КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Визначення робочого набору
|
|
|
|
Для визначення робочого набору процесу застосовують прапорець використання сторінки (PG_referenced). Нові сторінки створюють із PG_referenced = 0. Коли процесор зчитує сторінку вперше, прапорець покладають рівним одиниці. Якщо потрібно задати PG_referenced рівним одиниці для сторінки, що перебуває у списку неактивних сторінок, його обнулюють, і сторінку переміщують у список активних (так формують робочий набір процесу). З іншого боку, неактивну сторінку можна використати для розміщення нових даних незалежно від значення цього прапорця. Якщо ж сторінка, для якої PG_referenced = 1, має бути переміщена у список неактивних сторінок, система дає змогу це зробити тільки з другої спроби обходу (сторінці дають другий шанс для її використання).
Обробка відображених, змінених і заблокованих сторінок
Під час обходу списку неактивних сторінок для вивільнення пам’яті може виникнути ситуація, коли цього відразу зробити не можна.
Сторінка може бути відображена в адресний простір процесу або кількох процесів. Щоб вивільнити сторінку, відображення спочатку потрібно вилучити для кожного такого процесу.
Сторінка може бути заблокована у пам’яті (наприклад, у ній виділено буфер, який використовують для введення даних із пристрою). Під час обходу таку сторінку пропускають і роблять спробу знайти іншу сторінку для вивільнення. Ця сторінка може бути знову перевірена у такому проході.
Сторінка була модифікована, тому її спочатку треба записати на диск. Як тільки не відображену в адресний простір процесу модифіковану сторінку переміщують із початку в кінець списку неактивних сторінок, система скидає її вміст на диск.
Блокування сторінок у пам’яті
Для організації блокування сторінок у пам’яті в Linux використовують системні виклики mlock() і munlock(), прототипи яких визначені в заголовному файлі sys/mman.h. Системний виклик mlock () блокує у пам’яті набір сторінок, munlock() знімає це блокування. Обидва ці виклики приймають два параметри: адресу, з якої починається блокований набір сторінок, і розмір пам’яті, яку потрібно заблокувати або розблокувати.
|
|
|
Наведемо приклад блокування однієї сторінки із використанням цих викликів.
#include <sys/tmtan.h>
#include <stdlib.h> //для malloc()
.size_t pagesize = getpagesiz():
//виділення пам’яті під сторінку
char* page = (char *)malloc(pagesize);
//сторінка заблокована у пам’яті й не може бути вивантажена на диск
mlock (page, pagesize);
//...
//розблокування сторінки
munlock(page, pagesize);
Системний виклик mlockall() блокує у пам’яті всі сторінки поточного процесу. Користуватися ним потрібно з обережністю, оскільки заблоковану пам’ять не можна використовувати під час розподілу пам’яті доти, поки вона не буде розблокована (або поки процес не завершиться).
9.9. Реалізація віртуальної пам’яті в Windows XP
У цьому розділі розглянемо особливості керування пам’яттю Windows XP.
9.9.1. Віртуальний адресний простір процесу
Сторінки і простір підтримки
Сторінки адресного простору процесу можуть бути вільні (free), зарезервовані (reserved) і підтверджені (committed).
Вільні сторінки не можна використати процесом прямо, їх потрібно спочатку зарезервувати. Це можливо зробити будь-яким процесом системи. Після цього інші процеси резервувати ту саму сторінку не можуть.
У свою чергу, процес, що зарезервував сторінку, не може цю сторінку використати до її підтвердження, тому що зв’язок із конкретними даними або програмами для неї не визначений.
Підтверджені сторінки безпосередньо пов’язані із простором підтримки на диску. Такі сторінки можуть бути двох типів.
Дані для сторінок першого типу перебувають у звичайних файлах на диску. До таких сторінок належать сторінки коду (їм відповідають виконувані файли) і сторінки, що відповідають файлам даних, відображеним у пам’ять (див. розділ 11). Для таких сторінок простором підтримки будуть відповідні файли. Один і той самий файл може підтримувати блоки адресного простору різних процесів.
|
|
|
Сторінки другого типу не пов’язані прямо із файлами на диску. Це може бути, наприклад, сторінка, що містить глобальні змінні програми. Для таких сторінок простором підтримки є спеціальний файл підкачування (swap file). У ньому не резервують простір доти, поки не з’явиться необхідність вивантаження сторінок на диск. Сторінки, зарезервовані у файлі підкачування, називають ще тіньовими сторінками (shadow pages).
На рис. 9.10 показано, як різні частини адресного простору можуть бути пов’язані з різними типами простору підтримки.
Поняття регіону пам’яті. Резервування і підтвердження регіонів
Коли для процесу виділяють адресний простір, більшу його частину становлять вільні сторінки, які не можуть бути використані негайно. Для того щоб використати блоки цього простору, процес спочатку має зарезервувати в ньому відповідні регіони пам’яті.
Регіон пам’яті відображає неперервний блок логічного адресного простору процесу, який може використати застосування. Регіони характеризуються початковою адресою і довжиною. Початкова адреса регіону повинна бути кратною 64 Кбайт, а його розмір – кратним розміру сторінки (4 Кбайт).
Для резервування регіону пам’яті використовують функцію VirtualAlloc() (одним із її параметрів має бути прапорець MEM_RESERVE). Після того як регіон був зарезервований, інші запити виділення пам’яті не можуть його повторно резервувати. Ось приклад виклику VirtualAlloc() для резервування регіону розміру size:
PVOID addr = VirtualAllос(NULL, size, MEM_RESERVE, PAGE_READWRITE);
Першим параметром VirtualAlloc() є адреса пам’яті, за якою роблять виділення, якщо вона дорівнює NULL, пам’ять виділяють у довільній ділянці адресного простору процесу. Останнім параметром є режим резервування пам’яті, серед можливих значень цього параметра можна виділити PAGE_READONLY – резервування тільки для читання; PAGE_READWRITE –резервування для читання і записування.
Результатом виконання VirtualAlloc() буде адреса виділеного регіону пам’яті.
|
|
|
Однак і після резервування регіону будь-яка спроба доступу до відповідної пам’яті спричинятиме помилку. Щоб такою пам’яттю можна було користуватися, резервування регіону має бути підтверджене (commit). Підтвердження зводиться до виділення місця у файлі підкачування сторінок (для сторінок регіону створюють відповідні тіньові сторінки). Для підтвердження резервування регіону теж використовують функцію VirtualAlloc(), але їй потрібно передати прапорець MEM_COMMIT:
VirtualAlloc(addr, size, MEM_COMMIT, PAGE_READWRITE);
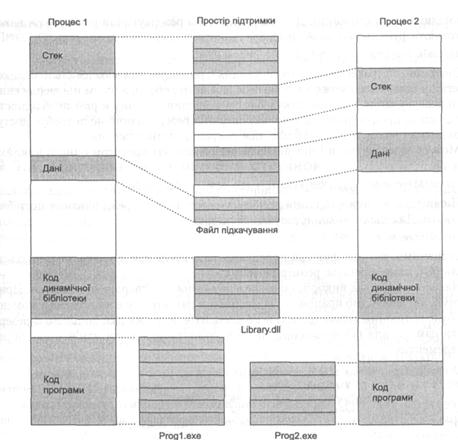
Рис. 9.10. Процеси і простір підтримки у Windows XP
Звичайною стратегією для застосування є резервування максимально великого регіону пам’яті, що може знадобитися для його роботи, а потім підтвердження його резервування для невеликих блоків всередині регіону в разі необхідності. Це підвищує продуктивність, тому що операція резервування не потребує доступу до диску і виконується швидше, ніж операція підтвердження.
