КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Физическая организация памяти
|
|
|
|
С точки зрения физической организации различают микросхемы ПЗУ, статического ОЗУ, динамического ОЗУ.
1) Микросхемы ПЗУ имеют байтовую структуру емкостью от 16 Кбайт до 256 Кбайт и разделяются на ПЗУ, которые программируются при их производстве (наиболее дешевые), ПЗУ, которые программируются специальными устройствами (программаторами), и перепрограммируемые ПЗУ (ППЗУ). В последние годы постоянную память стала вытеснять энергонезависимая память (EEPROM и флэш-память), запись в которую возможна и в самом компьютере в специальном режиме работы.
Память с ультрафиолетовым стиранием - EPROM, которая программируются программатором, но есть возможность стирать информацию путем облучения микросхем ультрафиолетовыми лучами для повторного программирования. EPROM имеет следующие особенности:
- стирание информации происходит сразу для всей микросхемы под воздействием облучения и занимает несколько минут. Стертые ячейки имеют единичные значения всех бит;
- запись может производиться в любую часть микросхемы побайтно, в пределах байта можно маскировать запись отдельных бит, устанавливая им единичные значения данных;
- защита от записи осуществляется подачей низкого (5 В) напряжения на вход Vpp & рабочем режиме;
- защита от стирания производится заклейкой окна.
Память с электрическим стиранием - EEPROM. Стирание микросхем постоянной памяти возможно и электрическим способом. Однако этот процесс требует значительного расхода энергии, который выражается в необходимости приложения относительно высокого напряжения стирания (10-30 В) и длительности импульса стирания более десятка микросекунд. Интерфейс традиционных микросхем EEPROM имел временную диаграмму режима записи с большой длительностью импульса, что не позволяло непосредственно использовать сигнал записи системной шины. Кроме того, перед записью информации в ячейку обычно требовалось предварительное стирание, тоже достаточно длительное.
|
|
|
Микросхемы EEPROM относительно небольшого объема широко применяются в качестве энергонезависимой памяти конфигурирования различных адаптеров. Современные микросхемы EEPROM имеют более сложную внутреннюю структуру, в которую входит управляющий автомат. Это позволяет упростить внешний интерфейс, делая возможным непосредственное подключение к микропроцессорной шиие, и скрыть специфические (и ненужные пользователю) вспомогательные операции типа стирания и верификации.
Флэш-память по относится к классу EEPROM, но использует особую технологию построения запоминающих ячеек. Стирание во флэш-памяти производится сразу для целой области ячеек (блоками или полностью всей микросхемы). Это позволило существенно повысить производительность в режиме записи (программирования). Флэш-память обладает сочетанием высокой плотности упаковки, энергонезависимого хранения, электрического стирания и записи, низкого потребления, высокой надежности и невысокой стоимости.
Современная флэш-память имеет время доступа при чтении 35-200 не, существуют версии с интерфейсом динамической памяти и синхронным интерфейсом, напоминающим интерфейс синхронной статической памяти. Стирание информации (поблочное или во всей микросхеме) занимает 1-2 секунды. Запись байта занимает время порядка 10 мке, причем шинные циклы обращения к микросхеме при записи - нормальные для процессора (не растянутые, как для EPROM и EEPROM).
2) Статическое ОЗУ. Запоминающими элементами статического ОЗУ являются триггерные ячейки, и информация в них хранится до выключения питания. Статические ОЗУ наиболее быстродействующие, но имеют повышенное энергопотребление, невысокую плотность размещения элементов на кристалле и соответственно невысокую емкость (поэтому более дорогие) и используются для организации кэш-памяти.
|
|
|
3) Динамическое ОЗУ - DRAM (Dynamic RAM). Запоминающими элементами динамического ОЗУ являются микроскопические конденсаторы (0 - конденсатор разряжен, 1 - заряжен), которые самопроизвольно разряжаются и гарантированно хранят информацию в течении 4-7 мс, после чего они должны обновляться (регенерация памяти). При чтении из памяти конденсаторы тоже разряжаются и необходимо дополнительное время их перезаряда, что снижает быстродействие ОЗУ. DRAM требует постоянного периодического подзаряда конденсаторов, память может работать только в динамическом режиме. Этим она принципиально отличается от статической памяти, реализуемой на триггерных ячейках и хранящей информацию без обращений к ней сколь угодно долго (при включенном питании). Благодаря относительной простоте ячейки динамической памяти на одном кристалле удается размещать миллионы ячеек и получать самую дешевую полупроводниковую память достаточно высокого быстродействия с умеренным энергопотреблением, используемую в качестве основной памяти компьютера.
