КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Рассмотрим один из наиболее распространенных алгоритмов обучения с учителем, относящийся к правилу коррекции по ошибке. Алгоритм обратного распространения ошибки
|
|
|
|
В многослойных нейронных сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, неизвестны. Трех- или более слойный персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах сети.
Один из вариантов решения этой проблемы – разработка наборов выходных сигналов, соответствующих входным, для каждого слоя нейронной сети, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант – динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Очевидно, что данный метод, несмотря на кажущуюся простоту, требует громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант – распространение сигналов ошибки от выходов нейронной сети к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Этот алгоритм обучения получил название процедуры обратного распространения ошибки (error back propagation). Именно он рассматривается ниже.
Алгоритм обратного распространения ошибки – это итеративный градиентный алгоритм обучения, который используется с целью минимизации среднеквадратичного отклонения текущих от требуемых выходов многослойных нейронных сетей с последовательными связями.
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки нейронной сети является величина:
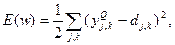 (8.5)
(8.5)
где 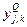 – реальное выходное состояние нейрона у выходного слоя нейронной сети при подаче на ее входы k -го образа; dj,k – требуемое выходное состояние этого нейрона.
– реальное выходное состояние нейрона у выходного слоя нейронной сети при подаче на ее входы k -го образа; dj,k – требуемое выходное состояние этого нейрона.
|
|
|
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация методом градиентного спуска обеспечивает подстройку весовых коэффициентов следующим образом:
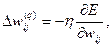 (8.6)
(8.6)
где wij – весовой коэффициент синаптической связи, соединяющей i -й нейрон слоя (q -1) с j -м нейроном слоя q; η – коэффициент скорости обучения, 0 < η <1.
В соответствии с правилом дифференцирования сложной функции:
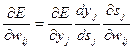 , (8.7)
, (8.7)
где sj – взвешенная сумма входных сигналов нейрона j, т.е. аргумент активационной функции. Так как производная активационной функции должна быть определена на всей оси абсцисс, то функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых нейронных сетей. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой (см. табл.7.1). Например, в случае гиперболического тангенса:
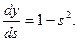 (8.8)
(8.8)
Третий множитель ∂sj / ∂wij равен выходу нейрона предыдущего слоя 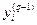 .
.
Что касается первого множителя в (8.7), он легко раскладывается следующим образом:
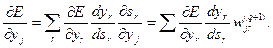 (8.8)
(8.8)
Здесь суммирование по r выполняется среди нейронов слоя (q +1). Введя новую переменную
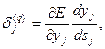 (8.9)
(8.9)
получим рекурсивную формулу для расчетов величин 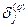 слоя q из величин
слоя q из величин 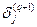 более старшего слоя (q +1):
более старшего слоя (q +1):
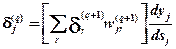 (8.10)
(8.10)
Для выходного слоя:
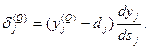 (8.11)
(8.11)
Теперь можно записать (8.6) в раскрытом виде:
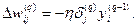 (8.12)
(8.12)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (8.12) дополняется значением изменения веса на предыдущей итерации:
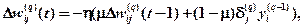 (8.13)
(8.13)
где µ – коэффициент инерционности; t – номер текущей итерации.
Таким образом, полный алгоритм обучения нейронной сети с помощью процедуры обратного распространения строится следующим образом.
ШАГ 1. Подать на входы сети один из возможных образов и в режиме обычного функционирования нейронной сети, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что:
|
|
|
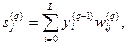 (8.14)
(8.14)
где L – число нейронов в слое (q -1) с учетом нейрона с постоянным выходным состоянием +1, задающего смещение; 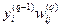 – i -й вход нейрона j слоя q.
– i -й вход нейрона j слоя q.
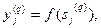 (8.15)
(8.15)
где f (•)-сигмоид,
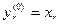 , (8.16)
, (8.16)
где хr – r -я компонента вектора входного образа.
ШАГ 2. Рассчитать δ(Q) для выходного слоя по формуле (8.11).
Рассчитать по формуле (8.12) или (8.13) изменения весов ∆w(Q) слоя Q (последнего слоя).
ШАГ 3. Рассчитать по формулам (8.10) и (8.12) соответственно δ(Q) и ∆w(Q) для всех остальных слоев, q = (Q – 1)…1.
ШАГ 4. Скорректировать все веса в нейронной сети:
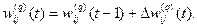 (8.17)
(8.17)
ШАГ 5. Если ошибка сети существенна, перейти на шаг 1. В противном случае – конец.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других.
Из выражения (8.12) следует, что когда выходное значение 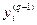 стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться, поэтому область возможных значений выходов нейронов (0, 1) желательно сдвинуть в пределы (-0,5, 0,5), что достигается простыми модификациями логистических функций. Например, сигмоид с экспонентой преобразуется к виду:
стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться, поэтому область возможных значений выходов нейронов (0, 1) желательно сдвинуть в пределы (-0,5, 0,5), что достигается простыми модификациями логистических функций. Например, сигмоид с экспонентой преобразуется к виду:
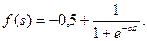 (8.18)
(8.18)
Рассмотрим вопрос о емкости нейронной сети, т.е. числа образов, предъявляемых на ее входы, которые она способна научиться распознавать. Для сетей с числом слоев больше двух этот вопрос остается открытым. Для сетей с двумя слоями детерминистская емкость сети Cd оценивается следующим образом:
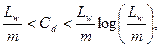 (8.19)
(8.19)
где Lw - число подстраиваемых весов, т - число нейронов в выходном слое.
Данное выражение получено с учетом некоторых ограничений. Во-первых, число входов n и нейронов в скрытом слое L должно удовлетворять неравенству (n+L) > m. Во-вторых, Lw/m > 1000. Однако приведенная оценка выполнена для сетей с пороговыми активационными функциями нейронов, а емкость сетей с гладкими активационными функциями, например (8.18), обычно больше. Кроме того, термин детерминистский означает, что полученная оценка емкости подходит для всех входных образов, которые могут быть представлены n входами. В действительности распределение входных образов, как правило, обладает некоторой регулярностью, что позволяет нейронной сети проводить обобщение и, таким образом, увеличивать реальную емкость. Так как распределение образов, в общем случае, заранее неизвестно, можно говорить о реальной емкости только предположительно, но обычно она раза в два превышает детерминистскую емкость.
|
|
|
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 578; Нарушение авторских прав?; Мы поможем в написании вашей работы!