Можна зарезервувати і підтвердити регіон пам’яті протягом одного виклику функції
VirtualAlloc(addr, size, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
Після того, як використання регіону завершене, його резервування потрібно скасувати. Для цього використовують функцію
VirtualFree(addr, 0, MEM_RELEASE);
Зазначимо, що цій функції передають не розмір пам’яті, яка звільняється, а нуль (ОС сама визначає розмір регіону).
Наведемо приклад використання резервування і підтвердження пам’яті. Припустимо, що необхідно працювати із масивом у пам’яті, але в конкретний момент часу буде потрібний тільки один із його елементів. У цьому розділі доцільно зарезервувати пам’ять для всього масиву, після чого підтверджувати пам’ять для окремих елементів.
//резервування масиву зі 100 елементів
int *array = (int *) VirtualAlloc(NULL,
100*sizeof(int), MEM_RESERVE, PAGE_READWRITE);
//підтвердження елемента масиву з індексом 10
VirtualAlloc(&array[10], sizeof(int), MEM_COMMIT, PAGE_READWRITE);
//робота із пам’яттю
array[10]=200;
printf(“дані у пам’яті: %d\n”, array[10]);
//вивільнення масиву
VirtualFree(array, 0, MEM_RELEASE);
Обробка сторінкових переривань
Назвемо причини виникнення сторінкових переривань у Windows XP.
|
|
|
· Звертання до сторінки, що не була підтверджена.
· Звертання до сторінки із недостатніми правами. Ці два випадки є фатальними помилками і виправленню не підлягають.
· Звертання для записування до сторінки, спільно використовуваної процесами.
· У цьому разі можна скористатися технологією копіювання під час записування.
· Необхідність розширення стека процесу. У цьому разі оброблювач переривання має виділити новий фрейм і заповнити його нулями.
· Звертання до сторінки, що була підтверджена, але в конкретний момент не завантажена у фізичну пам’ять. Під час обробки такої ситуації використовують локальність посилань: із диска завантажують не лише безпосередньо потрібну сторінку, але й кілька прилеглих до неї, тому наступного разу їх уже не доведеться заново підкачувати. Цим зменшують загальну кількість сторінкових переривань.
Поточну кількість сторінкових переривань для процесу можна отримати за допомогою функції GetProcessMemorylnfo():
#include <psapi.h>
PROCESS_MEMORY_COUNTERS info;
GetProcessMenoryInfo(GetCurrentProcess(). &info. sizeof (info));
printf("Усього сторінкових збоїв: %d\n", info.PageFaultCount);
9.9.2. Організація заміщення сторінок
Базовий принцип реалізації заміщення сторінок у Windows XP – підтримка деякої мінімальної кількості вільних сторінок у пам’яті. Для цього використовують кілька концепцій: робочі набори, буферизацію, старіння, фонове заміщення і зворотне відображення сторінок.
Керування робочим набором і фонове заміщення сторінок
Поняття робочого набору є центральним для заміщення сторінок у Windows XP. У цій ОС під робочим набором розуміють множину підтверджених сторінок процесу, завантажених в основну пам’ять. Під час звертання до таких сторінок не виникатиме сторінкових переривань. Кожний набір описують двома параметрами: його нижньою і верхньою межами. Ці межі не є фіксованими, за певних умов процес може за них виходити; крім того, вони пізніше можуть мінятися. Початкове значення меж однакове для всіх процесів (нижня межа має бути в діапазоні 20-50, верхня – 45-345 сторінок).
Поняття робочого набору було описане у розділі 9.7. Очевидно, що розуміння цієї концепції у Windows XP не повністю відповідає традиційному (не використовують параметра, що задає вікно робочого набору). Фактично робочий набір Windows XP відповідає резидентній множині процесу, як це визначено в розділі 9.2. Однак у цьому розділі використовуватимемо зазначене поняття із запропонованим застереженням.
Менеджер пам’яті постійно контролює сторінкові переривання для процесу, коригуючи його робочий набір. Якщо під час обробки сторінкового переривання виявляють, що розмір робочого набору процесу менший за мінімальне значення, до цього набору додають сторінку, якщо ж більший за максимальне значення – із набору вилучають сторінку. Оскільки всі ці дії стосуються робочого набору того процесу, що викликав сторінкове переривання, базова стратегія заміщення сторінок є локальною. Втім, локальність заміщення є відносною: у деяких ситуаціях система може коригувати робочий набір одного процесу за рахунок інших (наприклад, якщо для одного процесу бракує фізичної пам’яті, а для інших її достатньо).
Крім локального коригування робочого набору в оброблювачах сторінкових переривань, у системі також реалізовано глобальне фонове заміщення сторінок. Спеціальний потік ядра, який називають менеджером балансової множини (balance set manager), виконується за таймером раз за секунду і перевіряє, чи не опустилася кількість вільних сторінок у системі нижче за допустиму межу. Якщо так, потік запускає інший потік ядра – менеджер робочих наборів (working set manager), що забирає додаткові сторінки у процесів, коригуючи їхні робочі набори. Під час вибору сторінок для вилучення із робочого набору застосовують модифікацію годинникового алгоритму із використанням концепції старіння сторінок. Із кожною сторінкою пов’язаний цілочисловий лічильник ступеня старіння. Усі сторінки набору обходять по черзі. Якщо біт R для сторінки дорівнює 0, лічильник збільшують на одиницю, якщо R дорівнює 1, лічильник обнуляється. Внаслідок обходу заміщуються сторінки із найбільшим значенням лічильника.
Заміщені сторінки не зберігають негайно на диску, а буферизують.
Особливості буферизації сторінок
Організація буферизації сторінок у Windows XP доволі складна, але переважно дотримуються базової схеми, описаної у розділі 9.5.6.
Система підтримує 5 списків сторінок, переходи між якими показані на рис. 9.11.
Модифікованих (modified page list). Містить вилучені із робочих наборів сторінки, які були модифіковані й котрі потрібно зберегти на диску. За принципом використання він аналогічний списку Lm.
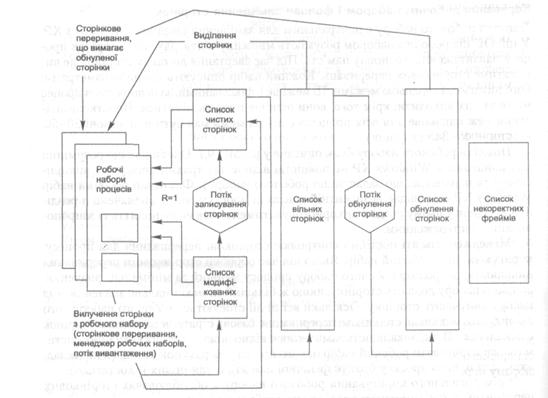
Рис. 9.11. Списки сторінок у Windows XP
Чистих (standby page list). Містить вилучені із робочих наборів сторінки, які можна негайно використати для виділення пам’яті. Він аналогічний списку Lf. Списки чистих і модифікованих сторінок працюють як кеші сторінок (див. розділ 9.5.6).