Лекция 5. Организация шин. Шины адреса и данных
Большинство персональных компьютеров и рабочих станций имеют физическую структуру, сходную с той, которая изображена на рис. 5.1. Обычное устройство представляет собой металлический корпус с большой интегральной схемой на дне, которая называется материнской платой. Материнская плата содержит микросхему процессора, несколько разъемов для модулей DIMM и различные микросхемы поддержки Она также содержит шину, протянутую вдоль нее, и несколько разъемов для подсоединения плат устройств ввода-вывода. Иногда может быть две шины одна с высокой скоростью передачи данных (для современных плат устройств ввода-вывода), а другая с низкой скоростью передачи данных (для старых плат устройств ввода-вывода).
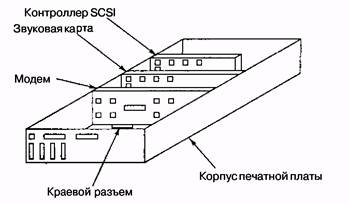
Рис. 5.1. Физическая структура персонального компьютера
Логическая структура обычного персонального компьютера показана на рис. 5.2. У данного компьютера имеется одна шина для соединения центрального процессора, памяти и устройств ввода-вывода, однако большинство систем содержат две и более шин Каждое устройство ввода-вывода состоит из двух частей: одна из них содержит большую часть электроники и называется контроллером, а другая представляет собой само устройство ввода-вывода, например дисковод. Контроллер обычно содержится на плате, которая втыкается в свободный разъем. Исключение представляют контроллеры, являющиеся обязательными (например, клавиатура), которые иногда располагаются на материнской плате. Хотя дисплей (монитор) и не является факультативным устройством, соответствующий контроллер иногда рас полагается на встроенной плате, чтобы пользователь мог по желанию выбирать платы с графическими ускорителями или без них, устанавливать дополнительную память и т. д. Контроллер связывается с самим устройством кабелем, который подсоединяется к разъему на задней стороне корпуса.
|
|
|
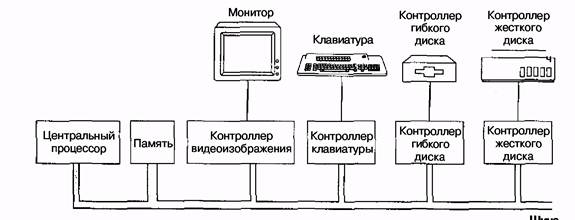
Рис. 5.2. Логическая структура обычного персонального компьютера
Шина используется не только контроллерами ввода-вывода, но и процессором для передачи команд и данных. А что происходит, если процессор и контроллер ввода-вывода хотят получить доступ к шине одновременно? В этом случае особая микросхема, которая называется арбитром шины, решает, чья очередь первая. Обычно предпочтение отдается устройствам ввода-вывода, поскольку работу дисков и других движущихся устройств нельзя прерывать, так как это может привести к потере данных. Когда ни одно устройство ввода-вывода не функционирует, центральный процессор может полностью распоряжаться шиной для связи с памятью. Однако если какое-нибудь устройство ввода-вывода находится в действии, оно будет запрашивать доступ к шине и получать его каждый раз, когда ему это необходимо. Такой процесс называется занятием цикла памяти и замедляет работу компьютера.
