КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Загальна модель перекладу
|
|
|
|
Лекція 5
Контрольні запитання і завдання
1. Розкрийте значення функцій менеджменту.
2. Перелічите основні функції менеджменту.
3. Розкрийте зміст основних функцій менеджменту.
4. Перелічите спеціальні функції менеджменту.
5. Розкрийте зміст спеціальних функцій менеджменту.
6. В чому полягає регламентація функцій менеджменту?
7. Розкрийте зміст посадових інструкцій.
Література: 7; 10; 11; 13; 21.
В цій лекції ми розглянемо модель перекладу як процесу. При цьому будемо виходити з висловлених раніше припущень щодо природи і характеристик процесу перекладу.
Варто ще раз нагадати, що в основу нашого підходу покладене уявлення про здійснення перекладу на основі моделі, основні вимоги до якої можна сформулювати таким чином:
Тепер повернемося до уточнення наших уявлень щодо процесу трансляції базуючись на загальній схемі наведеній на рис. 5.
1. Деталізація компонентів і процесів загальної схеми. Базовим припущенням побудови перекладачів є уявлення про переклад як спеціальний випадок більш загального явища оброблення інформації людиною.
Відповідно процес трансляції ми можемо змоделювати, виходячи з психологічного погляду на сферу оброблення інформації.
Процес перекладу відбувається в короткотерміновий і довготерміновій пам’яті за допомогою пристроїв для декодування тексту мовою вихідною (SL) і кодування тексту мовою цільовою (ТL) опосередковано через незалежне від специфічної мови семантичне представлення.
Процес перекладу оперує на лінгвістичному рівні простих клауз незалежно від того відбувається аналіз вхідного чи синтез вихідного сигналу (одномовного, усного чи письмового, чи двомовного, тобто трансляції).
|
|
|
Процес перекладу здійснюється як у низхідний, так і висхідний спосіб при обробленні текстів і інтегрує обидва підходи завдяки стилю оперування, який є і каскадним, і ітеративним. Тобто аналіз або синтез виконуваний на черговій стадії, не вважається завершеним і нова стадія не розпочинається доти, доки не буде здійснена перевірка результатів і саме її успішні результати дозволяють перехід.
Реалізація процесу перекладу для обох мов вимагає наявності:
1) візуальної системи розпізнавання слів і системи запису;
2) здатного опрацьовувати опції системи МООD синтаксичного процесора, який містить сховище для лексем, які часто зустрічаються, (FLS), механізм лексичного пошуку (LSM), сховище для синтаксичних структур, які часто зустрічаються, (FSS) і механізм розбору, через які інформація передається (або приймається у зворотному випадку) в семантичний процесор;
3) семантичний процесор, який здатен опрацьовувати опції системи TRANSITIVITY і обмінюватися інформацією з прагматичним процесором;
4) прагматичний процесор, який здатен опрацьовувати опції системи THEME;
5) органайзер опрацювання загальної інформації, який відстежує і організує розвиток мовних актів у тексті (і якщо тип тексту невідомий, робить висновки на основі наявної інформації) як частини стратегії здійснення планів щодо досягнення цілей, визначених і збережених планувальником;
6) планувальник, який займається створенням планів щодо досягнення цілей всіх видів. Деякі з цих планів можуть передбачати використання мов, таких як оброблення тексту (text-processing). Це може включати трансляцію тексту і це рішення може бути прийняте навіть до того як перше просте речення оброблене.
Загальну суму реалізації процесу можна зобразити у вигляді, наведеному на рис. 11.