Вільних (free page list). У ньому перебувають сторінки, які не містять осмисленої інформації (немає сенсу повертати їх в робочі набори процесів).
Обнулених (zero page list). Аналогічний списку вільних сторінок, але сторінки в ньому заповнені нулями.
Некоректних фреймів фізичної пам’яті (bad page list). Фрейми в ньому відповідають ділянкам фізичної пам’яті, під час доступу до яких відбувався апаратний збій. Фрейми із цього списку ніколи не будуть використані менеджером пам’яті. Зазначимо, що у Windows XP відсутня концепція списку активних сторінок, таким списком є робочі набори процесів.
Під час вилучення із робочого набору процесу (за сторінкового переривання або внаслідок роботи менеджера робочих потоків) сторінка потрапляє в кінець списку чистих або модифікованих сторінок (залежно від стану її біта М). Після завершення процесу в ці списки переміщують усі його сторінки.
Крім того, за переміщення сторінок між списками відповідають кілька спеціалізованих потоків ядра.
· Потік вивантаження (swapper), який займається вивільненням сторінок неактивних процесів. Його запускають за таймером через 4 с. Якщо цей потік знаходить процес, усі потоки якого перебували у стані очікування упродовж деякого часу (від 3 до 7 с), він переміщує всі сторінки його робочого набору у списки чистих і модифікованих сторінок.
· Потік записування модифікованих сторінок (modified page writer), який виконує запис модифікованих сторінок на диск. Після того, як цей потік запише сторінку на диск, її переміщують у кінець списку чистих сторінок.
· Низькопріоритетний потік обнуління сторінок (zero page thread), переважно виконується, коли система не навантажена.
Коли потрібна нова сторінка, процес спочатку переглядає список вільних сторінок. Якщо він порожній, процес звертається до списку обнулених сторінок, якщо і в ньому немає жодного елемента, сторінку беруть зі списку чистих сторінок.
Попереднє завантаження сторінок
У Windows XP з’явилася підтримка попереднього завантаження сторінок. Вона ґрунтується на спостереженні за завантаженням коду програми. Воно часто сповільнюється внаслідок сторінкових переривань, які призводять до читання даних із різних файлів.
Для зменшення кількості файлів, до яких потрібно звертатися під час завантаження програмного коду, виконавча система Windows XP відслідковує сторінкові переривання упродовж 10 с під час першого запуску застосування. Після цього зібрану інформацію, зокрема, сторінки, завантажені у пам’ять, зберігають у спеціальному файлі попереднього завантаження застосування у підкаталозі Prefetch системного каталогу Windows XP.
Під час наступних спроб запуску застосування перевіряють, чи не був для нього уже створений файл попереднього завантаження. Якщо це так, відбувається завантаження у пам’ять збережених сторінок даних із цього файла. При цьому звертатися до файлів, з яких були завантажені ці сторінки під час першого запуску застосування, не потрібно.
Аналогічні дії відбуваються й під час завантаження всієї системи, коли створюють файл попереднього завантаження Windows XP. Дані з цього файлу будуть зчитані у пам’ять під час наступних завантажень системи.
Блокування сторінок у пам’яті
Як і в Linux, у Windows XP можна блокувати сторінки у пам’яті з коду режиму користувача. Для цього використовують функції Win32 API VirtualLock() і VirtualUnlock(). Відповідні сторінки мають бути до цього часу підтверджені.
SYSTEMINFO info; GetSystemInfo(&info);
DWORD pagesize = info.dwPageSize;
//резервування і підтвердження сторінки
char *pageaddr = (char *)VirtualAlloc(NULL.
pagesize. MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
//блокування сторінки у пам’яті
VirtualLock(pageaddr, pagesіze);
//... розблокування
VirtualUnlockCpageaddr, pagesize):
Оскільки блокування сторінок призводить до того, що відповідна фізична пам’ять виявляється втраченою для інших застосувань і системи, обсяг пам’яті, дозволеної для блокування, не може перевищувати нижньої межі робочого набору процесу.
Висновки
· Основною технологією взаємодії із диском в організації віртуальної пам’яті є завантаження сторінок на вимогу. При цьому сторінки не завантажують у пам’ять доти, поки до них не звернуться. Звертання до сторінки, не завантаженої у пам’ять, викликає сторінкове переривання, оброблювач такого переривання знаходить потрібну сторінку на диску і завантажує її у фізичну пам’ять. Така обробка займає багато часу, тому для досягнення прийнятної продуктивності кількість сторінкових переривань має бути якомога меншою. Невірна реалізація завантаження сторінок на вимогу може спричинити пробуксовування, коли процес витрачає більше часу на обмін із диском під час завантаження сторінок, ніж на корисну роботу.
· Коли потрібна вільна сторінка, а у фізичній пам’яті місця немає, потрібно зробити заміщення сторінки. Заміщувана сторінка буде збережена на диску, а у її фрейм завантажиться нова. Є багато алгоритмів визначення заміщуваної сторінки, найефективнішим на практиці є алгоритм LRU і його наближення, зокрема годинниковий алгоритм. На продуктивність заміщення сторінок впливають й інші фактори такі, як стратегія заміщення (глобальне або локальне) і визначення робочого набору програми (множини сторінок, які вона використовує в конкретний момент). На практиці часто використовують буферизацію сторінок, коли заміщені сторінки не записують відразу на диск, а зберігають у пам’яті у спеціальних списках, що відіграють роль кеша сторінок.
10. Динамічний розподіл пам’яті
· Принципи функціонування розподілювачів пам’яті
· Організація списків вільних блоків
· Системи двійників
· Посилання та збирання сміття
· Динамічний розподіл пам’яті в Linux та Windows
Динамічний розподіл пам’яті – це розподіл за запитами процесів користувача або ядра під час їхнього виконання. Розрізняють динамічне виділення та динамічне вивільнення пам’яті. Прикладом бібліотечної та мовної підтримки засобів динамічного розподілу пам’яті є функції malloc(), free() і realloc() бібліотеки мови С, оператори new і delete в C++. Усі ці засоби спираються на підтримку з боку операційної системи.
Зазначимо, що алгоритми цього розділу передбачають наявність суцільного лінійного адресного простору, абстрагуючись від того, як цей простір став доступний процесу, тобто від реалізації віртуальної пам’яті. Ці алгоритми є засобами розподілу пам’яті вищого рівня порівняно із засобами реалізації віртуальної пам’яті.
З іншого боку, деякі з цих алгоритмів можна використати для реалізації розподілу не тільки логічної, але й неперервної фізичної пам’яті, зокрема й для потреб ядра системи. У цьому розділі йтиметься саме про такі алгоритми на прикладах динамічного розподілу пам’яті ядром Linux і Windows XP.
