КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методологія статистичного аналізу, задачі
|
|
|
|
Основні теоретичні положення.
Тема №4 розглядається в першому модулі курсу «Статистика» та складається з 4-ох навчальних питань:
4.1. Зміст статистичного аналізу.
4.2. Статистичний закон і закономірність.
4.3. Методологія статистичного аналізу.
4.4. Форми відображення статистичної інформації. Статистичні таблиці та графіки.
Зміст статистичного аналізу розглянутий в §4.1 і схематично зображений на рис.4.1-4. Решта питань, які дають уявлення про особливості статистичного аналізу, представлені в цьому параграфі далі, а визначення всіх основних теоретичних положень і термінів – в таблиці 4.
Завжди треба пам’ятати: статистичний аналіз є логічним продовженням узагальнення даних статистичного спостереження, а в його основу покладений метод узагальнюючих статистичних показників (► п.1.9); лише узагальнюючий статистичний показник (► п.4.2) дає уявлення про певну закономірність досліджуваного явища, виявлення якої складає сутність самого аналізу (► п.4.1); статистичний аналіз фундаментально ґрунтується на знаннях теорії ймовірностей і математичної статистики (► рис.1.1); методологічно основними завданнями статистичного аналізу є оцінка параметра (► п.4.24) і перевірка статистичної гіпотези (► п.4.31); знання типових теоретичних статистичних законів (► п.п.4.12, 14, 16, 20-22) є запорукою надійності статистичного аналізу.
Фундаментальними у статистичному аналізі є такі поняття: закон і закономірності, параметр і оцінка, гіпотеза і критерій.
У науковому розумінні поняття «закон» сприймається як об’єктивний факт у його єдності та повторюваності; фізично – це сталий повторюваний зв’язок між явищами, процесами та станом тіл. «Форма загальності в природі – це закон…» [36, 37].
|
|
|
Закономірність – необхідний, суттєвий, постійно повторюваний зв’язок реальних явищ, який визначає етапи та форми процесу становлення, розвитку природних явищ, суспільства і
духовної культури. Розрізняють загальні, специфічні й універсальні закономірності [36, 37].
Статистичне вивчення явищ, як специфічна процедура, побудовано на статистичних законах і закономірностях і, в той же час, масовий характер цих явищ і ймовірнісне походження статистичних оцінок щодо закономірностей їх зміни у часі та просторі роблять статистичний метод універсальним, фундаментом інших професійно орієнтованих галузей знань.
Статистичний закон – виражена в кількісних показниках імовірнісна залежність між досліджуваними явищами.
Статистична закономірність – форма закономірного зв’язку явищ, за якої завбачення, або прогноз, що витікає із цього зв’язку, має імовірнісний характер. Звичайно закономірність статистична протиставляється динамічній закономірності, де прогноз має точний, визначений, однозначний вид. Імовірнісний характер завбачення у статистичних закономірностях обумовлений дією множини випадкових факторів, що утворюють статистичну сукупність. Тому така закономірність виникає як результат взаємодії великої кількості елементів цієї сукупності, де внаслідок взаємної компенсації й урівноваження маси випадковостей виникає необхідність (закон «великих» чисел, діалектично обумовлений єдністю та боротьбою протилежностей: необхідності та випадковості). Отже, статистична закономірність – це закономірність, яка характеризує сукупність у середньому.
Виявлення статистичної закономірності починається лише після систематизації даних (статистичного групування), коли статистична сукупність первинних даних перетворюється у статистичний розподіл або ряд (► п.3.20). Аналіз останніх ґрунтується на поняттях «закон розподілу» (► п.4.4) і «закономірність розподілу» (► п.4.5).
|
|
|
Із різноманіття теоретичних законів теорії ймовірностей (три перші) і математичної статистики (три наступні) найчастіше в практичних задачах застосовуються такі закони:
а) розподілу ймовірностей дискретних випадкових величин:
- біноміальний (розподіл Бернуллі) (► п.4.12),
- Пуассона (розподіл Пуассона) (► п.4.14);
б) розподілу ймовірностей неперервних випадкових величин:
- Гауса (N -розподіл, або нормальний) (► п.4.16),
- Стьюдента (t -розподіл) (► п.4.20),
- Пірсона (χ²-розподіл) (► п.4.21),
- Фішера (F -розподіл) (► п.4.22).
