КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Формы представления числовой информации в ЭВМ
16 10000 10 0001 0110
F 0001 0101
E 0001 0100
D 0001 0011
С 0001 0010
B 0001 0001
А 0001 0000
9 1001 9 1001
8 1000 8 1000
7 111 7 0111
6 110 6 0110
5 101 5 0101
4 100 4 0100
3 11 3 0011
2 10 2 0010
1 1 1 0001
0 0 0 0000
Необходимо особо подчеркнуть, что правила выполнения арифметических операций над многоразрядными числами, представленными в позиционных системах счисления с различными основаниями, одни и те же. Отличие составляют лишь таблицы сложения и умножения одноразрядных чисел.
Рассмотрим пример. Пусть нам необходимо найти произведение двух восьмеричныхчисел Х8 = 35 (это число соответствует десятичному числу 29) и У8 = 12 (это число соответствует десятичному числу 10).
Будем умножать эти числа обычным "столбиком". При умножении будем использовать заранее составленные таблицы умножения и сложения одноразрядных восьмеричных чисел.
| I | I | и | |||||||||||||||||
| I | I | I | б | ||||||||||||||||
Ответ: Х8 х Y8 = 35 х 12 = 4428
| х 35 х 12 * 72 +^- |
Умножая 2 на 5 в восьмеричной системе, получаем результат 128 (см. таблицу 2). Это соответствует 10 в десятичной системе счисления. Следовательно, согласно общеизвестным правилам, в данном разряде записывается число 2, а единица переноса запоминается. Умножая далее 2 на 3, получаем, также как и в десятичной системе счисления, результат "б", а с учетом запомненной единицы переноса записываем цифру 7. Таким образом, результатом умножения восьмеричного числа 35 на цифру 2 будет восьмеричное число 72. Аналогично умножается множимое 35 на следующую цифру множителя (358 х 1=35).
При сложении 728 и 3508 необходимо пользоваться таблицей сложения (табл.3). Так, например, при сложении 7 + 5 получаем число 14. Поэтому в соответствующем разряде записывается цифра 4 и запоминается единица переноса в старший соседний разряд. Окончательный ответ в восьмеричной системе счисления 4428 соответствует десятичному числу 360 (36 х 10).
Мы своими языками сроднились с десятичной системой, и нам не составляет никакого труда произнести вслух любое десятичное число (все наши числительные ориентированы на эту систему). Иное дело числа, записанные в других системах счисления! Попробуйте прочесть вслух восьмеричное число 4428. Это не четыреста сорок два!
Небезынтересно отметить, что исключительная роль десятка при формировании общепринятой системы счисления, несомненно, связано с тем обстоятельством, что при расчетах древние люди пользовались пальцами рук. А их, как известно, десять.
В то же время из истории становления математики известны случаи использования древними народами позиционных систем счисления с другими основаниями. Так, например, в древнем Вавилоне использовалась система счисления с основанием 60. Как отголосок этой системы деление одного часа на 60 минут, а одной минуты на 60 секунд. То же касается и деления угловых градусов на угловые минуты, а угловых минут на угловые секунды.
В английском и немецком языках, в отличие от русского языка, числительные "одиннадцать" и "двенадцать" лингвистически не связаны с числом "десять". Это наталкивает на мысль, что и числа "II" и "12" были когда-то у этих народов основаниями систем счисления.
И лишь позже многочисленные позиционные системы счисления были вытеснены более удобной длятех времен десятичной системой счисления.
Обычный порядок вычислений на ЭВМ таков. Исходные числовые данные вводятся в ЭВМ в обычной для человека десятичной форме (например, с помощью клавиатуры устройства ввода). ЭВМ имеют в своем составе специальные устройства, называемые шифраторами, которые осуществляют автоматический перевод вводимой десятичной информации в двоично-десятичную форму. Затем, по специальному алгоритму, числа из двоично-десятичной формы переводятся в двоичную систему счисления (в некоторых ЭВМ в систему команд включены специальные команды, осуществляющие перевод чиселиз двоично-десятичной системы счисления в двоичную и наоборот).
Все необходимые вычисления, связанные с решением конкретной задачи, производятся в двоичной системе счисления. Если необходимо выдать какие-то результаты вычислений в десятичной системе, то эти данные переводятся сначала в двоично-десятичную форму, а уже затем с помощью устройств, называемых дешифраторами, числа преобразуются в заданную десятичную форму (например, печатаются на бланке принтером или высвечиваются на экране дисплея).
Такой порядок вычислений используется при решении научно-технических задач. В таких задачах количество исходных числовых данных и результатов вычислений сравнительно невелико по сравнению с количеством операций, необходимых для решения задачи.