10.1. Динамічна ділянка пам’яті процесу
Динамічна ділянка пам’яті процесу відображає спеціальну частину його адресного простору, у якій відбувається розподіл пам’яті за запитами з його коду (подібно до виклику mallос() для виділення пам’яті або free() для її вивільнення). Такий розподіл пам’яті відбувається в режимі користувача, звичайно в коді системних бібліотек (цей розподіл відбувається всередині динамічної ділянки, і ядро в ньому участі не бере).
Такі операції у більшості випадків не ведуть до зміни розмірів динамічної ділянки, але якщо така зміна необхідна (наприклад, якщо вільного місця в динамічній ділянці не залишилося), ОС пропонує для цього спеціальний системний виклик. В UNIX-системах його зазвичай називають brk(). Його пряме використання у прикладних програмах не рекомендоване, хоч і можливе.
Динамічний розподіл пам’яті відбувається на двох рівнях. Спочатку ядро резервує динамічну ділянку пам’яті процесу за системним викликом brk(). Потім усередині цієї ділянки процеси користувача можуть розподіляти пам’ять, викликаючи стандартні функції типу mallос() і free(). У разі потреби динамічну ділянку можна розширювати далі або скорочувати (знову-таки за допомогою виклику brk()).
10.2. Особливості розробки розподілювачів пам’яті
Розподілювач пам’яті (memory allocator) – частина системної бібліотеки або ядра системи, відповідальна за динамічний розподіл пам’яті.
Головним завданням такого розподілювача є відстеження використання процесом ділянок пам’яті в конкретний момент. Основними цілями роботи розподілювача є мінімізація втраченого внаслідок фрагментації простору і витрат часу на виконання операцій (ці характеристики є основними критеріями порівняння алгоритмів розподілу пам’яті). При цьому розподілювач має враховувати принцип локальності (блоки пам’яті, які використовуються разом, виділяються поруч один з одним).
Сучасні розподілювачі пам’яті не можуть задовольнити всі ці вимоги і є певною мірою компромісними рішеннями. Доведено, що для будь-якого алгоритму розподілу пам’яті А можна знайти алгоритм В, що за відповідних умов буде кращим за продуктивністю, ніж А. На практиці, однак, можуть бути розроблені алгоритми, які використовують особливості поведінки реальних програм і працюють в основному добре.
Звичайні розподілювачі не можуть контролювати розмір і кількість використовуваних блоків пам’яті: цим займаються процеси користувача, а розподілювач просто відповідає на їхні запити. Крім того, розподілювач не може займатися дефрагментацією пам’яті (переміщенням її блоків для того щоб зробити вільну пам’ять неперервною), оскільки для нього недопустимо змінювати покажчики на пам’ять, виділену процесові користувача (цей процес має бути впевнений у тому, що адреси, які він використовує, не змінюватимуться без його відома). Якщо було ухвалене рішення про виділення блоку пам’яті, цей блок залишається на своєму місці доти, поки застосування не вивільнить його явно. Розподілювач фактично має справу тільки із вільною пам’яттю, основне рішення, яке він має приймати – де виділити наступний потрібний блок.
10.2.1. Фрагментація у разі динамічного розподілу пам’яті
Динамічний розподіл пам’яті може спричиняти зовнішню та внутрішню фрагментацію. Саме ступінь фрагментації є основним критерієм оцінки розподілювачів пам’яті. Фрагментація виникає з двох причин.
Різні об’єкти мають різний час життя (якщо об’єкти, що перебувають у пам’яті поруч, вивільняються в різний час). Розподілювачі пам’яті можуть використати цю закономірність, виділяючи пам’ять так, щоб об’єкти, які можуть бути знищені одночасно, розташовувалися поруч.
Різні об’єкти мають різний розмір. Якби всі запити вимагали виділення пам’яті одного розміру, зовнішньої фрагментації не було б (цього ефекту домагаються, наприклад, при використанні сторінкової організації пам’яті). Для боротьби із внутрішньою фрагментацією більшість розподілювачів пам’яті розділяють блоки пам’яті на менші частини, виділяють одну з них і далі розглядають інші частини як вільні. Крім того, часто використовують злиття сусідніх вільних блоків, щоб задовольняти запити на блоки більшого розміру.
10.2.2. Структури даних розподілювачів пам’яті
Найпростіший підхід до динамічного розподілу пам’яті реалізований у системному виклику brk(). Він може бути виконаний надзвичайно ефективно, тому що для його реалізації достатньо зберегти покажчик на початок вільної динамічної ділянки пам’яті та збільшувати його після кожної операції виділення пам’яті (рис. 10.1). На жаль, реалізувати вивільнення пам’яті на основі такого виклику неможливо, оскільки воно не може бути виконане послідовно в порядку, зворотному до виділення пам’яті. У результаті після вивільнення пам’яті в ній з’являтимуться «діри» (зовнішня фрагментація).
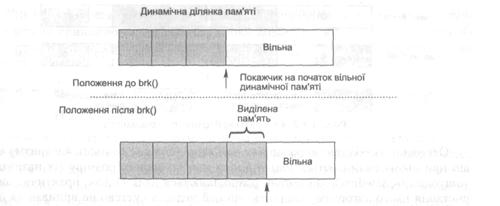
Рис. 10.1. Зміна розміру динамічної ділянки пам’яті
Покажчик, який використовується brk(), є найпростішим прикладом структури даних розподілювача пам’яті.
Складніші розподілювачі потребують складніших структур даних. Відстеження вільного простору у пам’яті може відбуватися за допомогою бітових карт, де кожний біт відповідає ділянці пам’яті (якщо він дорівнює одиниці, ця ділянка пам’яті зайнята, якщо нулю – вільна), або зв’язних списків зайнятих і вільних ділянок пам’яті, де кожний елемент списку містить індикатор зайнятості ділянки пам’яті та довжину цієї ділянки.
10.3. Послідовний пошук підходящого блоку
Розглянемо конкретні підходи до реалізації динамічного розподілу пам’яті. Спочатку зупинимося на алгоритмах, які зводяться до послідовного перегляду вільних блоків системи і вибору одного з них. Такі алгоритми відомі досить давно і докладно описані в літературі [41, 44, 109]. До цієї групи належать алгоритми найкращого підходящого (best fit), першого підходящого (first fit), наступного підходящого (next fit) і деякі інші, близькі до них. Ця група алгоритмів дістала назву алгоритми послідовного пошуку підходящого блоку (sequential fits).
10.3.1. Алгоритм найкращого підходящого
Алгоритм найкращого підходящого зводиться до виділення пам’яті із вільного блоку, розмір якого найближчий до необхідного обсягу пам’яті. Після такого виділення у пам’яті залишатимуться найменші вільні фрагменти. Структури даних вільних блоків у цьому випадку можуть об’єднуватися у список, кожний елемент якого містить розмір блоку і покажчик на наступний блок. Під час вивільнення пам’яті має сенс поєднувати суміжні вільні блоки.