З них три останні є вибірковими розподілами статистик, часто застосовуваних в якості слушних оцінок (► п.4.26) для відповідних параметрів генеральної сукупності, й які за необмеженого збільшення об’єму вибірки наближаються до нормального розподілу (► п.п.4.20/5, 21/5, 22/5). Доводить цей факт центральна гранична теорема (► п.4.23). Кожен з цих трьох вибіркових розподілів є функцією кількості випробувань N, яка через кількість ступенів свободи (► п.4.33) «пояснює» форму кривої цієї функції.
Так, нормальний розподіл є універсальним для характеристики більшості масових соціально-економічних явищ, тому що надійно їх характеризує, навіть якщо вони представлені сукупностями з об’ємом в 20-30 одиниць[14]. Доречним для таких сукупностей є виконання правила «k сігм» (► п.4.19/4): якщо переважна більшість значень ознаки Х із середнім арифметичним значенням 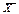 і дисперсією σ групується біля , так, що їх питома вага становить 0,683 в інтервалі від
і дисперсією σ групується біля , так, що їх питома вага становить 0,683 в інтервалі від 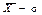 до
до 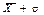 (правило «однієї сігми»), 0,954 в інтервалі від
(правило «однієї сігми»), 0,954 в інтервалі від 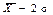 до
до  (правило «двох сігм), 0,997 в інтервалі від
(правило «двох сігм), 0,997 в інтервалі від 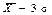 до
до 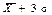 (правило «трьох сігм»), то розподіл ознаки Х в області її визначення можна вважати нормальним (необхідна умова «нормальності» розподілу).
(правило «трьох сігм»), то розподіл ознаки Х в області її визначення можна вважати нормальним (необхідна умова «нормальності» розподілу).
Якщо досліджуване явище представлено статистичною інформацією, обмеженою по кількості первинних даних: або як результат вибіркового обстеження, або певною реалізацією процесу[15], – і результат такого його уявлення необхідно проаналізувати на рівні закономірності, то властивості типових теоретичних законів розподілу ймовірностей випадкової величини (► п.п.4.19, 20/1-2, 21/1-2, 22/1-2) або випадкового процесу у тій же самій формі «розповсюджуються» на узагальнюючі чис-
|
|
|
лові характеристики статистичних розподілів (рядів). Інакше кажучи, формули для обчислення початкових (► п.4.6) і центральних моментів (► п.4.7) розподілів ймовірностей випадкових величин застосовуються для визначення аналогічних узагальнюючих статистичних показників цих рядів: характеристик положення (► п.4.9), розсіювання (► п.4.10), асиметрії й ексцесу (► п.4.11), – які обчислюються по результатах систематизації первинних даних. Сама процедура «розповсюдження» складає сутність методу аналітичного вирівнювання статистичних розподілів (► п.4.29). Пошук закономірностей в такий спосіб називають оцінкою параметра (► п.4.24). Оцінка параметра може бути точковою (числом) й інтервальною (інтервалом, відрізком).
Так, у формулу кривої Гауса (► п.4.16) на місця математичного сподівання m Х і середнього квадратичного відхилення σ Х підставляються значення середнього арифметичногоі середнього квадратичного відхилення σ ознаки Х, тобто розподіл частот цієї ознаки гіпотетично можна уявити як гаусіану з тими ж самими параметрами: m Х = і σ Х = σ.
Поняття «оцінка» трактується як «думка про цінність, рівень чи значення кого- або чого-небудь», а поняття «параметр» розуміють як «величину, яка характеризує певну основну властивість пристрою, системи» [36, 37]. Якщо такою системою стає генеральна сукупність даних про об’єкт статистичного дослідження, а уявлення про нього складається по даних статистичного випробування, які характеризують певний стан цього об’єкта, то справжньою, реальною, числовою характеристикою генеральної сукупності й її наближеним уявленим значенням стають статистичний параметр і його статистична оцінка.