В то же время имеется большой класс задач, отличающийся обилием входной и выходной информации и требующих для своего решения небольшого числа вычислительных операций (например, начисление зарплаты рабочим и служащим, расчет коммунальных услуг и т.д.). Для таких задач описанный выше порядок вычислений не является оптимальным из-за низкой производительности процессора ЭВМ - слишком много времени процессор будет тратить на многочисленные переводы числовой информации из двоично-десятичной формы в двоичную и наоборот. Для решения указанных задач разработаны специальные методы вычислений непосредственно в двоично-десятичной форме.
В современных ЭВМ общего назначения обязательно присутствуют как группа команд, выполняющих операции в двоичной системе счисления (команды двоичной арифметики - основные команды для любого типа ЭВМ), так и группа команд, выполняющих операции в двоично-десятичной форме (команды десятичной арифметики).
При программировании для представления исходных данных десятичные числа записываются как обычно, а вот при записи чисел в других системах в конце числа ставится спецификатор – буква, которая указывает, в какой системе записано это число: в конце двоичного числа ставится буква b (binary), в конце восьмеричного числа – буква O (octal) или буква q (буква «O» очень похожа на ноль, поэтому для меньшей путаницы рекомендуется использовать букву «q»), а в конце шестнадцатеричного числа – буква h (hexadecimal). Ради общности спецификатор, а именно букву d (decimal), разрешается указывать и в конце десятичного числа, но обычно этого не делают.
Примеры:
Десятичные числа: 25, -386, +4, 25d, -386d Двоичные числа: 101b, -11000b
Восьмеричные числа: 74q, -74q Шестнадцатеричные числа: 1Afh, -1AFh
В ЭВМ используются две формы представления числовой информации; естественная форма (с фиксированной запятой) и полулогарифмическая форма (с плавающей запятой).
Естественная форма характеризуется тем, что местоположение запятой, отделяющей целую часть числа от его дробной части строго фиксировано. Это означает, что если n-разрядное число в каком-то блоке ЭВМ (в памяти или в процессоре) представлено комбинациями n-двухпозиционных элементов, то запятая всегда строго фиксирована после К-ого элемента, т.е. всегда заранее известно, сколько двухпозиционных элементов выделено для изображения целой части числа, и сколько двухпозиционных элементов для изображения его дробной части.
К-ым элементом может быть, в принципе, любой по порядку элемент. На практике, с целью максимального упрощения правил выполнения арифметических операций, используются две основные разновидности естественной формы представления числовой информации.
В первом случае запятая фиксируется перед самым левым цифровым разрядом числа. В этом случае все числа, представимые в машине, должны быть меньше единицы.
В другом случае запятая фиксируется после самого правого цифрового разряда числа. В этом случае все числа, представимые в ЭВМ, должны быть только целыми, т.е. без дробной части. При использовании полулогарифмической формы любое число Х представляется в виде: 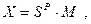 где S - основание системы счисления; P - порядок числа (целое число со знаком); M - мантисса числа X. Мантисса числа должна лежать в пределах
где S - основание системы счисления; P - порядок числа (целое число со знаком); M - мантисса числа X. Мантисса числа должна лежать в пределах 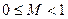 . В ЭВМ вводится мантисса числа, знак мантиссы, порядок числа и знак порядка.
. В ЭВМ вводится мантисса числа, знак мантиссы, порядок числа и знак порядка.
Полулогарифмическая форма наиболее удобна при проведении на ЭВМ научно-технических расчетов, в то время как естественная форма предпочтительна при решении задач логического характера. Поскольку задачи логического характера составляют 80-90% от общего числа решаемых на ЭВМ задач, то естественная форма является основной формой представления числовой информации. В ЭВМ общего назначения использовались обе формы представления числовой информации.
Машинные коды. Кодом называется любое обозначение, отличное от общепринятого. Общепринято, например, положительные числа отмечать знаком "+" (или, вообще, не указывать их знак), а отрицательные числа отмечать знаком «-». Числа разного знака необходимо уметь изображать состояниями двухпозиционных элементов при вводе их в машину.
Для изображения знака числа вводится дополнительный разряд, называемый знаковым, причем состояние "0" этого разряда изображает знак "+", а состояние "I" - знак "-". Такое изображение чисел со знаком называется прямым кодом. Число Х в прямом коде будем условно изображать как IXIпр. В числах, представленных в естественной форме, знаковый разряд помещается непосредственно перед числом. Таким образом, прямой код числа, представленного в естественной форме (это в полной мере относится и к мантиссе числа, представленного в полулогарифмической форме), образуется по следующему правилу. Если число Х положительно, т.е. Х = +0,Х1Х2,…Хn (Х1Х2,…Хn - цифровые разряды числа), то IXIпр = 0,Х1Х2…Хn; если число Х отрицательно, т.е. Х = -0,Х1Х2…Хn, то [Х]пр = 1,Х1Х2…Хn.