Рис. 10.2. Алгоритм найкращого підходящого
Основною особливістю розподілу пам’яті відповідно до цього алгоритму є те, що при цьому залишаються вільні блоки пам’яті малого розміру (їх називають «ошурками», sawdust), які погано розподіляються далі. Однак, практичне використання цього алгоритму свідчить, що цей недолік суттєво не впливає на його продуктивність.
10.3.2. Алгоритм першого підходящого
Алгоритм першого підходящого полягає в тому, що вибирають перший блок, що підходить за розміром (рис. 10.3). Структури даних для цього алгоритму можуть бути різними: стек (LIFO), черга (FIFO), список, відсортований за адресою. Алгоритм зводиться до сканування списку і вибору першого підхожого блоку. Якщо блок значно більший за розміром, ніж потрібно, він може бути розділений на кілька блоків. Різні модифікації цього алгоритму на практиці виявляють себе по-різному.
Так, алгоритм першого підходящого, який використовує стек, зводиться до того, що вивільнений блок поміщають на початок списку (вершину стека). Такий підхід простий у реалізації, але може спричинити значну фрагментацію. Прикладом такої фрагментації є ситуація, коли одночасно виділяють більші блоки пам’яті на короткий час і малі блоки – на довгий. У цьому разі вивільнений великий блок буде, швидше за все, відразу використаний для виділення пам’яті відповідно до запиту на малий обсяг (і після цього не вивільниться найближчим часом).
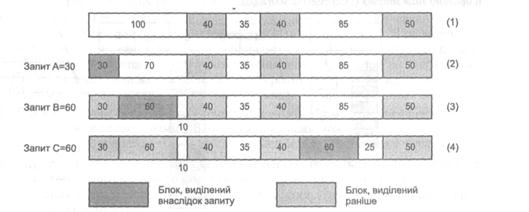
Рис. 10.3. Алгоритм першого підходящого
З іншого боку, така проблема не виникає, якщо список вільних блоків організовують за принципом FIFO (вільні блоки додають у кінець цього списку) або впорядковують за адресою. Ці модифікації алгоритму першого підходящого використовують найчастіше.
10.3.3. Порівняння алгоритмів послідовного пошуку підходящого блоку
З погляду фрагментації алгоритми найкращого підходящого та першого підходящого практично рівноцінні (фрагментацію за умов реального навантаження підтримують приблизно на рівні 20 %). Такий результат може здатися досить несподіваним, оскільки в основі цих алгоритмів лежать різні принципи. Можливе пояснення полягає в тому, що у разі використання алгоритму першого підходящого список вільних блоків згодом стає впорядкованим за розміром (блоки меншого розміру накопичуються на початку списку), тому для невеликих об’єктів (а саме такі об’єкти здебільшого виділяє розподілювач) він працює майже так само, як і алгоритм найкращого підходящого.
Алгоритм першого підхожого звичайно працює швидше, оскільки пошук найкращого підходящого вимагає перегляду всього списку вільних блоків.
Головним недоліком алгоритмів послідовного пошуку вільних блоків є їхня недостатня масштабованість у разі збільшення обсягу пам’яті. Що більше пам’яті, то довшими стають списки, внаслідок чого зростає час їхнього перегляду.
10.4. Ізольовані списки вільних блоків
Інший важливий клас алгоритмів динамічного розподілу пам’яті зводиться до організації списків вільних блоків у структуру даних, що містить масив розмірів блоків, причому кожен елемент масиву пов’язаний зі списком описувачів вільних блоків (рис. 10.4). Пошук потрібного блоку зводиться до пошуку потрібного розміру в масиві та вибору елемента із відповідного списку. Таку технологію називають технологією ізольованих списків вільних блоків (segregated free lists) або ізольованою пам’яттю (segregated storage).
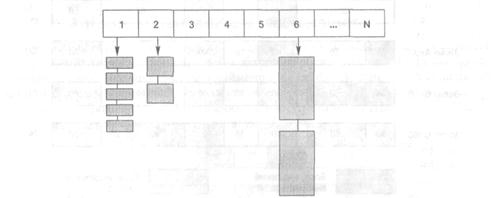
Рис. 10.4. Ізольовані списки вільних блоків
Розрізняють два базові підходи до організації такого виду списків: проста ізольована пам’ять (simple segregated storage) та ізольований пошук підходящого блоку (segregated fits).
10.4.1. Проста ізольована пам’ять
У разі використання цього підходу поділу більших блоків не відбувається, щоб задовольнити запит на виділення блоку меншого розміру. Коли під час обслуговування запиту на виділення пам’яті з’ясовують, що список вільних блоків цього розміру порожній, видають запит операційній системі на розширення динамічної ділянки пам’яті (наприклад, через системний виклик brk()). Після цього виділені сторінки розбивають на блоки одного розміру, які й додають у відповідний список вільних блоків. У результаті сторінка пам’яті завжди містить блоки одного розміру.
Основними перевагами такого підходу є те, що немає необхідності зберігати для кожного об’єкта інформацію про його розмір. Тепер така інформація може бути збережена для цілої сторінки об’єктів, що особливо вигідно тоді, коли розмір об’єкта малий і на сторінці таких об’єктів міститься багато.
Продуктивність цього підходу досить висока, особливо через те, що об’єкти одного розміру постійно виділяють і вивільняють упродовж малого періоду часу.
Головним недоліком простої ізольованої пам’яті є доволі відчутна зовнішня фрагментація. Не робиться жодних спроб змінювати розмір блоків (розбивати на менші або поєднувати) для того щоб задовольняти запити на блоки іншого розміру. Наприклад, якщо програма запитуватиме блоки тільки одного розміру, система із вичерпуванням їхнього запасу розширюватиме динамічну пам’ять, незважаючи на наявність вільних блоків інших розмірів. Одним із компромісних підходів є відстеження кількості об’єктів, виділених на кожній сторінці, і вивільнення сторінки (можливо, для подальшого розміщення об’єктів іншого розміру) у разі відсутності об’єктів.
10.4.2. Ізольований пошук підходящого блока
Цей підхід також підтримує структуру даних, що складається із масиву списків вільних блоків, але організація пошуку виглядає інакше. Пошук у масиві відбувається за правилами для послідовного пошуку підходящого блоку. Якщо блок потрібного розміру не знайдено, алгоритм намагається знайти блок більшого розміру і розбити його на менші. Запит на розширення динамічної ділянки пам’яті виконують лише тоді, коли жоден блок більшого розміру знайти не вдалося. Розрізняють три категорії підходів ізольованого пошуку підхожого блоку.
Під час використання підходу точних списків підтримують масив списків для кожного можливого розміру блоку. Такий масив може бути досить великим, але достатньо зберігати тільки ті його елементи, для яких справді задані списки.
Підхід точних класів розмірів із заокругленням зводиться до зберігання в масиві обмеженого набору розмірів (наприклад, ступенів числа 2) і пошуку найближчого підходящого. Цей підхід ефективніший, але більш схильний до внутрішньої фрагментації.