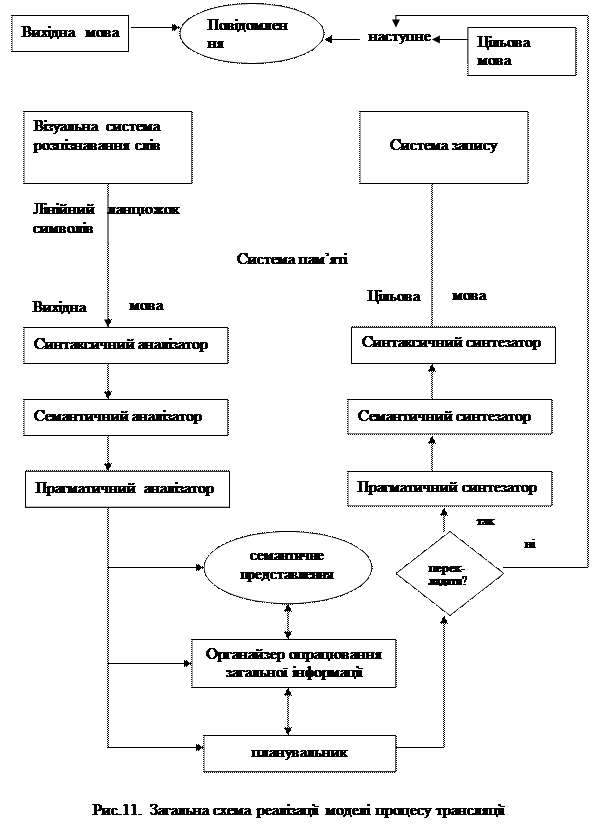
Тепер перейдемо до пояснення роботи кожного компонента, уточнення специфікації його вихідної і результуючої інформації, деталізації здійснення кожної стадії і демонстрації того, як компоненти повинні взаємодіяти, щоб відтворити динамічний процес перекладу.
|
|
|
Варто ще раз підкреслити, що процес перекладу, концепція реалізації якого закладена в наведену схему, не є лінійним процесом, в якому всі стадії виконуються в заздалегідь визначеному порядку. Це швидше інтегральний процес, в якому визначений наперед порядок може змінюватися за рахунок повернення на попередні стадії після перевірки результатів поточної стадії, відмови від результатів попереднього опрацювання і повтору процесу з будь-якої попередньої стадії.
Корисним буде ще раз нагадати, що модель, яка втілюється цією схемою, виділяє у комплексному процесі перекладу традиційні для прикладної лінгвістики аналіз і синтез, кожен з яких базується на принципових для мовознавства процесах, пов’язаних з опрацюванням синтаксичних, семантичних і прагматичних аспектів висловлювань і дискурсу.
Реалізація включає усі процеси, які традиційно пов’язують з вирішенням проблем, але з урахуванням особливостей оброблення природномовної інформації: розбір; представлення і перетворення; загальна характеризація; планування; управління.
2. Аналіз повідомлень. Аналіз повідомлень полягає в тому, щоб зрозуміти думку відправника, його наміри, стильові та інші особливості. По суті аналіз дає усю необхідну інформацію для синтезу повідомлення цільовою мовою. З урахуванням модельного підходу ми повинні підкреслити, що аналіз повинен також констатувати відсутність необхідної для синтезу повідомлення цільовою мовою інформації, якщо аналізатор дійсно не зміг її видобути. Ця можливість закладена у саму сутність модельного підходу, який визначає повний набір елементів інформації, який повинен бути на вході і виході кожної стадії.
Саме ці аспекти пов’язані з реалізацією операцій управління процесом перекладу, контролем результатів кожної стадії, плануванням.
Ми розглядаємо синтаксичний, семантичний і прагматичний аналіз традиційно окремо, хоч у самому процесі перекладу схема їх реалізації не є такою чітко послідовною, а якщо врахувати інтегральну концепцію Р. Шенка, то вони повинні функціонувати навіть паралельно.
|
|
|
Але до цього інтегрального розуміння ми можемо перейти, лише розглянувши усі стадії аналізу окремо.
У цій лекції ми лише окреслимо всі стадії процесу аналізу, а потім будемо поглиблювати уявлення про нього, розглядаючи більш детально засоби лексикосемантичної і граматико-синтаксичної систем мови.
2.1. Синтаксичний аналіз. Це перша важлива стадія аналізу. Хоч взагалі першою стадією є, за необхідності, читання тексту. Тому в системі-перекладачі й повинна бути візуальна система розпізнавання слів (SLТ), яка здатна відрізнити слова від не-слів у тексті вихідною мовою. Ми ставимо задачу оброблення текстів з наголосом на такому розпізнаванні на початку, оскільки хочемо концентруватися на обробленні повідомлень, які сприймаються як лінійні ланцюжки дискретних символів.
Отже початкове оброблення, яке виконується механізмами для розпізнавання і кодування чітких особливостей літер і т.п., забезпечує на вході синтаксичного аналізатора відповідний лінійний ланцюжок літер для будь-якого повідомлення.