И все же в мире персональных компьютеров многие заменяли процессор более усовершенствованным, но при этом хотели подсоединить свой старый принтер, сканер и модем к новой системе. Кроме того, существовала целая обширная отрасль промышленности, которая выпускала широкий спектр устройств ввода-вывода для шины IBM PC, и производители этих устройств были совершенно не заинтересованы в том, чтобы начинать все разработки заново. Компания IBM прошла этот тяжелый путь, выпустив после серии IBM PC серию PS/2. У PS/2 была новая шина с более высокой скоростью передачи данных, но большинство производителей клонов продолжали использовать старую шину PC, которая сейчас называется шиной ISA(Industry Standard Architecture—стандартная промышленная архитектура). Большинство производителей дисков и устройств ввода-вывода также продолжали выпускать контроллеры для старой модели, поэтому ЮМ оказалась в весьма неприятной ситуации, поскольку она в тот момент была единственным производителем персональных компьютеров, несовместимых с серией IBM. В конце концов компания была вынуждена вернуться к производству компьютеров на основе шины ISA. Отметим, что ISA также может быть сокращением от Instruction Set Architecture (архитектура набора команд), если речь идет об уровнях компьютера. А если речь идет о шинах, аббревиатура ISA означает Industry Standard Architecture (стандартная промышленная архитектура).
|
|
|
Тем не менее, несмотря на то, что из-за влияния рынка никаких изменений не произошло, старая шина работала слишком медленно, поэтому что-то нужно было предпринять. Данная ситуация привела к тому, что другие компании начали производить компьютеры с несколькими шинами, одна из которых была старой шиной ISA или EISA (Extended ISA—расширенная архитектура промышленного стандарта). EISA — последователь ISA, совместимый со старыми версиями. В настоящее время самой популярной из них является шина PCI (Peripheral Component Interconnect—взаимодействие периферийныхкомпонентов). Онабыларазрабо-тана компанией Intel, при этом было решено сделать все патенты всеобщим достоянием, чтобы вся компьютерная промышленность (в том числе и конкуренты компании) могла перенять эту идею.
Существует много различных конфигураций шины PCI. Наиболее типичная из них показана на рис. 5.3. В такой конфигурации центральный процессор общается с контроллером памяти по специальному средству связи с высокой скоростью передачи данных. Контроллер соединяется с памятью и шиной PCI непосредственно, и таким образом, передача данных между центральным процессором и памятью происходит не через шину PCI. Однако периферийные устройства с высокой скоростью передачи данных, например SCSI-диски, могут подсоединяться прямо к шине PCI. Кроме того, шина PCI имеет параллельное соединение с шиной ISA, чтобы можно было использовать контроллеры ISA и соответствующие устройства. Машина такого типа обычно содержит 3 или 4 пустых разъема PCI и еще 3 или 4 пустых разъема ISA, чтобы покупатели имели возможность вставлять и старые карты ввода-вывода ISA (для медленно работающих устройств), и новые карты PCI (для устройств с высокой скоростью работы).
В настоящее время существует много разных видов устройств ввода-вывода. Некоторые наиболее распространенные из них описываются ниже.
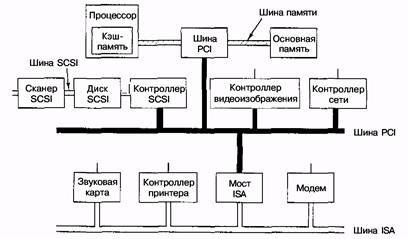
Рис. 5.3 Обычный современный персональный компьютер с шиной PCI и шиной ISA. Модем и звуковая карта — устройства ISA; SCSI-контроллер — устройство PCI
Шины — это группа проводников, соединяющих различные устройства. Шины можно разделить на группы в соответствии с выполняемыми функциями. Они могут быть внутренними по отношению к процессору и служить для передачи данных в АЛУ и из АЛУ, а могут быть внешними по отношению к процессору и связывать процессор с памятью или устройствами ввода-вывода. Каждый тип шины обладает определенными свойствами, и к каждому из них предъявляются определенные требования. В этом и следующих разделах мы сосредоточимся на шинах, которые связывают центральный процессор с памятью и устройствами ввода-вывода. В следующей главе мы подробно рассмотрим внутренние шины процессора.
Первые персональные компьютеры имели одну внешнюю шину, которая называлась системной шиной. Она состояла из нескольких медных проводов (от 50 до 100), которые встраивались в материнскую плату. На материнской плате находились разъемы на одинаковых расстояниях друг от друга для микросхем памяти и устройств ввода-вывода. Современные персональные компьютеры обычно содержат специальную шину между центральным процессором и памятью и по крайней мере еще одну шину для устройств ввода-вывода.