Підхід класів розмірів зі списками діапазонів зводиться до того, що в кожному списку містяться описувачі вільних блоків, довжина яких потрапляє в деякий діапазон. Це означає, що блоки у списку можуть бути різного розміру (у межах діапазону). Для пошуку у списку використовують алгоритм найкращого підходящого або першого підходящого.
10.5. Системи двійників
Система двійників (buddy system) [41, 109] – підхід до динамічного розподілу пам’яті, який дає змогу рідше розбивати на частини більші блоки для виділення пам’яті під блоки меншого розміру, знижуючи цим зовнішню фрагментацію. Вона містить у собі два алгоритми: виділення та вивільнення пам’яті. Розглянемо найпростішу бінарну систему двійників (binary buddy system).
У разі використання цієї системи пам’ять розбивають на блоки, розмір яких є степенем числа 2: 2К, L £ К £ U, де 2L – мінімальний розмір блоку; 2U – максимальний розмір блоку (він може бути розміром доступної пам’яті, а може бути й меншим).
Алгоритм виділення пам’яті
Опишемо принцип роботи алгоритму виділення пам’яті.
- Коли надходить запит на виділення блоку пам’яті розміру М, відбувається пошук вільного блоку підходящого розміру (такого, що 2К-1 £ М £ 2К). Якщо блок такого розміру є, його виділяють. У разі відсутності блоку такого розміру беруть блок розміру 2К+1 ділять навпіл на два блоки розміру 2К і перший із цих блоків виділяють; другий залишається вільним і стає двійником (buddy) першого. Робота алгоритму на цьому завершується.
- За відсутності блоку розміром 2К+1 беруть найближчий вільний блок, більший за розміром від М, наприклад блок розміру 2К+N. Він стає поточним блоком. Якщо немає жодного блоку, більшого за М, повертають помилку.
- Після цього починають рекурсивний процес розподілу блоку. На кожному кроці цього процесу поточний блок ділиться навпіл, два отриманих блоки стають двійниками один одного, після цього перший із них стає поточним (і ділиться далі), а другий залишають вільним і надалі не розглядають. Для блоку розміру 2K+N процес завершують через N кроків поділу отриманням двох блоків розміру 2К. Перший із цих блоків виділяють, другий залишають вільним. Внаслідок поділу отримують N пар блоків-двійників.
Для ілюстрації цього алгоритму наведемо приклад (рис. 10.5).
Припустимо, що в системі є вільний блок розміром 512 Кбайт (1) і надійшов запит на виділення блоку на 100 Кбайт (блоку А).
Ділимо блок на два по 256 Кбайт, з них перший робимо поточним, а другий залишаємо його двійником (2). Після цього знову ділимо перший блок на два по 128 Кбайт. Це – потрібний розмір, тому виділяємо для А перший із цих блоків, а другий залишаємо його двійником (3). Тепер маємо один вільний блок на 128 Кбайт (двійник виділеного блоку) і один – на 256 Кбайт. У результаті для блоку А виділено 128 Кбайт.
Тепер надходить запит на виділення блоку на 30 Кбайт (блоку В). У цьому разі найближчим за розміром більшим вільним блоком буде блок на 128 Кбайт; система розділить його на два двійники по 64 Кбайт (4), а потім перший з них – на два по 32 Кбайт. Це – потрібний розмір, тому для В буде виділено перший із цих блоків, а другий залишать його двійником (5). У результаті для блоку В виділено 32 Кбайт.
Нарешті, надходить запит на виділення блоку на 200 Кбайт (блоку С). У цьому разі є підходящий блок на 256 Кбайт, тому його негайно виділяють (6).
Алгоритм вивільнення пам’яті
Алгоритм вивільнення пам’яті використовує утворення двійників у процесі виділення пам’яті (насправді двійниками можуть вважатися будь-які два суміжні блоки однакового розміру).
- Заданий блок розміру 2К вивільняють.
- Коли цей блок має двійника і він вільний, їх об’єднують в один блок удвічі більшого розміру 2К+1.
- Якщо блок, отриманий на кроці 2, має теж двійника, їх об’єднують у блок розміру 2К+2.
- Цей процес об’єднання блоків повторюють доти, поки не буде отримано блок, для якого не знайдеться вільного двійника.
Розглянемо, як вивільнятиметься пам’ять у наведеному раніше прикладі.
- Спочатку вивільнимо пам’ять з-під блоку В. Для нього є вільний двійник, тому їх об’єднують в один блок розміру 64 Кбайт.
- Для цього блоку також є вільний двійник (див. (4)), і їх теж об’єднують у блок розміру 128 Кбайт (7).
- Тепер вивільняють пам’ять з-під блоку С. Він вільних двійників не має, тому об’єднання не відбувається (8).
- Нарешті вивільняють пам’ять з-під блоку А. Його об’єднують із двійником у блок розміру 256 Кбайт, але в того теж є вільний двійник (вивільнений з-під С), його об’єднують з тим; у результаті знову виходить один вільний блок на 512 Кбайт (9).
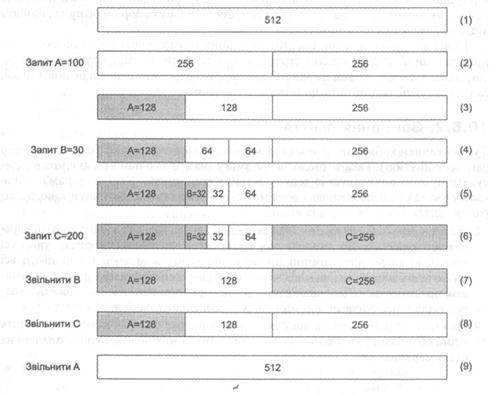
Рис. 10.5. Система двійників
Переваги і недоліки системи двійників
Цей підхід за продуктивністю випереджає інші алгоритми динамічного розподілу, він особливо ефективний для великих масивів пам’яті. Головним його недоліком є значна внутрішня фрагментація (як можна помітити, у наведеному прикладі було виділено на 86 Кбайт пам’яті більше, ніж потрібно), тому для розподілу блоків малого розміру частіше використовують інші підходи, зокрема розглянуті раніше методи послідовного пошуку або ізольованих списків вільних блоків.
10.6. Підрахунок посилань і збирання сміття
Опишемо реалізацію вивільнення пам’яті, зайнятої об’єктами. Основна проблема, що виникає при цьому, пов’язана із необхідністю відслідковувати використання кожного об’єкта у програмі. Це потрібно для того щоб визначити, коли можна вивільнити пам’ять, яку займає об’єкт. Для реалізації такого відстеження використовують два основні підходи: підрахунок посилань (reference counting) і збирання сміття (garbage collection).
10.6.1. Підрахунок посилань
Підрахунок посилань зводиться до того, що для кожного об’єкта підтримують внутрішній лічильник, збільшуючи його щоразу при заданні на нього посилань і зменшуючи при їх ліквідації. Коли значення лічильника дорівнює нулю, пам’ять з-під об’єкта може бути вивільнена.
Цей підхід добре працює для структур даних з ієрархічною організацією і менш пристосований до рекурсивних структур (можуть бути ситуації, коли кілька об’єктів мають посилання один на одного, а більше жоден об’єкт із ними не пов’язаний; за цієї ситуації такі об’єкти не можуть бути вивільнені).