Розглянемо спочатку особливості процесу синтаксичного аналізу на простих прикладах:
a) Англійською мовою:
The dog bit the man
b) Українською мовою:
Просте речення прикладу а) чи b) подається в синтаксичний аналізатор. По суті це може бути складне чи просте речення і у першому випадку треба говорити про виділення простих речень. У цьому реченні мають бути виділені синтаксичні структури. Вибір цих структур у системі МООD ми розглянемо пізніше.
Просте речення у вигляді лінійного ланцюжка літер може пройти через механізм розбору або через сховище часто вживаних синтаксичних структур (FSS). Відповідно після цього для результатів виявлення синтаксичної структури також є вибір – механізм лексичного пошуку або сховище часто вживаних лексем (FLS).
Наприклад, традиційне для казок і дитячих історій речення англійської мови
Once upon a time the was …
в українській мові одразу отримає еквівалент
Колись у давні-предавні часи жили-були…
Це дозволяє обійти механізм розбору і/або механізм лексичного пошуку за рахунок зберігання необхідної інформації в короткотерміновій пам’яті.
|
|
|
Необхідно лише зазначити, що обидва сховища повинні конструюватися з урахуванням обмежень на змінність мінливість репертуару і кількісних і якісних відмінностей відправників і отримувачів повідомлень.
2.1.1 Сховище часто вживаних лексем FLS.
FLS – це психолінгвістичний корелят фізичного глосарія чи термінологічної бази даних, сховище для лексем, як слів, так і ідіом. Сюди включаються найбільш вживані конструкції
а) такі як a, and, I, in, is, it, of, that, the, to, was, які складають 20% перших 20000 тис слів середнього словника дорослої людини;
б) інші часто вживані конструкції all, as, said, look (це ще 238 слів, які складають наступні 40% перших 20000 тис слів середнього словника дорослої людини).
2.1.2. Сховище часто вживаних синтаксичних структур FSS.
FSS – це набір операцій, які залучають використання часто вживаних структур, які без сумніву зберігаються в пам’яті у всій їх цілісності, як лексичні конструкції з прямим доступом до фраз і речень майже таким же швидким, як і до слів.
Стосовно FSS і FLS необхідно домовитися про такі особливості їх реалізації у перекладачі:
1) одне FSS і одне FLS на кожну мову перекладача;
2) хоч FSS буде містити більшість конструкцій, які поділяються мовною спільнотою, воно повинне залежати від часу і враховувати особливості відправників і отримувачів;
3) FSS повинне враховувати особливості мов, наприклад для англійської мови він буде включати:
a) комбінації Subject (S), Predicator (P), Complement (C), Object (O) і Adjunct (A), які покривають усі опції, наявні в системі МООD, в indicative, interrogative і imperative формах, як наприклад основні структури, на яких базується кожне просте речення англійської мови:
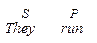
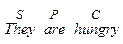
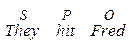
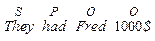
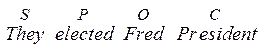
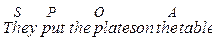
Зауважимо, що Adjunct можуть бути добавлені у кожне з цих речень в будь-яких позиціях і рекурсивно. Також навіть в declarative формі можуть бути присутні стилістично забарвлені поправки, наприклад, пасив:
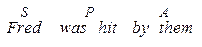
Таких структур напевне не буде в FSS.
б) на фразовому рівні FSS буде містити важливі опції із набору m – modifier (модифікатор), h – head (головний) і q – qualifier (кваліфікатор).
Наприклад:
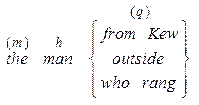
Пізніше ми детальніше розглянемо усі структури рівня речення, простого речення, фрази.
Отже, після проходження FSS (або механізму розбору) ланцюжок літер іде на FLS (або механізм лексичного пошуку), оскільки це не є незвичним для отримувача аналізувати синтаксис без розуміння значення слів.
2.1.3. Механізм розбору. Це важливий механізм, який включається, якщо речення відсутнє в FSS. Одразу після цього речення переходить до FLS. Якщо для речення відповідні лексичні позиції уже прописані в FLS, то речення переходить на семантичний аналіз
Для підтвердження більшої важливості структури, а не контенту, можна привести речення:
the smaggly dognats grolled the fimbled ashlars tor a varit
Еквівалент Щерби можна навести для російської мови, але зі словами, які не належать її лексиці
Глокая куздра штеко будланула бокра и курдячит букренка.