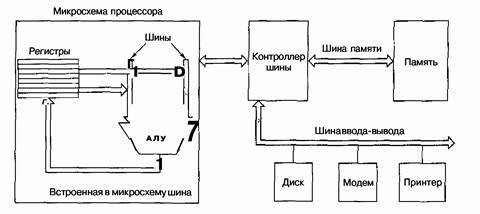
Рис. 5.4. Компьютерная система с несколькими шинами
Ширина шины — самый очевидный параметр при разработке. Чем больше адресных линий содержит шина, тем к большему объему памяти может обращаться процессор. Если шина содержит п адресных линий, тогда процессор может использовать ее для обращения к 2" различным ячейкам памяти. Для памяти большой емкости необходимо много адресных линий. Это звучит достаточно просто.
Проблема заключается в том, что для широких шин требуется больше проводов, чем для узких. Они занимают больше физического пространства (например, на материнской плате), и для них нужны разъемы большего размера. Все эти факторы делают шину дорогостоящей. Следовательно, необходим компромисс между максимальным размером памяти и стоимостью системы. Система с тттиной, содержащей 64 адресные линии, и памятью в 232 байт будет стоить дороже, чем система с шиной, содержащей 32 адресные линии, и такой же памятью в 232 байт. Дальнейшее расширение не бесплатное.
Многие разработчики систем недальновидны, что приводит к неприятным последствиям. Первая модель IBM PC содержала процессор 8088 и 20-битную адресную шину (рас. 5.5, а). Шина позволяла обращаться к 1 Мбайт памяти.
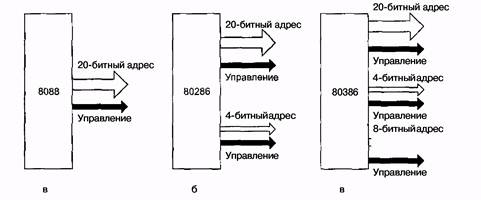
Рис.5.5 Расширение адресной шины стечением времени
Когда появился следующий процессор (80286), Intel решил увеличить адресное пространство до 16 Мбайт, поэтому пришлось добавить еще 4 линии (не нарушая изначальные 20 по причинам совместимости с более старыми версиями), как показано на рис. 5.5, б. К сожалению, пришлось также добавить линии управления для новых адресных линий. Когда появился процессор 80386, было добавлено еще 8 адресных линий и, естественно, несколько линий управления, как показано на рис. 5.5, в. В результате получилась шина EISA. Однако было бы лучше, если бы с самого начала имелось 32 линии.
С течением времени увеличивается не только число адресных линий, но и число информационных линий. Хотя это происходит по несколько другой причине. Можно увеличить пропускную способность шины двумя способами: сократить время цикла шины (сделать большее количество передач в секунду) или увеличить ширину шины данных (то есть увеличить количество битов за одну передачу. Можно повысить скорость работы шины, но сделать это довольно сложно, поскольку сигналы на разных линиях передаются с разной скоростью (это явление называется перекосом шины). Чем быстрее работает шина, тем больше перекос.
Шины можно разделить на две категории в зависимости от их синхронизации. Синхронная ппиа содержит линию, которая запускается кварцевым генератором. Сигнал на этой линии представляет собой меандр с частотой обычно от 5 до 100 МГц. Любое действие шины занимает целое число так называемых циклов ииш. Асинхронная шина не содержит задающего генератора. Циклы шины могут быть любой требуемой длины и необязательно одинаковы по отношению ко всем парам устройств. Ниже мы рассмотрим каждый тип шины отдельно.
Механизмы арбитража могут быть централизованными или децентрализованными. Рассмотрим сначала централизованный арбитраж. Простой пример централизованного арбитража показан на рис. 5.6, а. В данном примере один арбитр шины определяет, чья очередь следующая. Часто бывает, что арбитр встроен в микросхему процессора, но иногда требуется отдельная микросхема. Шина содержит одну линию запроса (монтажное ИЛИ), которая может запускаться одним или несколькими устройствами в любое время. Арбитр не может определить, сколько устройств запрашивают шину. Он может определять только наличие или отсутствие запросов.