Так само, як і первинна інформація, о цінка параметра має бути надійною (► п.4.25), тобто вона повинна відповідати таким властивостям, як слушність (► п.4.26), незміщеність (► п.4.27) і ефективність (► п.4.28). Пояснюється це тим, що надійні оцінки адекватно [16] (з найменшою похибкою оцінювання (► п.4.26)) описують масові явища з випадковим характером.
|
|
|
У більшості практичних задач, коли об’єм випробувань (вибірки) обмежений (умова «N → ∞» не виконується), важко забезпечити водночас слушність, незміщеність й ефективність оцінки. Тому в статистичному аналізі застосовують поширений науковий принцип «необхідної достатності», що для статистичних оцінок означає: для того, щоб статистична оцінка була достатньо надійною, необхідно, щоб вона була значущою (► п.4.37). Отже, статистичний підхід до такої оцінки буде цілісним, якщо апріорне припущення, або статистична гіпотеза (► п.4.30), про справедливість, або значущість, шуканих закономірностей буде підтверджена із заданим ступенем точності, або на певному рівні значущості α (► п.4.35). А це – вже друге завдання методу статистичного аналізу – перевірка статистичної гіпотези (► п.4.31). Справедливість гіпотези перевіряється за допомогою статистичних критеріїв, або критеріїв статистичної гіпотези (► п.4.32).
Поняття «гіпотеза» означає «наукове припущення, що висувається для пояснення яких-небудь явищ», а поняття «критерій» - «мірило оцінки, судження» [36, 37]. Якщо за певним критерієм перевіряється узгодженість числових характеристик закономірності, вибіркової оцінки і відповідного параметра, то статистичний критерій розуміють як критерій значущості (► п.4.37). Якщо перевіряється можливість застосування гіпотетичних теоретичних розподілів в емпіричних статистичних рядах на рівні імовірності та частоти, статистичний критерій розуміють як критерій згоди (► п.4.40). Говорять, що «статистичний критерій перевіряє (контролює) статистичну гіпотезу на заданому рівні значущості».
Завжди треба пам’ятати: ніколи не слід застосовувати одну й ту саму вибірку для оцінки параметра і перевірки статистичної гіпотези.
Статистичний аналіз не завершується лише обчисленням наближеного числового значення шуканого параметра – точковою оцінкою, яка визнана значущою. Дуже важливо ще оцінити параметр по області (інтервалу) його можливих значень, які у вибіркових випробуваннях називають довірчою областю (► п.4.38) і довірчим інтервалом (► п.4.39) рівня α, а у разі аналізу динамічних змін ознаки або її змін, які відбуваються під
впливом інших, факторних, ознак, ще виконати статистичний прогноз (► п.4.43). Інтервальна оцінка і прогноз виконуються лише для значущих оцінок.
Серед критеріїв, що використовуються для перевірки значущості оцінок, порівняння розподілів, інтервального оцінювання та прогнозування, поширеними є t, χ² і F критерії.
Аналітичне вирівнювання (► п.4.29) статистичного ряду нормальною кривою з перевіркою гіпотези про його «нормальність» за критерієм згоди χ ² (► п.4.41).
Задача №8. Початкові умови. Місячні витрати на купівлю продуктів харчування 200-т обстежених сімей N-ої обл. становили (Х, грн.):
| Х, грн. | 0- | 500- | 1000-1500 | 1500-2000 | 2000-2500 | 2500-3000 | Всього (N): |
| Кількість сімей (f) |
Завдання. Здійснити аналітичне вирівнювання отриманого інтервального ряду гаусіаною з параметрами m = 1550 грн. (середньомісячні грошові витрати обстежених сімей) і σ = 578,79 грн. (СКВ цих витрат) з перевіркою гіпотези про «нормальність» розподілу місячних витрат населення N-ої обл. на купівлю продуктів харчування за одностороннім критерієм згоди χ ² на рівні значущості α = 0,05.
Розв’язок.
1) Побудуємо криву f(Х), що відображає нормально розподілену (► п.4.16) ознаку Х із вказаними параметрами, для чого обчислимо значення f(х) цього розподілу на границях інтервалів х в(н) j , а також його максимальне значення для х =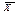 (див. розрахункову таблицю).