Для наведеного прикладу речення англійської мови легко можна встановити синтаксичну структуру S Р О А і легко представити її послідовністю фраз –
NP VP NP PP
Тут NP – noun phrase (іменникова фраза),
VP – verb phrase (дієслівна фраза),
PP – prepositional phrase (препозиційна (прийменникова) фраза).
Більш того легко навіть заповнити цю структуру { mmh } { h } { mmh }{ pc } і навіть визначити класи лексем: [ den ] [ mv ] [ den ] [ pdn ].
Тут для дієслів застосовуються такі опції в MOOD a – auxiliary; mv – main verb, e – extender, a для prepositional phrases – bp – before preposition, p – preposition i c – compliter.
Наприклад:
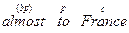
2.1.4. Механізм лексичного пошуку. Він спрацьовує, якщо речення немає в FLS. Він забезпечує засоби пошуку змісту незнайомого слова.
Наприклад, ashlar - акуратно оброблений і добре підігнаний будівельний камінь.
Якщо перекладач не знає цього, то є такі стратегії:
а) вичавити значення із контексту;
б) ігнорувати і сподіватися на те, що зростаючий обсяг інфляції контексту дозволить підібрати значення;
в) шукати в пам’яті подібні лексеми і будувати значення із них
ash i lar
Отже, підбиваючи підсумки, стосовно речень із наших прикладів, ми повинні завершити аналіз, констатуючи, що:
- синтаксичний аналізатор на вході отримує ланцюжок символів і видає на виході синтаксичну MOOD структуру;
- семантичний аналізатор на вході отримує інформацію, в якій цей ланцюжок символізується у термінах синтаксичних функцій (S, P, C, O, A), їх фразової структури і лексичних заповнювачів, щонайменше лексичних значень, приписаних до лексичних складових, які показують специфіку цих значень;
- для зображення синтаксичної інформації будемо використовувати деревовидні діаграми
Приклад 1:


 Рівень 1 S P O
Рівень 1 S P O



 Рівень 2 NP VP NP
Рівень 2 NP VP NP

 Рівень 3 m h mv m h
Рівень 3 m h mv m h
|  | |


 Рівень 4 d n vt d n
Рівень 4 d n vt d n
 |
Рівень 5 the dog bit the man
Тут використані такі позначення: d – determiner (визначник), n – noun, vt – transitive verb.
Але оскільки наша послідовність слів на вході є одночасно результатом семантичних процесів, репрезентацією досвіду, інтерактивного обміну і повідомленням, то все що є на виході синтаксичного аналізатора не дозволяє ще говорити про statement (ствердження) для відправника чи отримувача. Тому потрібен подальший аналіз речення в термінах контенту.
Тому ми повинні перейти до семантичного, а потім і прагматичного аналізу.
2.2. Семантичний аналіз. Його задачею є виявлення відношень TRANSITIVITY, які формують семантичну структуру речення.
Для цього семантичний аналізатор із виходу синтаксичного аналізатора повинен виділити:
- про що це речення;
- що воно представляє;
- логічні відношення між учасниками і процесом (і також, якщо вони наявні, контактно установчі обставини: час, місце, спосіб і т.п.);
- загальне значення;
- семантичне значення;
- пропозиційний контент.
Тільки якщо задачею синтаксичного аналізатора є одержання синтаксичної структури і лексичних заповнювачів із вхідного ланцюжка символів, то задачею семантичного аналізатора є одержання контенту із синтаксичної структури, яка передається на нього із попередньої стадії.
Повертаючись до нашого прикладу
- The dog bit the man
в термінах контенту, ми повинні встановити який процес виконується (хоч це може бути відношення, а не справжня дія у інших випадках), хто є учасниками процесу і як вони відносяться один до іншого як учасники процесу.
Згадаємо, що синтаксичний аналізатор на виході видає структуру клаузи у вигляді дерева для S P O. Семантичний аналізатор розпізнає послідовність Actor – Process – Goal в пропозиції, яка формує основу клаузи, при цьому Subject буде порівняний з Actor, Predicator – з Process і Object – з Goal.
В термінах цілей важко витягнути щось більше із клаузи на цій стадії, ніж твердження за замовчуванням, що це є statement. Ми повернемося до цього на наступній стадії.
