігають зсув у файлі підкачування.
Для платформо-незалежного визначення розміри сторінки у Win32 API використовують універсальну функцію отримання інформації про систему GetSystemInfo():
SYSTEM_INFO info; //структура для отримання інформації про систему
GetSystemInfo(&info);
printf(“Розмір сторінки: %d\n”, info.dwPageSize);
8.5.3. Особливості адресації процесів і ядра
Лінійний адресний простір поділяється на дві частини: перші 2 Гбайт адрес доступні для процесу в режимі користувача і є його захищеним адресним простором; інші 2 Гбайт адрес доступні тільки в режимі ядра і відображають системний адресний простір.
Зазначимо, що таке співвідношення між адресним простором процесу і ядра відрізняється від прийнятого в Linux (3 Гбайт для процесу, 1 Гбайт для ядра).
Деякі версії Windows XP дають можливість задати співвідношення 3 Гбайт/1 Гбайт під час завантаження системи.
8.5.4. Структура адресного простору процесів і ядра
В адресному просторі процесу можна виділити такі ділянки:
· перші 64 Кбайт (починаючи з нульової адреси) – це спеціальна ділянка, доступ до якої завжди спричиняє помилки;
· усю пам’ять між першими 64 Кбайт і останніми 136 Кбайт (майже 2 Гбайт) може використовувати процес під час свого викоання;
далі розташовані два блоки по 4 Кбайт: блоки оточення потоку (TEB) і процесу (PEB);
· наступні 4 Кбайт – ділянка пам’яті, куди відображаються різні системні дані (системний час, значення лічильника системний годин, номер версії системи), тому для доступу до них процесу не потрібно перемикатися в режим ядра;
· остання 64 Кбайт використовують для запобігання спробам доступу за межі адресного простору процесу (спроба доступу до цієї пам’яті дасть помилку).
Системний адресний простір містить велику кількість різних ділянок. Найважливіші з них наведено нижче.
· Перші 512 Мбайт системного адресного простору використовують для завантаження ядра системи.
· 4 Мбайт пам’яті виділяють під каталог сторінок і таблиці сторінок процесу.
· Спеціальну ділянку пам’яті розміром 4 Мбайт, яку називають гіперпространством (hyperspace), використовують для відображення різних структур даних, специфічних для процесу, на системний адресний простір (наприклад, вона містить список сторінок робочого набору процесу).
· 512 Мбайт виділяють під системний кеш.
· У системній адресний простір відображаються спеціальні ділянки пам’яті – вивантажуваний пул і невивантажуваний пул.
· Приблизно 4 Мбайт у самому кінці системного адресного простору виділяють під структури даних, необхідні для створення аварійного образу пам’яті, а також для структур даних HAL.
Висновки
· Керування пам’яттю є однією з найскладніших задач, які стоять перед операційною системою. Щоб нестача пам’яті не заважала роботі користувача, потрібно розв’язувати задачу координації різних видів пам’яті. Можна використовувати повільнішу пам’ять для збільшення розміру швидшої (на цьому ґрунтується технологія віртуальної пам’яті), а також швидшу – для прискорення доступу до повільнішої (на цьому ґрунтується кешування).
· Технологія віртуальної пам’яті передбачає введення додаткових перетворень між логічними адресами, які використовують програми, та фізичними, що їх розуміє мікросхема пам’яті. На основі таких перетворень може бути реалізований захист пам’яті; крім того, вони дають змогу процесу розміщуватися у фізичній пам’яті не неперервно і не повністю (ті його частини, які в цей момент часу не потрібні, можуть бути збережені на жорсткому диску). Ця технологія спирається на той факт, що тільки частина адрес процесу використовується в конкретний момент часу, тому коли зберігати в основній пам’яті тільки її, продуктивність процесу залишиться прийнятною.
· Базовими підходами до реалізації віртуальної пам’яті є сегментація і сторінкова організація. Обидві ці підходи дають можливість розглядати логічний адресний простір процесу як сукупність окремих блоків, кожен з яких може бути відображений на основну пам’ять або диск. Головна відмінність полягає в тому, що у випадку сегментації блоки мають змінну довжину, а у разі сторінкової організації – постійну. Сьогодні часто трапляється комбінація цих двох підходів (сторінково-сегментна організація пам’яті).