(див. розрахункову таблицю).
Розрахункова таблиця
| j | x | x | ||||||
| Х = х н j , грн. | 0,00 | 500,00 | 1000,00 | 1500,00 | 2000,00 | 2500,00 | х в6 = =3000,00 | =
= 1550,00
|
| fj | 10,000 | 20,000 | 60,000 | 70,000 | 30,000 | 10,000 | х | х |
| uj = (xj – m)/σ | -2,678 | -1,814 | -0,950 | -0,086 | 0,777 | 1,641 | 2,505 | 0,000 |
| f(uj) ∙ 10-1 | 0,00306 | 0,14846 | 1,61712 | 3,95969 | 2,17962 | 0,2697 | 0,0075 | 3,9894 |
| [f(xj) = f (uj) /σ]∙10-4, 1/грн. | 0,00529 | 0,25651 | 2,79395 | 6,84131 | 3,76582 | 0,46599 | 0,01296 | 6,89256 |
| [φ j = fj /(n∆)]∙10-4, 1/грн. | 1,00000 | 2,00000 | 6,00000 | 7,00000 | 3,00000 | 1,00000 | x | x |
| F(uj) =(► п.4.17) | 0,00370 | 0,03483 | 0,17099 | 0,46558 | 0,78156 | 0,94964 | 0,99388 | x |
| рj = F(u в j ) – F(u н j ) | 0,03113 | 0,13616 | 0,29459 | 0,31598 | 0,16808 | 0,04424 | x | x |
| Npj | 6,226 | 27,232 | 58,918 | 63,196 | 33,616 | 8,848 | x | x |
Для спрощення обчислення f(х) зручно перейти від значень Х до нової змінної U, нормалізація якої у значеннях функції f(и) (► п.4.17) представлена
статистичними таблицями (► Д.3). Усі розрахунки зведені у таблицю. Гаусіану покажемо разом з гістограмою φ (х) на малюнку.
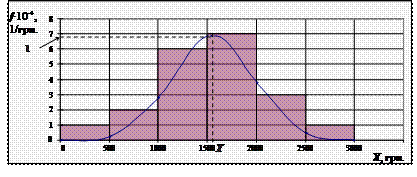
Рис. Аналітичне вирівнювання гаусіаною інтервального розподілу чисельності
обстежених сімей N-ої обл. у залежності від їх місячних грошових витрат
(Х, грн.) на купівлю продуктів харчування у вибірці в 20-ть сімей з
характеристиками = 1550,00 грн. і σ = 578,79 грн.
2) Статистику χ ² = χ ²р. обчислимо через фактичні fj і теоретичні npj значення інтервальної абсолютної частоти (► п.4.41).
Імовірності рj потрапляння нормальних значень ознаки Х в кожен j -й класовий інтервал знайдемо як різницю значень функції розподілу F(u) на верхній u в j і нижній u н j границях інтервалу. Значення функції розподілу на границі інтервалу визначається як сума табличного значення інтегралу ймовірностей Лапласса (► п.4.18, Д.4) для цієї границі і 0,5 (половини загальної площини під нормальною кривою). Для від’ємних значень U зазначена сума віднімається з одиниці (величини загальної площини під нормальною кривою). Усі розрахунки зведені в ту ж саму таблицю.
Теоретичні значення Npj абсолютної частоти внутрішніх інтервалів вищі за 10 одиниць, а крайніх інтервалів – за 5 одиниць, тому класові інтервали можна залишити без зміни.
Отже,
χ ²р. = (10 – 6,226)²/6,226 + (20 – 27,232)²/27,232 + (60 – 58,918)²/58,918 +
+ (70 – 63,196)²/63,196 + (30 – 33,616)²/33,616 + (10 – 8,848)²/8,848 ≈
≈ 5,500.
Критичне значення цієї статистики на рівні значущості α = 0,05 одностороннього χ ²-критерію з m = n – s – 1 = 6 – 2 – 1 = 3 ступенями свободи (табличне, ► Д.5) становить:
χ ²3;1 – 0,05 = 7,815.