В термінах граматичної моделі, яку ми використовуємо, семантичний аналіз забезпечує інформацію щодо опцій TRANSITIVITY, які підібрані щоб структурувати пропозицію, яка формує основу клаузи.
В термінах мовленнєвих актів, ми тепер маємо пропозиційний контент, але не маємо ілокутивної сили – контент, але не намір – і обидва вони необхідні перш ніж ми можемо пов’язати клаузу з певним мовленнєвим актом.
Тепер, коли ми маємо специфікацію логічної форми, яка підпирає клаузу знизу, ми можемо переходити до аналізу комунікативних функцій, яким вона служить.
2.3. Прагматичний аналіз. Синтаксичний процесор, як ми щойно бачили, реалізує дві функції (по-перше, аналіз синтаксичної MOOD-структури і, по-друге, призначення лексичного значення), а семантичний – єдину функцію (виділення контенту, відношень TRANSITIVITY).
У цьому відношенні прагматичний аналізатор більше потрібний до синтаксичного, оскільки також реалізує дві функції, одержавши інформацію із попередніх стадій:
• виділити і представити ремотематичну структуру;
• виконати аналіз регістрів на її основі.
Реалізація першої функції пов’язана з моделлю THEME (з розподілом інформації і визначенням того має воно marked чи unmarked order), тоді як реалізація другої функції зосереджується на регістрах (з стилістичними характеристиками, включаючи цілі), приймаючи до уваги три стилістичні параметри:
• tenor of discourse (загальне значення повідомлення): відношення з отримувачем, які відправник демонструє опосередковано через вибір, зроблений у тексті (далі розглянемо більш детально);
• mode of discourse (спосіб повідомлення): середовище, вибране для реалізації тексту (далі розглянемо його більш детально);
• domain of discourse (область повідомлення): область, яку охоплює текст; роль, яку він відіграє у комунікативній діяльності; для чого це повідомлення надіслане; що відправник намагався передати з його допомогою; його комунікативна цінність (далі розглянемо більш детально).
Одночасно клаузі приписуються ремотематична структура і особливості регістрів. Хоч ми будемо детально розглядати ці аспекти у окремих лекціях, наразі уточнимо деякі з них для наших прикладів.
Отже, якщо аналізувати прагматичні аспекти клаузи
The dog bit the man,
то з точки зору ремотематичної структури можемо легко визначити, що темою є The dog, а ремою – bit the man.
Інакше кажучи, ремотематична структура має такий вигляд
The dog bit the man
THEMA RHEMA
А оскільки Subject, Actor і тема всі поставлені у відповідність, то це unmarked структура (ось чому вона обійшла FSS на першому кроці).
Що стосується особливостей регістрових, то вони визначаються одночасно шляхом визначення згаданих вище стилістичних параметрів клаузи. Припускаючи, що текст з’явився нізвідки і не втілений в книжках з лінгвістики, (що є досить малоймовірним), перелічимо наші висновки на базі всього, що нам відомо:
а) в термінах tenor:
- formality (церемоніальність або відповідність конвенціям);
- politeness (манерність);
- impersonality (відношення до конкретних осіб).
Ці властивості не відмічені. Тобто ми можемо ігнорувати їх при аналізі мовленнєвого акту, приймаючи за замовчуванням їх як unmarked.
В той же час accessibility (доступність) – дуже висока.
б) в термінах mode:
- particiрation (як багато зусиль витратив відправник, щоб створити повідомлення) – індикаторів немає;
- spontaniety – індикаторів немає;
- channel limitation – висока (текст написаний для читання);
- публічність – текст публічний.
в) в термінах domain:
текст певно референційний і аж ніяк не емоційний, конативний, фатичний, поетичний чи (якщо ми не знаємо звідки ця окрема клауза надійшла) металінгвістичний.
Domain забезпечує індикацію намірів (ілокутивної сили), яка у комбінації з наявною інформацією щодо контенту і припускає наявність мовленнєвого акту (для нашого прикладу ми застосовуємо інформування) і ця мітка разом з іншою інформацією передається на наступну стадію оброблення.
Отже, підбиваючи підсумки, можемо зафіксувати:
The dog bit the man
Actor Material process Goal
Мовленнєвий акт = інформування.