Примеры: Х = +0.1011 [Х]пр = 0,1011 У= -0,1101 [У]пр = 1.1101
Как известно, правила сложения многоразрядных чисел отличаются от правил вычитания. Чтобы по существующим правилам выполнять эти операции, ЭВМ должна иметь в своем составе два самостоятельных устройства - сумматор и вычитатель.
Но оказалось, что можно обойтись только одним устройством - сумматором, если изображать числа, участвующие в операции, в специальных кодах (в дополнительном коде или в обратном коде). Положительные числа в этих кодах полностью совпадают с прямым кодом числа.
Обратный код отрицательного числа (будем изображать его как [Х]о) образуется так. В знаковом разряде числа записывается " I ", а в цифровых разрядах, по отношению к исходному числу производитсязамена цифры "0" на "I", а "I" на "0". Пример: Х=-0,1101 [X]о =1,0010.
Дополнительный код отрицательного числа, получается из обратного кода прибавлением "I" к младшему цифровому разряду: [X]д = [X]о +2-n, где п - число, соответствующее количеству цифровых разрядов.
Пример: Х= -0,1101 [X]д=1,0010 +2-4 = 1,0011.
Иногда в машинных кодах для изображения знака используется не один знаковый разряд, а два. Такие коды называются модифицированными. Знак "+" в этих кодах представляется комбинацией "00", а "-'' - комбинацией "11".
Раньше уже указывалось, что при выполнении операций над числами, представленными в естественной форме, ни в коем случае нельзя допускать, чтобы какой-либо промежуточный результат превысил определенные допустимые пределы. Допустимые пределы - это так называемая разрядная сетка, т.е. двухпозиционные элементы, выделенные для хранения цифровых разрядов результатов.
Разрядная сетка ЭВМ однозначно указывает, сколько двухпозиционных элементов выделено для изображения цифровых разрядов числа и сколько для изображения знака числа. Выход за допустимые пределы результата называется также переполнением разрядной сетки.
При переполнении разрядной сетки происходит полнейшее искажение результата - и по величине, и по знаку. Поясним это на примерах.
1. Пусть даны два числа Х = +0,1101 и У = +0,1001. При сложении этих чисел получим: 0,1101 + 0,1001= 1,0110
Несмотря на положительные знаки слагаемых в знаковом разряде результата появилась "1", т.е. сумма как бы получилась отрицательной. Получилось это потому, что при сложении чисел получился перенос из старшего цифрового разряда в знаковый.
2. Даны два отрицательных числа Х = -0,1101 и У = -0,1001
[X]д = 1,0011 [Y]д= 1,0111
1,0011 + 1,0111 = 10,1010
Для самой левой единицы в разрядной сетке места нет. Поэтомурезультатом будет величина 0,1010, не соответствующая искомомурезультату,ни по величине, ни по знаку.
Естественно, случаи переполнения разрядной сетки необходимооперативно обнаруживать с выдачей соответствующего сообщений.
Переполнение разрядкой сетки легко обнаруживается при сложении чисел в модифицированных кодах. Рассмотрим предыдущие примеры.
00,1101 + 00,1001 =01,0110
11,0011 + 11,0111 = 110,1010
Как только в результате выполнения операции сложения чисел в естественной форме с применением модифицированного кода в знаковых разрядах оказываются комбинации "01" или "10", то это означает, что произошло переполнение разрядной сетки.
Для чисел, представленных в полулогарифмической форме, переполнение разрядной сетки при сложении мантисс не страшно. В этом случае разрядная сетка включает два знаковых разряда мантиссы, цифровые разряды мантиссы, знак порядка и цифровые разряды величины порядка.
Если переполнение разрядной сетки имеет место, то ЭВМ автоматически производит сдвиг содержимого мантиссы (вместесо знаковыми разрядами) вправо на один разряд с одновременным увеличением величины порядка на единицу.
Диапазон представимых чисел в ЭВМ. Разрядная сетка ЭВМ и форма представления числовой информации однозначно определяют диапазон представимых чисел в ЭВМ и. точность получаемых результатов.
Если числовая информация представлена в естественной форме, то диапазон представимых чисел лежит в пределах: или 1>Х³О (для случая, когда запятая фиксирована левее самого старшего цифрового разряда) или 1£Х<2n -1 (для случая, когда запятая фиксирована правее самого младшего цифрового разряда).