10.6.2. Збирання сміття
Тут розглянемо збирання сміття із маркуванням і очищенням (mark and sweep garbage collection). Така технологія дає змогу знайти всю пам’ять, яку може адресувати процес, починаючи із деяких заданих покажчиків. Усю іншу пам’ять при цьому вважають недосяжною, і вона може бути вивільнена. Алгоритм такого збирання сміття виконують у два етапи.
- На етапі маркування виділяють спеціальні адреси пам’яті, які називають кореневими адресами. Як джерела для таких адрес звичайно використовують усі глобальні та локальні змінні процесу, які є покажчиками. Після цього всі об’єкти, які містяться у пам’яті за цими кореневими адресами, спеціальним чином позначаються. Далі аналогічно позначають всю пам’ять, яка може бути адресована покажчиками, що містяться у позначених раніше об’єктах, і т. д.
- На етапі збирання сміття деякий фоновий процес (збирач сміття) проходить всіма об’єктами і вивільняє пам’ять з-під тих із них, які не були позначені на етапі маркування.
10.7. Реалізація динамічного керування пам’яттю в Linux
У цьому розділі опишемо особливості динамічного керування пам’яттю Linux.
Спочатку зупинимося на динамічному розподілі пам’яті ядром системи. Як зазначалося, деяку частину фізичної пам’яті ядро використовує для розміщення свого коду і його статичних структур даних. Цю пам’ять називають статичною пам’яттю, вона закріплена за ядром постійно, відповідні фрейми не можуть бути вивільнені. Уся інша пам’ять є динамічною і може бути розподілена на вимогу. Тут охарактеризуємо деякі методи, які використовуються ядром для реалізації такого розподілу.
10.7.1. Розподіл фізичної пам’яті ядром
Для динамічного розподілу великих блоків фізичної пам’яті (за розміром кратних фрейму) у Linux використовують систему двійників. Використання таких блоків дає змогу знизити необхідність модифікації таблиць сторінок під час роботи застосування, а це, в свою чергу, знижує ймовірність очищення кеша трансляції.
Розподіл об’єктів ядром
Алгоритм двійників не підходить для розподілу блоків пам’яті довільного розміру, оскільки мінімальний обсяг пам’яті, який він може виділити або вивільнити, становить один фрейм (4 Кбайт), що спричиняє значну внутрішню фрагментацію. Для розподілу пам’яті під окремі об’єкти застосовують кусковий розподілювач (slab allocator) [5, 61, 74]. При його розробці намагаються організувати кешування часто використовуваних об’єктів ядра в ініціалізованому стані (оскільки більша частина часу під час розміщення об’єкта витрачається на його ініціалізацію, а не на саме виділення пам’яті), а також виділення пам’яті блоками малого розміру без внутрішньої фрагментації, властивої алгоритму системи двійників.
Кеші об’єктів та їхні види
Структура даних кускового розподілювача складається зі змінної кількості кешів об’єктів, об’єднаних у двозв’язний циклічний список, який називають ланцюжком кешів. Кожний такий кеш відповідає за розподіл об’єктів конкретного типу або конкретного розміру.
Розрізняють два види кешів об’єктів.
Спеціалізовані кеші, які створюють різні компоненти ядра системи для зберігання об’єктів конкретного типу. Для таких кешів звичайно задають конструктор і деструктор, а також унікальне ім’я, що залежить зазвичай від типу об’єкта. Під конструктором розуміють функцію, яку викликають під час ініціалізації об’єктів цього типу, під деструктором – функцію, яку викликають під час вивільнення пам’яті з-під об’єкта. Прикладом можуть бути такі кеші, як uid_cache (кеш ідентифікаторів користувачів), vm_area_struct (кеш дескрипторів регіонів) тощо. Компоненти режиму ядра (наприклад, драйвери пристроїв) можуть створювати додаткові кеші для своїх об’єктів.
Кеші загального призначення, які використовують для зберігання блоків пам’яті довільного призначення конкретного розміру. Є кеші для блоків розміром від 25 = 32 біт до 217 = 131072 біт, їх називають size–N (N – розмір блоку кеша у байтах, наприклад, size–128).
Кускові блоки
Пам’ять для кеша виділяють у вигляді кускових блоків (slabs). Кусковий блок складається із одного або кількох неперервно розташованих фреймів пам’яті, розділених на фрагменти пам’яті (chunks) одного розміру, які містять об’єкти (рис. 10.6). Розмір фрагмента пам’яті залежить від типу кеша, для якого виділяють кусковий блок (він дорівнює розміру об’єкта, екземпляри якого потрібно розподіляти за допомогою цього кеша). Використання таких блоків для розподілу пам’яті знижує як зовнішню, так і внутрішню фрагментацію.
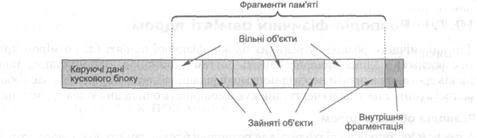
Рис. 10.6. Структура кускового блоку розподілювача об’єктів Linux
Під час створення кусковий блок негайно розділяють на певну кількість фрагментів, при цьому, якщо для відповідного кеша був заданий конструктор, його викликають для ініціалізації всіх виділених фрагментів, які перетворюються на ініціалізовані й готові до використання об’єкти. Після цього запит на виділення пам’яті під відповідний об’єкт може бути негайно задоволений, при цьому фактично ані виділення пам’яті, ані ініціалізації не відбувається (об’єкт просто позначають як виділений).
За запитом на вивільнення пам’яті об’єкт позначають як вивільнений, але з кускового блоку не вилучають і деструктор для нього не викликають; згодом його можна використати знову. Деструктор для всіх об’єктів блоку викликають тільки під час справжнього вивільнення пам’яті з-під кускового блоку або всього кеша. Зазначимо, що таке вивільнення відбувається тільки тоді, коли в цьому блоці не виділено жодного об’єкта, а система відчуває нестачу пам’яті.
Із поточним станом кешів об’єктів можна ознайомитися, виконавши команду
$ cat /proc/slabinfo
Внаслідок її виконання буде відображена таблиця, стовпчиками якої є ім’я кеша, кількість розміщених об’єктів, кількість усіх об’єктів у кускових блоках, розмір об’єкта, кількість непорожніх кускових блоків, загальна кількість кускових блоків і кількість фреймів у блоці:
vm_area_struct 1060 1180 64 20 20 1
size-8192 З З 8192 3 3 2
size-32 5607 6215 32 50 55 1
10.7.2. Керування динамічною ділянкою пам’яті процесу
Кожний процес має доступ до спеціальної ділянки пам’яті, яку називають динамічною ділянкою пам’яті, або кучею (heap). Початкова і кінцева адреси цієї ділянки містяться в полях start_brk і brk дескриптора пам’яті процесу.
Для доступу до динамічної ділянки пам’яті використовують системний виклик brk(). Він намагається змінити її розмір, за параметр приймає нову кінцеву адресу цієї ділянки.