Інформація на наступну стадію передається у формі, подібній до:
The dog bit the man
Мовленнєвий акт • інформування;
Тема • - marked
Tenor • + accessible
Mode • - participation
• + channel limitation (написаний для читання)
+ публічний
Domain: referational
На основі цієї інформації стилістичний аналізатор може зробити попереднє визначення типу тексту клаузи. В нашому випадку можна відкинути декілька можливих типів текстів, але все ж необхідно почекати доки з’явиться більше інформації, коли надійдуть пізніші клаузи того ж тексту, до тих пір доки не збереться достатньо інформації для остаточного визначення типу.
Основне питання «У якому типі тексту може міститися клауза подібна цій?». Пока лише є мінімальна інформація – публічний характер і доступна, не дозволяє встановити participation і оперує в обмеженому каналі – письмовий текст.
Аналіз регістрів може на цій стадії зробити лише якийсь загальний висновок, що це книга або стаття із лінгвістики, бо хто ще буде розглядати такі банальні речення.
Отже тепер наступає черга для двох важливих стадій:
• завершення формування повністю незалежної від мови семантичної репрезентації;
• продовження аналізу клаузи на двох стадіях, які залишилися – опрацювання загальної інформації і планування.
Розпочнемо із семантичної репрезентації. Раніше набута інформація щодо клаузи разом із стилістичними особливостями складає все значення думки, вираженої в клаузі, як її розуміє читач – одержувач. Тут критично важливо зрозуміти різницю між незалежною від мови семантичною репрезентацією і власне клаузою, яка побудована за нормами конкретної мови. Якщо клауза організована за рахунок SPCOA відношень, вибраних із MOOD-системи конкретної мови, то семантична репрезентація є набором абстрактних універсальних концепцій і відношень, які представляють думку.
І хоч ми говоримо, що семантична репрезентація мовно-незалежна, це стосується її власне семантичної і прагматичної інформації, а в цілому семантична репрезентація інтегрує результати синтаксичного, семантичного і прагматичного аналізу. Загалом семантична репрезентація містить таку синтаксичну, семантичну і прагматичну інформацію:
1) структуру клаузи: MOOD і лексичні результати вибору відправника в процесі мовлення, включаючи лексичне значення і ті випадки, де будь-яка із лексем має незвичайне застосування, по суті позначаючи цей ефект;
2) пропозиційний контент: результат вибору мовця у системі відношень TRANSITIVITY; логічні відношення, накладені на синтаксичну структуру;
3) ремотематична структура: результати вибору мовця у системі відношень THEMA, включаючи індикацію markedness;
4) особливості регістрів: tenor, mode i domain дискурсу;
5) ілокутивна сила (виведена із domain), яка, комбінуючись із пропозиційним контентом, указує на мовленнєвий акт;
6) мовленнєвий акт, у рамках якого сприймається клауза; найпростіший випадок, коли існує взаємно однозначна відповідність між клаузою і мовленнєвим актом не є незвичним, але не пояснює всього стану речей.
Загалом семантична репрезентація є результатом тристадійного процесу аналізу клаузи і основою для аналогічного тристадійного процесу синтезу нової клаузи, коли здійснюється переклад. І щоб зрозуміти модельний підхід до перекладу, ми повинні однозначно погодитись з тим, що ми не перекладаємо клаузу однієї мови, скажімо A, у клаузу іншої мови, нехай B. При модельному перекладі ми розбиваємо клаузу мови А і виділяємо семантичну репрезентацію, яку використовуємо як основу для побудови альтернативної клаузи в мові В (це і є переклад) чи в тій же мові А (це і є перифраза).
Звичайно більшість користувачів мови (особливо одномовних читачів) могла б очікувати, що після того як значення виділено із клаузи і перетворено в семантичну репрезентацію, її синтаксична форма може бути видалена із робочої пам’яті (STM) і лише її значення буде зберігатися в LTM. Перекладачі ж, однак, знаючи про потребу в знанні ремотематичної markedness, яка виникне коли прийде час записувати TLT, напевне збережуть певну синтаксичну інформацію, яка допоможе їм не застосовувати механізм синтаксичного розбору на стадії синтезу.
Тепер залишається розглянути дві заключні стадії аналізу, які по суті можна розглядати вже і як стадії синтезу – роботу органайзера і планувальника.