Если числовая информация представлена в полулогарифмической форме, то диапазон представимых чисел будет лежать в пределах
0.0…01£ |X|£0.11…1*211…1
Процессоры современных персональных компьютеров поддерживают следующие форматы числовых величин: целые числа в естественной форме – байт, слово (2 байта) и двойное слово (4 байта), числа в полулогарифмической форме – 4 байта и 8 байт.
| Значение | Описание | Дробная часть | Размер |
| Байт | Числа от 0 до 255 целого типа | Отсутствует | 1 байт |
| Целые | Числа от-32768 до 32767 целого типа | Отсутствует | 2 байта |
| Длинное целое | Числа от- 2147483648 до 2147483647 целого типа | Отсутствует | 4 байта |
| С плавающей точкой | Числа от-3.402823*1038 до 3.4023823*1038 | 4 байта | |
| С плавающей точкой (8 байт) | Числа от -1.79769313486232*10308 до 1.79769313486232*10308 | 8 байт |
2.3.Кодирование алфавитно-цифровой информации.
Современные ЭВМ обрабатывают не только числовую, но и алфавитно-цифровую информацию, содержащую цифры, буквы, знаки препинания, математические и другие символы. Именно такой характер имеет экономическая, планово-производственная, учетная, бухгалтерская и другая информация, содержащая наименование предметов, фамилии людей и т.д. Возможность ввода, обработки и вывода алфавитно-цифровой информации важна и для решения чисто математических задач, так как это позволяет оформлять результаты вычислений в удобной форме сприменением таблиц, графиков, комментариев и рисунков.
Алфавитно-цифровые символы позволяют оформлять алгоритмы решения задач в наиболее удобной для человека форме (для этого разработаны специальные алгоритмические языки) и вводить в ЭВМ, поручая ЭВМ по специальным программам перевод вводимых алгоритмов с алгоритмического языка на внутренний машинный язык машины, т.е. в программу, записанную в системе команд ЭВМ. Программы, осуществляющие такой перевод, называются трансляторами, компиляторами и интерпретаторами.
Совокупность всех символов, используемых в ЭВМ, представляет собойее алфавит. Каждый вводимый в ЭВМ символ с помощью устройства ввода преобразуется в соответствующий двоичный код фиксированной длины. В настоящее время чаще всего для кодирования символов используется 8-разрядный двоичный код, т.е. байт. Посредством байта можно кодировать до 256 различных символов. (Это вытекает из формулы Хартли – N=2n. 256=28)В настоящее время используется несколько различных кодировок: Windows 1251, Кодовая страница 766 MS-DOS, KOI-8R, ISO 8859-5.
Особенности кодировки букв русского алфавита. Итак, для кодирования символа используется один байт. Естественно, одного байта недостаточно для кодировки символов всех известных языков. Поэтому поступили так. Первые 128 значений байта (числа 0 – 7F) были выделены для кодирования символов латинского алфавита (строчных и прописных), арабских цифр 0 – 9 и некоторых других стандартных символов.
Для кодирования символов других национальных алфавитов отводятся числа с 80 по ff (или с128 по 255 в десятичной системе счисления).
К сожалению, имеет место несколько различных кодировок именно букв русского алфавита. Так, например, в кодировке Win 1251 русской прописной букве А соответствует число CO (192), а строчной букве я – число FF (255). А в кодировке KOI-8 числом CO (192) кодируется не прописная буква А, а строчная буква ю. В скобках указаны десятичные эквиваленты шестнадцатеричных чисел.
Теперь представим себе, что будет, если для отображения текста в кодировке KOI-8 используется шрифт, настроенный на кодировку Win 1251. Пусть, например, в кодировке KOI-8 записана фраза «Кирилл и Мефодий». В компьютере ее будет представлять такая последовательность чисел:
EB (235), C9 (201), D2 (210), C9 (201), CC (204), CC (204), 20 (32), C9 (201), 20 (32), ED (237), C5 (197), C6 (198), CF (207), C4 (196), C9 (201), CA (202)
Числу EB (235) в кодировке KOI-8 соответствует буква К, числу C9 (201) – буква и и т.д. Но в шрифте, настроенном на кодировку Win 1251, числом EB (235) кодируется буква л, числом C9 (201) – буква Й. В результате получится такая фраза: ЛЙТЙММ Й нЕЖПДЙК
Такие превращения довольно характерны для русского Интернета. Часто, загрузив страницу текста из Интернета в браузер (специальную программу для просмотра публикаций в Интернете), можно увидеть мешанину из русских букв вместо понятного текста. Если такое случилось, попробуйте нужно просто изменить кодировку вручную. В разных браузерах это делается по-разному. В Internet Explorer 5.0 нужно в меню «Вид» раскрыть подменю «Вид кодировки» и выбрать команду «Кириллица (KOI8-Р)». После этого на экране появится нормальный русский текст. В подменю «Вид кодировки» представлены и другие кодировки.
|
Дата добавления: 2014-01-06; Просмотров: 684; Нарушение авторских прав?; Мы поможем в написании вашей работы!