· У разі сторінкової організації пам’яті логічна адреса містить номер у спеціальній структурі даних – таблиці сторінок, а також зсув відносно початку сторінки. Розділення адреси на частини відбувається апаратно. Елемент таблиці сторінок містить адресу початку блоку фізичної пам’яті, у який відображається сторінка (такий блок називається фреймом) і права доступу. Він може також відповідати сторінці, відображеній на диск. Таблиці сторінок можуть містити кілька рівнів. Таблицю верхнього рівня називають каталогом сторінок. Кожний процес має свій набір таких таблиць. Для прискорення доступу останні використані елементи таблиць керуються в асоціативній пам’яті.
Розділ 9
Взаємодія з диском під час керування пам’яттю
· Підкачування сторінок пам’яті
· Зберігання і заміщення сторінок пам’яті
· Резидентна множина і пробуксовування
· Організація віртуальної пам’яті в Linux та Windows XP
9.1. Причини використання диска під час керування пам’яттю
Тимчасове збереження окремих частин адресного простору на диску допомагає розв’язати одну з основних проблем, що виникають під час реалізації керування пам’яттю в ОС, а саме: організація завантаження і виконання програм,які окремо або разом не вміщаються в основній пам’яті.
Найпростішим і найдавнішим підходом є завантаження і вивантаження всього адресного простору процесу за один прийом. Процеси завантажуються у пам’ять повністю, виконуються певний час, а потім так само повністю вивантажуються на диск. Отже, процес або весь перебуває у пам’яті, або цілком зберігається на диску (про такий процес прийнято говорити, що він перебуває у вивантаженому стані). Така технологія має низку недоліків:
· її використання призводить до значної фрагментації зовнішньої пам’яті;
· вона не дає змоги виконувати процеси, які мають потребу у більшому обсязі пам’яті, ніж доступно у системі;
· погано підтримуються процеси, які можуть виділяти собі додаткову динамічну пам’ять (це потрібно робити з урахуванням можливого розширення адресного простору процесу).
Вивантаження всього процесу із пам’яті у сучасних ОС можна використовувати як засіб зниження навантаження, але лише на доповнення до інших технологій взаємодії з диском.
9.2. Поняття підкачування
Описана технологія повного завантаження і вивантаження процесів традиційно називалася підкачуванням або простим підкачуванням, але тут вживатимемо цей термін у ширшому значенні. У сучасних ОС під підкачуванням (swapping) розуміють увесь набір технологій, які здійснюють взаємодію із диском під час реалізації віртуальної пам’яті, щоб дати можливість кожному процесу звертатися до великого діапазону логічних адрес за рахунок використання дискового простору.
Розглянемо загальні принципи підкачування. Як відомо, зняття вимоги неперервності фізичного простору, куди відображається адресний простір процесу і можливість переміщення процесу в пам’яті під час його виконання дає змогу не тримати одночасно в основній пам’яті всі блоки пам’яті (сторінки або сегменти), які утворюють адресний простір цього процесу. Під час завантаження процесу в основну пам’ять у ній розміщають лише кілька його блоків,які потрібні для початку роботи. Частину адресного простору, що у конкретний момент часу відображається на основну пам’ять, називають резидентною множиною процесу (resident set). Поки процес звертається тільки до пам’яті резидентної множини, виконання процесу не переривають. Як тільки здійснюється посилання на блок, що перебуває за межами резидентної множини (тобто відображений на диск), відбувається апаратне переривання. Оброблювач цього переривання призупиняє процес і запускає дискову операцію читання потрібного блоку із диска в основну пам’ять. Коли блок зчитаний, операційну систему сповіщають про це, після чого процес переводять у стан готовності й, зрештою, поновлюють, після чого він продовжує свою роботу, ніби нічого й не сталося; на момент його поновлення потрібний блок уже перебуває в основній пам’яті, де процес і розраховував його знайти.
Реалізація підкачування використовує правило «дев’яносто до десяти». Ідеальною реалізацією керування пам’яттю є надання кожному процесові пам’яті, за розміром порівнянної із жорстким диском, а за швидкістю доступу – з основною пам’яттю. Оскільки за правилом «дев’яносто до десяти» на 10 % адресного простору припадає 9- % посилань на пам’ять, як деяке наближення до ідеальної реалізації можна розглядати такий підхід: зберігати ці 10 % в основній пам’яті, а інший адресний простір відображається на диск. Як показано на рис. 9.1,частіше використовують сторінки 0, 3, 4, 6, тому їхній вміст зберігають в основній пам’яті, а сторінки 1, 2, 5,7 використовують рідше, тому їхній вміст зберігають на диску.