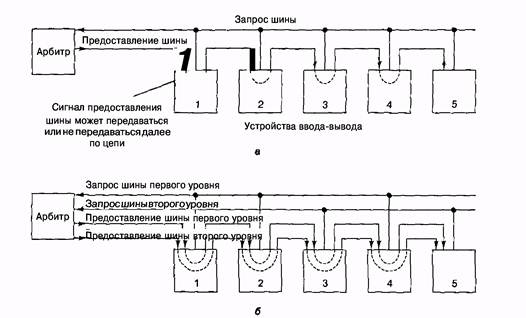
Рис. 5.6. Одноуровневый централизованный арбитраж шины с использованием системы последовательного опроса (а); двухуровневый централизованный арбитраж (б)
В системах, где память связана с главной шиной, центральный процессор должен завершать работу со всеми устройствами ввода-вывода практически на каждом цикле шины. Чтобы решить эту проблему, можно предоставить центральному процессору самый низкий приоритет. При этом шина будет предоставляться процессору только в том случае, если она не нужна ни одному другому устройству. Центральный процессор всегда может подождать, а устройства ввода-вывода должны получить доступ к шине как можно быстрее, чтобы не потерять данные. Диски, вращающиеся с высокой скоростью, тоже не могут ждать. Во многих современных компьютерах память помещается на одну шину, а устройства ввода-вывода — на другую, поэтому им не приходится завершать работу, чтобы предоставить доступ к шине.
Возможен также децентрализованный арбитраж шины. Например, компьютер может содержать 16 приоритетных линий запроса шины. Когда устройству нужна шина, оно запускает свою линию запроса. Все устройства контролируют все линии запроса, поэтому в конце каждого цикла шины каждое устройство может определить, обладает ли оно в данный момент высшим приоритетом и, следовательно, разрешено ли линии пользоваться шиной в следующем цикле. Такой метод требует наличия большего количества линий, но зато не требует затрат на арбитра. Он также ограничивает число устройств числом линий запроса.
При другом типе децентрализованного арбитража используется только три линии независимо от того, сколько устройств имеется в наличии (рис. 5.7). Первая линия — монтажное ИЛИ. Она используется для запроса шины. Вторая линия называется BUSY. Она запускается текущим задающим устройством шины. Третья линия используется для арбитража шины.
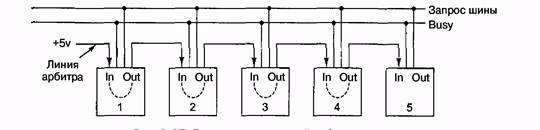
Рис. 5.7. Децентрализованный арбитраж шины
Принципы работы шины
Обычно за раз передается одно слово. При использовании кэш-памяти желательно сразу вызывать всю строку кэш-памяти (то есть 16 последовательных 32-битных слов). Часто передача блоками может быть более эффективна, чем такая последовательная передача информации. Когда начинается чтение блока, задающее устройство сообщает подчиненному устройству, сколько слов нужно передать (например, помещая общее число слов на информационные линии в период Ti). Вместо того чтобы выдать в ответ одно слово, задающее устройство выдает одно слово в течение каждого цикла до тех пор, пока не будет передано требуемое количество слов. На рис. 5.8 изображена такая же схема, как и на рис. 5.4, только здесь появился дополнительный сигнал BLOCK, который указывает, что запрашивается передача блока. В данном примере считывание блока из 4 слов занимает 6 циклов вместо 12.
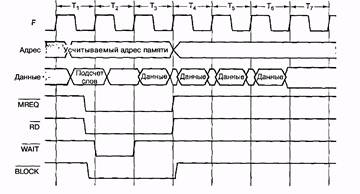
Рис. 5.8. Передача блока данных
В первых компьютерах IBM PC большинство приложений имели дело с текстами. Постепенно с появлением Windows вошли в употребление графические интерфейсы пользователя. Ни одно из этих приложений не давало большой нагрузки на шину ISA. Однако с течением времени появилось множество различных приложений, в том числе игр, для которых потребовалось полноэкранное видеоизображение, и ситуация коренным образом изменилась.