Висновок. Порівнюючи розрахункове та критичне значення статистики χ ²: χ ²р. (5,500) < χ ²3;1 – 0,05 (7,815), – можна стверджувати, що гіпотеза про «нормальність» розподілу досліджуваної ознаки є вірною.
Крім нормального розподілу, критерії згоди перевіряють можливість застосування й інших розподілів: розподілу Пуассона, рівномірного розподілу й ін., – як з параметрами, оцінюваними по вибірці, так і без потреби до їх оцінки, як з поєднанням даних в розряди (класові інтервали), так і без цього поєднання.
Порівнюючи можливості різних критеріїв, необхідно враховувати їх особливості. Критерій Пірсона сталий до окремих випадкових похибок в експериментальних даних. Однак його використання потребує групування даних в інтервали, утворення яких може бути суперечливим. До того ж, він застосовується при великих вибірках, об’єму n > 200 (іноді допускається n > 40), коли критерій є слушним[17] (як правило, спростовує невірну нульову гіпотезу).
Якщо вибірка є малою (n < 30), треба застосовувати інші критерії, не критичні до об’ємів випробувань. Поширеним серед таких критеріїв є критерій А.М.Колмогорова (► п.4.42). Хоча він слабо чутливий до виду закону розподілу, зазнає впливу перешкод у початкових даних вибірки, не враховує зменшення кількості ступенів свободи при оцінюванні параметрів розподілу, що завдає ризику прийняття хибної гіпотези, але він є простішим у застосуванні й не потребує групування даних в інтервали.
Перевірка гіпотези про «нормальність» дискретного ряду за критерієм згоди А.М.Колмогорова (► п.4.42).
Задача №9. Завдання. По результатах систематизації даних в п.1) задачі №3:
Х = {500; 600; 700; 800; 1000; 1000; 1200; 1400; 1500; 1500; 1500; 1700; 1800; 1800; 2000; 2000; 2300; 2400; 2700; 3000} (грн.), –
Перевірити за допомогою двостороннього критерію згоди Колмогорова (► п.4.42) на рівні значущості α = 0,05 гіпотезу про те, що місячні витрати сімей N-ої обл. на купівлю продуктів харчування мають нормальний розподіл, якщо середні витрати і СКВ витрат становлять відповідно m = 1570,00 грн. і σ = 681,98 грн.
Розв’язок.
1) По наведених даних побудуймо емпіричну F n (X) (гр. 4 і 5) і теоретичну F(X) (гр. 6) функції розподілу витрат, для чого результати обчислень зведемо в розрахункову таблицю.
n = 20 Розрахункова таблиця
| і | хі, грн. | uj = = (xj – m)/σ | F n (xi) = i / n | F n (xi -1) = = (i – 1)/ n | F(xi) = = F(ui) | F n (xi) – – F(xi) | F(xi) – – F n (xi -1) |
| -1,56896 | 0,05 | 0,00 | 0,05833 | -0,00833 | 0,05833 | ||
| -1,42232 | 0,10 | 0,05 | 0,07747 | 0,02253 | 0,02747 | ||
| -1,27569 | 0,15 | 0,10 | 0,10103 | 0,04897 | 0,00103 | ||
| -1,12906 | 0,20 | 0,15 | 0,12944 | 0,07056 | -0,02056 | ||
| -0,83580 | 0,25 | 0,20 | 0,20163 | 0,04837 | 0,00163 | ||
| -0,83580 | 0,30 | 0,25 | 0,20163 | 0,09837 | -0,04837 | ||
| -0,54254 | 0,35 | 0,30 | 0,29373 | 0,05628 | -0,00628 | ||
| -0,24927 | 0,40 | 0,35 | 0,40158 | -0,00158 | 0,05158 | ||
| -0,10264 | 0,45 | 0,40 | 0,45912 | -0,00912 | 0,05912 | ||
| -0,10264 | 0,50 | 0,45 | 0,45912 | 0,04088 | 0,00912 | ||
| -0,10264 | 0,55 | 0,50 | 0,45912 | 0,09088 | -0,04088 | ||
| 0,19062 | 0,60 | 0,55 | 0,57559 | 0,02441 | 0,02559 | ||
| 0,33725 | 0,65 | 0,60 | 0,63204 | 0,01796 | 0,03204 | ||
| 0,33725 | 0,70 | 0,65 | 0,63204 | 0,06796 | -0,01796 | ||
| 0,63052 | 0,75 | 0,70 | 0,73582 | 0,01418 | 0,03582 | ||
| 0,63052 | 0,80 | 0,75 | 0,73582 | 0,06418 | -0,01418 | ||
| 1,07041 | 0,85 | 0,80 | 0,85778 | -0,00778 | 0,05778 | ||
| 1,21704 | 0,90 | 0,85 | 0,88821 | 0,01179 | 0,03821 | ||
| 1,65693 | 0,95 | 0,90 | 0,95123 | -0,00123 | 0,05123 | ||
| 2,09683 | 1,00 | 0,95 | 0,98180 | 0,01800 | 0,03180 |
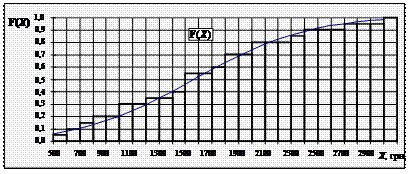
Значення функцій відкладемо на графіку (див рис.).