Головною проблемою залишається ухвалення рішення про те, які із блоків пам’яті мають в конкретний момент відображатися на основну пам’ять, а які – на диск.
Внаслідок використання технології підкачування кількість виконуваних процесів збільшується (для кожного з них в основній пам’яті перебуватиме тільки частина блоків). Підкачування дає також змогу виконувати процеси, які за розміром більші, ніж основна пам’ять (для таких процесів у різні моменти часу в основну пам’ять відображатимуться різні блоки).
Ми розглядатимемо підкачування, яке використовується у поєднанні зі сторінковою організацією пам’яті. Слід зазначити, що підкачування аналогічним чином може бути реалізоване й на основі сегментації, хоча ця задача виглядає складнішою через те, що наперед не відомо, якого розміру блоки потрібно буде зберігати на диску.
9.3. Завантаження сторінок на вимогу. Особливості підкачування сторінок
Базовий підхід, який використовують під час реалізації підкачування сторінок із диска, називають технологією завантаження сторінок на вимогу (demand paging).
Ця технологія діє у припущенні, що не всі сторінки процесу мають завантажуватися у пам’ять негайно. Завантажуються тільки ті, що необхідні для початку його роботи, інші – коли стають потрібні. Процес переносу сторінки із диска у пам’ять називають завантаженням із диска (swapping in), процес переносу сторінки із пам’яті на диск – вивантаженням на диск (swapping out).
Апаратна підтримка підкачування сторінок
Для організації апаратної підтримки підкачування кожний елемент таблиці сторінок має містити спеціальний біт – біт присутності сторінки у пам’яті Р. Коли він дорівнює одиниці, то це означає, що відповідна сторінка завантажена в основну пам’ять, і їй відповідає деякий фрейм. Якщо біт присутності сторінки дорівнює нулю, це означає, що дана сторінка перебуває на диску і має бути завантажена в основну пам’ять перед використанням (рис. 9.2).У таблиці сторінок архітектури IA-32 даний біт називають Present.
Для сторінки може бути заданий біт модифікації М. Його спочатку (під час завантаження сторінки із диска) покладають рівним нулю, потім – одиниці, якщо сторінку модифікують, коли вона завантажена у фрейм основної пам’яті. Наявність такого біта дає змогу оптимізувати операції вивантаження на диск вміст сторінки, для якої біт М дорівнює нулю, це означає, що записування на диск можна проігнорувати, бо вміст сторінки не змінився від часу завантаження у пам’ять. У таблиці сторінок архітектури IA-32 даний біт називають Dirty.
Якщо процес працює тільки зі сторінками, для яких біт Р дорівнює одиниці (його резидентна множина не змінюється), складається враження, що всі його сторінки є у пам’яті, хоча насправді це може бути і не так (просто сторінок, яких немає у пам’яті, у цьому разі взагалі не використовують).
9.4. Проблеми реалізації підкачування сторінок
Під час реалізації підкачування потрібно дати відповідь на такі запитання.
Які сторінки потрібно завантажити із диска і в який час?
Відповідь на це запитання визначає прийнята в цій системі стратегія вибірки сторінок. Однією з таких стратегій є завантаження сторінок на вимогу, яку щойно було розглянуто, коли сторінку завантажують у пам’ять тільки під час обробки сторінкового переривання. Іншою стратегією такого роду є попереднє завантаження сторінок (prepaging), коли у пам’ять завантажують кілька сторінок, розташованих на диску послідовно для того щоб зменшити кількість таких сторінкових переривань. Ця технологія ґрунтується на принципі локалізації, але переваги у продуктивності у разі її застосування довести не вдалося.
Яку сторінку потрібно вивантажити на диск, коли вільних фреймів у основній пам’яті більше немає?
Відповідь на це запитання визначає стратегія заміщення сторінок.
Де у фізичній пам’яті мають розміщуватися сторінки процесу?
