КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм обратного распространения ошибки. Алгоритм обратного распространения ошибки является классическим алгоритмом обучения многослойного персептрона
|
|
|
|
Алгоритм обратного распространения ошибки является классическим алгоритмом обучения многослойного персептрона. Этот алгоритм состоит из двух проходов вычислений:
- Прямой проход, при котором вычисляется отклик сети на поданный входной сигнал
- Обратный проход, при котором, в соответствии с полученным сигналом ошибки, модифицируются веса всех нейронов от выходного слоя к входному.
Введем следующие обозначения:
- Будем считать, что индекс 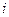 относится к нейрону во входном слое, индекс
относится к нейрону во входном слое, индекс 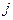 - к нейрону в скрытом слое и индекс
- к нейрону в скрытом слое и индекс  - к нейрону в выходном слое;
- к нейрону в выходном слое;
- Зададим обучающее множество 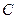 в виде набора примеров
в виде набора примеров 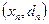 , где
, где 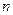 - это номер обучающего примера;
- это номер обучающего примера;
- Обозначим ошибку на выходе нейрона для обучающего примера как 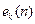 ;
;
- Введем обозначение 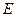 для половинной суммы квадратов ошибок
для половинной суммы квадратов ошибок 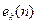 на текущем шаге процесса обучения.
на текущем шаге процесса обучения.
При прямом проходе вычислений определяются отклики 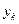 для нейронов выходного слоя. Сравнивая полученный отклик сети
для нейронов выходного слоя. Сравнивая полученный отклик сети 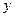 с ожидаемым откликом
с ожидаемым откликом 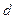 , получаем сигнал ошибки на выходе каждого из нейронов выходного слоя:
, получаем сигнал ошибки на выходе каждого из нейронов выходного слоя:
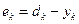 (7.28)
(7.28)
Энергию ошибки можно записать в виде:
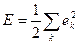 , (7.29)
, (7.29)
где суммирование осуществляется по всем нейронам выходного слоя, то есть по тем нейронам, для которых можно явно вычислить сигнал ошибки.
Модификация весов при обратном проходе вычислений должна быть направлена на уменьшение величины , которая является функцией от всех свободных параметров сети. Учитывая, что 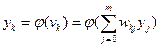 , производную сигнала ошибки по некоторому синаптическому весу в сети можно записать как:
, производную сигнала ошибки по некоторому синаптическому весу в сети можно записать как:
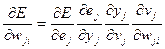 (7.30)
(7.30)
Очевидно, что выполняются следующие равенства:
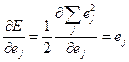 , (7.31)
, (7.31)
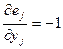 , (7.32)
, (7.32)
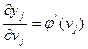 , (7.33)
, (7.33)
и, наконец,
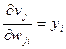 . (7.34)
. (7.34)
Таким образом, производную 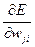 можно переписать в виде:
можно переписать в виде:
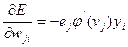 . (7.35)
. (7.35)
Воспользовавшись методом градиентного спуска, запишем величину модификации синаптического веса 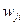 в виде:
в виде:
|
|
|
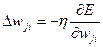 , (7.36)
, (7.36)
где 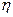 - константа скорости обучения.
- константа скорости обучения.
Величину модификации синаптического веса можно переписать в виде:
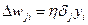 , (7.37)
, (7.37)
где 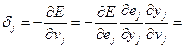
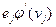 - локальный градиент нейрона
- локальный градиент нейрона
Таким образом, для вычисления модификации синаптического веса достаточно вычислить локальный градиент 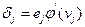 нейрона .
нейрона .
В случае, когда рассматриваемый нейрон находится в выходном слое, вычисление локального градиента не представляет труда, поскольку для нейронов выходного слоя можно явно определить сигнал ошибки 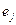 .
.
Рассмотрим локальный градиент нейрона , находящегося в скрытом слое сети.
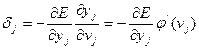 . (7.38)
. (7.38)
Поскольку 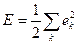 , производную
, производную 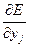 можно записать в виде:
можно записать в виде:
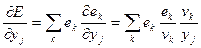 . (7.39)
. (7.39)
Используя выражения:
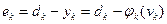 (7.40)
(7.40)
а также
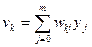 (7.41)
(7.41)
Можно получить следующие очевидные соотношения:
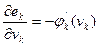 (7.42)
(7.42)
и, кроме того,
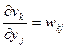 (7.43)
(7.43)
И переписать выражение для производной в виде:
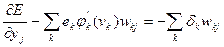 . (7.44)
. (7.44)
А следовательно, мы получаем выражение для локального градиента скрытого нейрона:
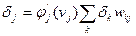 (7.45)
(7.45)
Подводя итоги, правило модификации весов для алгоритма обратного распространения ошибки можно сформулировать в виде:
, (7.46)
Где локальный градиент для нейронов выходного слоя описывается выражением:
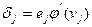 , (7.47)
, (7.47)
А для нейрона в скрытом слое локальный градиент определяется как:
. (7.48)
Модификация весов выполняется после вычисления отклика сети на каждый из обучающих примеров. Сначала вычисляются локальные градиенты для всех нейронов начиная с выходного слоя, а потом, в соответствии с полученными градиентами, вычисляются модификации всех весов сети.
Процесс обучения прекращается, если ошибка для всех обучающих примеров не превышает некоторого приемлемого значения, или если превышено максимально допустимое количество итераций.
----------------------------- ---------------------------------------------
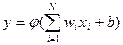 (7.1)
(7.1)
Величину 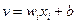 , получаемую на выходе сумматора, называют индуцированным локальным полем нейрона.
, получаемую на выходе сумматора, называют индуцированным локальным полем нейрона.
На начальной стадии моделирования нейронных сетей применялись пороговые функции активации, например:
|
|
|
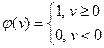 (рис. 7.3 a) (7.2)
(рис. 7.3 a) (7.2)
или
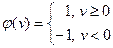 (рис. 7.3 b)
(рис. 7.3 b)
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 671; Нарушение авторских прав?; Мы поможем в написании вашей работы!