#include <unistd.h>
int brk(void *new_brk);
Зміна може зводитися до розширення або скорочення динамічної ділянки пам’яті. У разі збільшення ділянки, виконують різні перевірки (чи коректна нова адреса, чи дозволено процесу використати такий обсяг пам’яті) і після цього виділяють новий інтервал адрес, як описано у розділі 9.8.1, у разі зменшення, зайву пам’ять вивільняють. Якщо виклик brk() завершився коректно, поле brk дескриптора пам’яті відображатиме новий розмір динамічної ділянки.
Виклик brk() мало підходить для безпосереднього використання у прикладних програмах, оскільки з його допомогою не можна визначити поточне значення межі brk. На практиці як засіб керування межею динамічної ділянки використовують пакувальник цього виклику – функцію sbrk().
#include <unistd.h>
void *sbrk(ptrdiff_t increment):
Вона переміщує межу динамічної ділянки на ціле число байтів increment і повертає покажчик на початок виділеної ділянки (фактично, старе значення межі). Якщо increment дорівнює нулю, sbrk() повертає поточне значення межі динамічної ділянки пам’яті.
char *oldbrk, *newbrk;
//переміщення межі динамічної ділянки
oldbrk = (char *)sbrk(10000);
//визначення нової межі динамічної ділянки
newbrk = (char *)sbrk(0);
printf(‘’Старе значення brk: %d, нове: %d\n”, oldbrk, newbrk);
Із використанням виклику brk () у бібліотеці мови С для Linux реалізовані стандартні функції роботи із динамічною пам’яттю malloc(), calloc() і realloc(). Зазначимо, під час виклику цих функцій у режимі ядра відбувається тільки зміна brk на величину, кратну 4 Кбайт (у разі необхідності), подальше виділення фрагмента пам’яті потрібного розміру здійснюють у режимі користувача.
10.8. Реалізація динамічного керування пам’яттю в Windows XP
Windows XP реалізує два способи динамічного розподілу пам’яті для використання в режимі ядра: системні пули пам’яті (system memory pools) і списки передісторії (look-aside lists).
10.8.1. Системні пули пам’яті ядра
Розрізняють невивантажувані (nonpaged) і вивантажувані (paged) системні пули пам’яті. Обидва види пулів перебувають у системній ділянці пам’яті та відображаються в адресний простір будь-якого процесу.
Невивантажувані містять діапазони адрес, які завжди відповідають фізичній пам’яті, тому доступ до них ніколи не спричиняє сторінкового переривання.
Вивантажувані відповідають пам’яті, сторінки якої можуть бути вивантажені на диск. Обидва види системних пулів можна використати для виділення блоків пам’яті довільного наперед невідомого розміру.
10.8.2. Списки передісторії
Списки передісторії є швидшим способом розподілу пам’яті і багато в чому схожі на кеші кускового розподілювача Linux.
Вони дають змогу виділяти пам’ять для блоків одного наперед відомого розміру. Звичайно їх спеціально створюють для виділення часто використовуваних об’єктів (наприклад, такі списки формують різні компоненти виконавчої системи для своїх структур даних). Як і для кешів кускового розподілювача, є списки загального призначення для виділення блоків заданого розміру. У разі вивільнення об’єктів вони повертаються назад у відповідний список. Якщо список довго не використовували, його автоматично скорочують.
10.8.3. Динамічні ділянки пам’яті
У Windows XP, як і в Linux, кожний процес має доступ до спеціальної ділянки пам’яті, її також називають динамічною ділянкою пам’яті або кучею (heap). Особливістю цієї ОС є те, що таких динамічних ділянок для процесу може бути створено кілька, і всередині кожної з них розподілювач пам’яті може окремо виділяти блоки меншого розміру [31, 50].
Розподілювач пам’яті у Windows XP називають менеджером динамічних ділянок пам’яті (heap manager). Цей менеджер дає змогу процесам розподіляти пам’ять блоками довільного розміру, а не тільки кратними розміру сторінки, як під час керування регіонами.
Кожний процес запускають із динамічною ділянкою за замовчуванням, розмір якої становить 1 Мбайт (під час компонування програми цей розмір може бути змінений). Для роботи із цією ділянкою процес має спочатку отримати її дескриптор за допомогою виклику GetProcessHeap().
HANDLE default_heap = GetProcessHeap();
Виділення блоків пам’яті
Для виділення блоків пам’яті використовують функцію НеарAlloc(), для вивільнення – HeapFree().
//виділення в ділянці heap блоку пам’яті розміру size
LPVOID addr = HeapAlloc(heap. options, size);
// вивільнення в ділянці heap блоку пам’яті за адресою addr
HeapFree(heap, options, addr);
Першим параметром для цих функцій є дескриптор динамічної ділянки, одним із можливих значень параметра options для НеарАlloc() є HEAP_ZERO_MEMORY, який свідчить, що виділена пам’ять буде ініціалізована нулями.
Додаткові динамічні ділянки
Для своїх потреб процес може створювати додаткові динамічні ділянки за допомогою функції HeapCreate() і знищувати їх за допомогою HeapDestroy(). Функція HeapCreate() приймає три цілочислові параметри і повертає дескриптор створеної ділянки.
HANDLE heap = HeapCreate(options, initial_size, max_size);
Перший параметр задає режим створення ділянки (нульове значення задає режим за замовчуванням), другий – її початковий розмір, третій – максимальний. Якщо max_size дорівнює нулю, динамічна ділянка може збільшуватися необмежене. Задання ділянок обмеженого розміру дає змогу уникнути помилок, пов’язаних із втратами пам’яті (втрата у кожному разі не зможе перевищити максимального розміру ділянки).
Розглянемо приклад використання додаткової динамічної ділянки пам’яті для розміщення масиву зі 100 елементів типу Int.
int array_size = 100 * sizeof(int);
//розміщення динамічної ділянки
HANDLE heap – HeapCreate(0,. array_size, array_size);
//розміщення масиву в цій ділянці, заповненого нулями
int *array = (int *)HeapAlloc(heap, HEAP_ZERO_MEMORY, array_size);
//робота із масивом у динамічній ділянці
аггау[20] = 1;
//знищення динамічної ділянки та вивільнення пам’яті
HeapDestroy(heap);
Зазначимо, що виклик HeapFree() у цьому прикладі не потрібний, тому що виклик HeapDestroy() призводить до коректного вивільнення всієї пам’яті, виділеної в heap. Це є однією із переваг використання окремих динамічних ділянок.
Висновки
Динамічний розподіл пам’яті – це керування ділянкою пам’яті, якою процес може розпоряджатися на свій розсуд. Засоби керування динамічною пам’яттю працюють винятково з логічними адресами і ґрунтуються на реалізації віртуальної пам’яті. Основною проблемою динамічного розподілу пам’яті є фрагментація. Для боротьби з нею використовують різні підходи.
Найбільш розповсюдженими технологіями динамічного розподілу пам’яті є система двійників, динамічні списки вільних блоків і послідовний пошук підходящого вільного блоку,
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 1812; Нарушение авторских прав?; Мы поможем в написании вашей работы!