Відповідь на це запитання визначає стратегія розміщення. Вона відіграє важливу роль під час реалізації підкачування на основі сегментації, у разі підкачування на основі сторінкової організації вона не така важлива, оскільки всі сторінки рівноправні й можуть перебувати у пам’яті де завгодно.
Яким чином організувати керування резидентною множиною?
Головне завдання такого керування – забезпечити, щоб у резидентній множині були тільки сторінки, які дійсно потрібні процесу.
9.5. Заміщення сторінок
Під час генерації сторінкового переривання може виникнути ситуація, коли жодного вільного фрейму у фізичній пам’яті немає. Причини появи цієї проблеми полягають в особливостях використання завантаження сторінок на вимогу.
Припустимо, що в нашій системі кожен процес у конкретний момент часу середньому звертається тільки до половини своїх сторінок. Завантаження сторінок на вимогу залишає половину сторінок кожного процесу на диску, вивільняючи половину фреймів фізичної пам’яті, які міг би зайняти цей процес, для виконання інших процесів. Тому можна завантажити у пам’ять більше процесів. Нехай основна пам’ять містить 60 фреймів. Якщо не використовувати завантаження на вимогу, в основну пам’ять можна завантажити шість процесів, кожен з яких використає 10 сторінок, причому кожній сторінці буде відповідати певний фрейм. У разі використання завантаження на вимогу ці шість процесів у конкретний момент часу використовуватимуть тільки 30 фреймів пам’яті, а інші 30 залишатимуться вільними, тому можна завантажити в них ще до шести процесів (у сумі - до дванадцяти).
Припустимо, що у пам’ять завантажено одночасно вісім процесів; у цьому разі процесор використовуватиметься активніше, ніж для шести запущених процесів, м того, вивільниться 20 фреймів. Однак загальний обсяг адресного простору завантажених процесів перевищуватиме обсяг фізичної пам’яті. Поки процеси використовують свої сторінки звичайним чином (на 50 %), всі м будуть виконуватися в основній пам’яті без проблем. Але завжди може виникнути ситуація, коли процеси зажадають більше пам’яті, ніж їм це потрібно в середньому. Згадані вісім процесів можуть у якийсь момент зажадати весь свій адресний простір, тому всього їм знадобиться 80 фреймів основної пам’яті (а їх тільки 60). Що більше процесів одночасно виконується в системі, то вища ймовірність виникнення такої ситуації. Як домогтися того, щоб вона виникала не дуже часто, розглянемо в розділі 9.7. У цьому розділі зупинимося на діях, яких вимагають від ОС, коли така ситуація вже виникла.
За відсутності вільного фрейму в пам’яті ОС має вибрати, яку сторінку вилучити із пам’яті для того щоб вивільнити місце для нової сторінки. Процес цього вибору визначає стратегія заміщення сторінок. Коли сторінка, яку вилучають, була змінена, необхідно вивантажити її на диск для відображення цих змін, коли ж вона залишилася незмінною (наприклад, це була сторінка із програмним кодом), цього робити не потрібно. Для індикації того, чи була сторінка змінена, використовують біт модифікації сторінки М (про нього йшлося в розділі 9.3.1)
Яку саме сторінку потрібно вилучати із пам’яті, визначає алгоритм заміщення сторінок (page replacement algorithm). Вибір такого алгоритму відчутно впливає на продуктивність системи, тому що вдало підібраний алгоритм зменшує кількість сторінкових переривань, а невдала його реалізація може її значно збільшити (якщо вилучити часто використовувану сторінку, то вона незабаром може знову знадобитися і т. д.). Навіть невеликі поліпшення в методах заміщення сторінок можуть спричинити великий загальний виграш у продуктивності.
Слід зазначити, що алгоритми заміщення сторінок (особливо ті, які справді дають виграш у продуктивності) досить складні в реалізації і майже завжди потребують апаратної підтримки (хоча б у вигляді наявності біта модифікації сторінки М).
Ось який вигляд матиме алгоритм завантаження сторінки з урахуванням заміщення сторінок.
Знайти вільний фрейм у фізичній пам’яті:
якщо вільний фрейм є, використати його (перейти до кроку 2);
якщо вільного фрейму немає, використати алгоритм заміщення сторінок для того щоб знайти фрейм-жертву (victim frame);
записати фрейм-жертву на диск (якщо біт модифікації для нього ненульовий), відповідно змінити таблицю сторінок і таблицю вільних фреймів.