Давайте произведем небольшое вычисление. Рассмотрим монитор 1024x768 для цветного движущегося изображения (3 байта/пиксел). Одно экранное изображение содержит 2,25 Мбайт данных. Для показа плавных движений требуется 30 кадров в секунду, и следовательно, скорость передачи данных должна быть 67,5 Мбайт/с. В действительности дело обстоит гораздо хуже, поскольку чтобы передать изображение, данные должны перейти с жесткого диска, компакт-диска или DVD-диска через шину в память. Затем данные должны поступить в графический адаптер (тоже через шину). Таким образом, пропускная способность шины должна быть 135 Мбайт/с, и это только для передачи видеоизображения. Но в компьютере есть еще центральный процессор и другие устройства, которые тоже должны пользоваться шиной, поэтому пропускная способность должна быть еще выше.
Максимальная частота передачи данных шины ISA — 8,33 МГц. Она способна передавать два байта за цикл, поэтому ее максимальная пропускная способность составляет 16,7 Мбайт/с. Шина EISA может передавать 4 байта за цикл. Ее пропускная способность достигает 33,3 Мбайт/с. Ясно, что ни одна из них совершенно не соответствует тому, что требуется для полноэкранного видео.
В 1990 году компания Intel разработала новую шину с гораздо более высокой пропускной способностью, чем у шины EISA. Эту шину назвали PCI (Peripheral Component Interconnect— взаимодействие периферийных компонентов). Компания Intel запатентовала шину PCI и сделала все патенты всеобщим достоянием, так что любая компания могла производить периферические устройства для этой шины без каких-либо выплат за право пользования патентом. Компания Intel также сформировала промышленный консорциум Special Interest Group, который должен был заниматься дальнейшими усовершенствованиями шины PCI. Все эти действия привели к тому, что шина PCI стала чрезвычайно популярной. Фактически в каждом компьютере Intel (начиная с Pentium), а также во многих других компьютерах содержится шина PCI. Даже компания Sun выпустила версию UltraSPARC, вкоторойиспользуетсяшина PCI (это компьютер UltraSPARC III).
Первая шина PCI передавала 32 бита за цикл и работала с частотой 33 МГц (время цикла 30 не), общая пропускная способность составляла 133 Мбайт/с. В 1993 году появилась шина PCI 2.0, а в 1995 году - PCI 2.1. Шина PCI 2.2 подходит и для портативных компьютеров (где требуется экономия заряда батареи). Шина PCI работает с частотой 66 МГц, способна передавать 64 бита за цикл, а ее общая пропускная способность составляет 528 Мбайт/с. При такой производительности полноэкранное видеоизображение вполне достижимо (предполагается, что диск и другие устройства системы справляются со своей работой). Во всяком случае, шина PCI не будет ограничивать производительность системы.
Хотя 528 Мбайт/с — достаточно высокая скорость передачи данных, все же здесь есть некоторые проблемы. Во-первых, этого не достаточно для шины памяти. Во-вторых, эта шина не совместима со всеми старыми картами ISA По этой причине компания Intel решила разрабатывать компьютеры с тремя и более шинами. Здесь мы видим, что центральный процессор может обмениваться информацией с основной памятью через специальную шину памяти и что шину ISA можно связать с шиной PCI. Такая архитектура используется фактически во всех компьютерах Pentium II, поскольку она удовлетворяет всем требованиям.
Ключевыми компонентами данной архитектуры являются мосты между шинами (эти микросхемы выпускает компания Intel — отсюда такой интерес к проекту). Мост PCI связывает центральный процессор, память и шину PCI. Мост ISA связывает шину PCI с шиной ISA, а также поддерживает один или два диска IDE. Практически все системы Pentium П выпускаются с одним или несколькими свободными слотами PCI для подключения дополнительных высокоскоростных периферийных устройств и с одним или несколькими слотами ISA для подключения низкоскоростных периферийных устройств.
