КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сжатие без потерь
|
|
|
|
Сжатие информации
Кодирование делится на три большие группы - сжатие (эффективные коды), помехоустойчивое кодирование и криптография.
Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями.
Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации.
Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где мелкие отклонения от оригинала незаметны или несущественны, а степень сжатия в силу огромных размеров файлов очень важна.
Сжатие без потерь применяется во всех остальных случаях - для текстов, исполняемых файлов, высококачественного звука и графики и т.д. и т.п.
Сжатие необходимо для сокращения длины сообщения и уменьшения времени для его передачи по каналам связи. Все используемые методы упаковки информации можно разделить на два класса: упаковка без потери информации и упаковка с потерей информации.
Сжатие представляет собой предмет выбора оптимального решения. Более эффективный алгоритм требует больше процессорной мощности или времени, необходимого для декодирования информации.
Один из самых простых способов сжатия информации – групповое кодирование. В соответствии с этой схемой серии повторяющихся величин (например, число) заменяются единственной величиной и количеством. Например, аbbbbccdddeeee заменяется на 1 a 4 b 2 c 3 d 4 e. Формат графических файлов PCX использует этот метод.
|
|
|
Простейшие алгоритмы сжатия, называемые также алгоритмами оптимального кодирования, основаны на учете распределения вероятностей элементов исходного сообщения (текста, изображения, файла). На практике обычно в качестве приближения к вероятностям используют частоты встречаемости элементов в исходном сообщении. Вероятность — абстрактное математическое понятие, связанное с бесконечными экспериментальными выборками данных, а частота встречаемости — величина, которую можно вычислить для конечных множеств данных. При достаточно большом количестве элементов в множестве экспериментальных данных можно говорить, что частота встречаемости элемента близка (с некоторой точностью) к его вероятности.
Если вероятности неодинаковы, то имеется возможность наиболее вероятным (часто встречающимся) элементам сопоставить более короткие кодовые слова и, наоборот, маловероятным элементам сопоставить более длинные кодовые слова. Таким способом можно уменьшить среднюю длину кодового слова. Оптимальный алгоритм кодирования делает это так, чтобы средняя длина кодового слова была минимальной, т. е. при меньшей длине кодирование станет необратимым. Такой алгоритм существует, он был разработан Хаффманом и носит его имя. Этот алгоритм используется, например, при создании файлов в формате JPEG.
Методом Хаффмана представляет общую схему сжатия, которая имеет много вариантов. Основная схема – присвоение двоичного кода каждой уникальной величине, причем длина этих кодов различна.
Для того чтобы сформировать минимальный код для каждого символа сообщения, используется двоичное дерево. В основном алгоритме метода объединяются вместе элементы, повторяющиеся наименее часто, затем пара рассматривается как один элемент и их частоты объединяются. Это повторяется до тех пор, пока все элементы не объединятся в пары.
|
|
|
Рассмотрим пример. Пусть дано сообщение abbbcccddeeeeeeeeef.
Частоты символов: а: 1, b: 3, c: 3, d: 2, e: 9, f: 1.
 Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
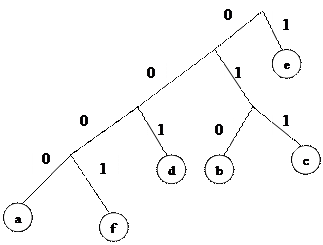 |
Рис. 2.4
Частоты первых двух символов (a и f) суммируются, что дает 2. Поскольку теперь самая низкая частота 2, эта пара объединяется с d (тоже имеет частоту - 2). Исходной паре присваивается нулевая ветвь, а d – первая. Теперь код для a заканчивается на 00, f – на 01, d – на 1. Код для d будет короче на 1 бит. Дерево строится подобным образом для всех символов. Получаем следующие коды:
0000 – a,
0001 – f,
001 – d,
010 – b,
011 – с,
1 – e.
Исходная последовательность будет закодирована следующим образом: 00000100100100110110110010011111111110001.
Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
|
|
|
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 704; Нарушение авторских прав?; Мы поможем в написании вашей работы!