Знайти потрібну сторінку на диску.
Прочитати потрібну сторінку у вільний фрейм (якщо раніше були виконані кроки b і c п. 1, цим фреймом буде той, котрий щойно вивільнився).
Знову запустити інструкцію, на якій відбулося переривання.
9.5.1. Оцінка алгоритмів заміщення сторінок. Рядок посилань
Оскільки реалізація алгоритмів заміщення сторінок важлива з погляду продуктивності системи, вони ретельно досліджувалися, були виділені критерії їх порівняння і формат даних для тестування.
Критерієм для порівняння алгоритмів заміщення звичайно є рівень сторінкових переривань: що він нижчий, то кращим вважають алгоритм. Оцінку алгоритму здійснюють через підрахунок кількості сторінкових переривань, які виникли внаслідок його запуску для конкретного набору посилань на сторінки у пам’яті. Набір посилань на сторінки подають рядком посилань (reference string) із номерами сторінок. Такий рядок можливо згенерувати випадково, а можна отримати відстеженням посилань на пам’ять у реальній системі (у цьому разі даних бути зібрано дуже багато). Групу із кількох посилань, що йдуть підряд, на одну й ту саму сторінку в рядку відображають одним номером сторінки, оскільки такий набір посилань не може спричинити сторінкового переривання
У цьому розділі використовуватимемо такий рядок посилань:
1, 2, 3, 5, 2, 4, 2, 4, 3, 1, 4.
Щоб оцінити алгоритми заміщення, потрібно також зазначити кількість доступних фреймів. Чим вона більша, тим меншим буде рівень сторінкових переривань, тому алгоритми оцінюють для однакових її значень. Зазначимо, що, коли доступний один фрейм, кожен елемент рядка посилань викликатиме сторінкове переривання; з іншого боку, якщо кількість доступних фреймів дорівнює кількості різних сторінок у рядку посилань, сторінкових переривань не буде зовсім. Алгоритми оцінюватимемо для трьох доступних фреймів.
Найпростішим у реалізації (за винятком алгоритму випадкового заміщення) є алгоритм FIFO. Він дозволяє замінити сторінку, яка перебувала у пам’яті найдовше.
На рис. 9.3 зображена робота цього алгоритму на рядку посилань (кольором тут і далі виділено сторінкові переривання).
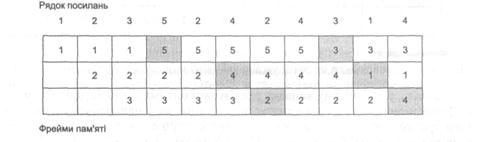
Рис. 9.3. FIFO-алгоритм заміщення сторінок
Для реалізації такого алгоритму досить підтримувати у пам’яті список усіх сторінок, організований за принципом FIFO-черги (звідси й назва алгоритму). Коли сторінку завантажують у пам’ять, її додають у хвіст черги, у разі заміщення її вилучають з голови черги.
Основними перевагами цього алгоритму є те, що він не потребує апаратної підтримки (тому для архітектур, які такої підтримки не надають, він може бути єдиним варіантом реалізації заміщення сторінок).
Головним недоліком алгоритму FIFO є те, що він не враховує інформації про використання сторінки. Такий алгоритм може вибрати для вилучення, наприклад, сторінку із важливою змінною, котра вперше отримала своє значення на початку роботи, і з того часу її постійно використовують та модифікують. Вилучення такої сторінки із пам’яті призводить до того, що система буде негайно змушена знову звернутися по неї на диск.
Такий алгоритм недостатньо ефективний, і його варто використовувати тоді, коли кращого алгоритму реалізувати не вдається (або у поєднанні з іншими підходами, наприклад, з буферизацією сторінок, яку буде описано в розділі 9.5.6). Деякі інші, ефективніші алгоритми в найгіршому випадку можуть зводитися до алгоритму FIFO.
Наголосимо, однак, що жоден алгоритм заміщення не може призвести до некоректної роботи програми. Після того як сторінка буде завантажена у пам’ять із диска, робота з нею відбуватиметься так, ніби вона була в пам’яті від самого початку. Різниця полягатиме тільки у продуктивності (втім, ця різниця може виявитися дуже істотною).
|
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 3459; Нарушение авторских прав?; Мы поможем в написании вашей работы!