Шины PCI являются синхронными, как и все шины PC, восходящие к первой модели IBM PC. Все транзакции в шине PCI осуществляются между задающим и подчиненным устройствами. Чтобы не увеличивать число выводов на плате, адресные и информационные линии объединяются. При этом достаточно 64 выводов для всей совокупности адресных и информационных сигналов, даже если PCI работает с 64-битными адресами и 64-битными данными.
Объединенные адресные и информационные выводы функционируют следующим образом. При операции считывания во время цикла 1 задающее устройство передает адрес на шину. Во время цикла 2 задающее устройство удаляет адрес и шина реверсируется таким образом, чтобы подчиненное устройство могло ее использовать. Во время цикла 3 подчиненное устройство выдает запрашиваемые данные. При операциях записи шине не нужно переключаться, поскольку задающее устройство помещает на нее и адрес, и данные. Тем не менее минимальная транзакция занимает три цикла. Если подчиненное устройство не может дать ответ в течение трех циклов, то вводится режим ожидания. Допускаются пересылки блоков неограниченного размера, а также некоторые другие типы циклов шины.
Лекция 6 Внешние интерфейсы
Порт параллельного интерфейса был введен в PC для подключения принтера — отсюда и пошло его название LPT-порт (Line PrinTer — построчный принтер). Традиционный, он же стандартный, LPT-порт (так называемый SPP-nopm) ориентирован на вывод данных, хотя с некоторыми ограничениями позволяет и вводить данные. Существуют различные модификации LPT-порта — двунаправленный, ЕРР, ЕСР и другие, расширяющие его функциональные возможности, повышающие производительность и снижающие нагрузку на процессор. Поначалу они являлись фирменными решениями отдельных производителей, позднее был принят стандарт IEEE 1284.
С внешней стороны порт имеет 8-битную шину данных, 5-битную шину сигналов состояния и 4-битную шину управляющих сигналов, выведенные на разъем-розетку DB-25S. В LPT-порте используются логические уровни ТТЛ, что ограничивает допустимую длину кабеля из-за невысокой помехозащищенности ТТЛ-интерфейса. Гальваническая развязка отсутствует — схемная земля подключаемого устройства соединяется со схемной землей компьютера. Из-за этого порт является уязвимым местом компьютера, страдающим при нарушении правил подключения и заземления устройств. Поскольку порт обычно располагается на системной плате, в случае его «выжигания» зачастую выходит из строя и его ближайшее окружение, вплоть до выгорания всей системной платы.
С программной стороны LPT-порт представляет собой набор регистров, расположенных в пространстве ввода-вывода. Регистры порта адресуются относительно базового адреса порта, стандартными значениями которого являются 3BCh, 378h и 278h. Порт может использовать линию запроса аппаратного прерывания, обычно IRQ7 или IRQ5. В расширенных режимах может использоваться и канал DMA.
Порт имеет поддержку на уровне BIOS — поиск установленных портов во время теста POST и сервисы печати Int 17h обеспечивают вывод символа (по опросу готовности, не используя аппаратных прерываний), инициализацию интерфейса и принтера, а также опрос состояния принтера.
Практически все современные системные платы (еще начиная с PCI-плат для процессоров 486) имеют встроенный адаптер LPT-порта. Существуют карты ISA с LPT-портом, где он чаще всего соседствует с парой СОМ-портов, а также с контроллерами дисковых интерфейсов (FDC+IDE). LPT-порт обычно присутствует и на плате дисплейного адаптера MDA (монохромный текстовый) и HGC (монохромный графический «Геркулес»). Есть и карты PCI с дополнительными LPT-портами.
К LPT-портам подключают принтеры, плоттеры, сканеры, коммуникационные устройства и устройства хранения данных, а также электронные ключи, программаторы и прочие устройства. Иногда параллельный интерфейс используют для связи между двумя компьютерами — получается сеть, «сделанная наколенке» (LapLink).
Традиционный, он же стандартный, LPT-порт называется стандартным параллельным портом (Standard Parallel Port, SPP), или SPP-портом, и является однонаправленным портом, через который программно реализуется протокол обмена Centronics.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 760; Нарушение авторских прав?; Мы поможем в написании вашей работы!