 |
 2)
2)
 | ||||
 | ||||
 |
Рис. Аналітичне вирівнювання вибіркової функції розподілу F n (X) місячних витрат 20-и
сімей N-ої обл. на купівлю продуктів харчування нормальною кривою теоретичної
функції розподілу F(X) з параметрами m = 1570,00 грн. і σ = 681,98 грн.
Пам’ятаючи, що F(X) = F(U) (► п.4.19/3), значення F(xj) можна визначити, скориставшись методикою попередньої задачі, стандартизуючи змінну Х (гр. 3, ► п.4.17) і нормалізуючи її через інтеграл Лапласса Ф(U) (► п.4.18, Д.4): F(xj) = Ф(иj) + 0,5.
2) Знайдемо в точках Х = хj значення статистики Dn як максимальні значення відхилень F n (X) вверх (гр. 7) і вниз (гр. 8) від F(X): dn + = 0,09837 і dn - = 0,05912 відповідно, – і виберемо з них максимальне – 0,09837.
3) Порівняймо це значення з критичним значенням двостороннього критерію Колмогорова Кn ; α на рівні значущості α = 0,05 (табличне, ► Д.8): К 20; 0,05 = 0,29408.
Висновок. Порівнюючи розрахункове значення статистики Dn та критичне значення критерію: Dn (0,0983) < К 20; 0,05 (0,29408), – можна стверджувати, що гіпотеза про «нормальність» розподілу досліджуваної ознаки є вірною.
Перевіряючи гіпотезу, треба пам’ятати: 1) зайве добра збіжність з обраним законом розподілу може бути обумовлена неякісним експериментом або прискіпливою попередньою обробкою результатів (деякі результати відкидаються або округлюються); 2) вибір критерію згоди відносно довільний, і різні критерії можуть давати різні висновки про справедливість гіпотези, тому остаточний висновок робиться доволі неформально, так само, як немає однозначних рекомендацій щодо вибору рівня значущості; 3) підхід до перевірки гіпотез, оснований на застосуванні спеціальних таблиць критичних точок розподілу, склався за часів «ручної» обробки експериментальних даних, коли наявність таких таблиць значно знижувала трудомісткість розрахунків; сучасні математичні пакети містять процедури обчислення стандартних функцій, що дозволяє відмовитись від використання таблиць і, у свою чергу, може потребувати зміни правил перевірки. Наприклад, гіпотезі Н 0 відповідає таке значення функції розподілу критерію, яке не перевищує значення довірчої ймовірності 1 – α (оцінка статистики критерію відповідає довірчому інтервалу). Зокрема, в задачі №7 значення статистики критерію χ ²р. = 5,5, а значення функції розподілу F(χ ²) для того ж самого значення аргументу при трьох ступенях свободи становить 0,86, що є меншим, ніж 0,95 (1 – α = 1 – 0,05). Отже, немає підстав спростовувати нульову гіпотезу.
|
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 776; Нарушение авторских прав?; Мы поможем в написании вашей работы!