Органайзер, одержавши всі результати аналізу, реалізує такі функції:
1) інтегрування аналізу з вирощуванням усіх шарів тексту в процесі діяльності читача;
2) постійний моніторинг результатів шляхом повернення на попередні стадії;
3) перегляд семантичної репрезентації на основі нової інформації.
Планувальник також одержує усі результати аналізу і використовує їх щоб полегшити досягнення поточних цілей, які повинні бути наслідком читання. Це та стадія, коли приймаються рішення щодо необхідності продовження читання і т.п. і, насамперед, необхідності перекладу.
Якщо приймається рішення не перекладати, процес, залишаючись одномовним, повертається знову на початок до нової клаузи.
Якщо ж приймається рішення перекладати, то береться ідея, яка тепер зберігається як семантична репрезентація клаузи, і запускається зворотній процес. У ході цього процесу, на основі семантичної репрезентації, буде синтезовано компонент тексту на цільовій мові.
Тепер ми можемо представити більш детальну модель процесу перекладу.
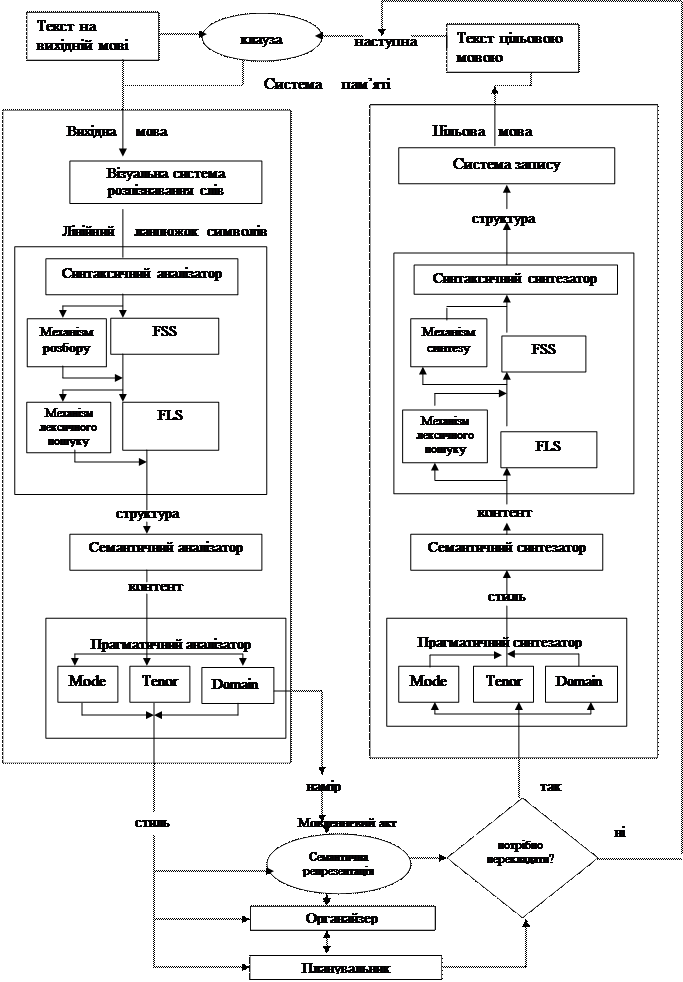 | |||
|
3. Синтез повідомлень. Процес синтезу охоплює усі стадії загального процесу опрацювання тексту на вихідній мові, розпочинаючи з точки, в якій клауза вихідною мовою уже перетворена у семантичну репрезентацію (її складові перелічені вище) і читач вирішив перекладати текст .
.
Необхідно наголосити на важливому припущенні, що інформація, яка зберігається у семантичній репрезентації, достатня, щоб зробити висновок щодо типу тексту, у якому може з’явитися клауза.
Побудова тексту, який передає увесь або вибіркову частину контенту семантичної репрезентації розпочинається із прагматичного синтезатора цільової мови. Хоч, варто ще раз нагадати, реально усі складові синтезатора можуть працювати паралельно.
3.1. Прагматичний синтез. Прагматичний процесор цільової мови одержує всю інформацію семантичної репрезентації і на її основі намагається розв’язати три ключових проблеми (при цьому щодо кожної з них він приймає рішення «зберегти напрацьоване» чи «змінити напрацьоване»):
а) що робити із встановленим наміром оригіналу. Перекладач може зробити спробу зберегти чи змінити його. У будь-якому випадку, повинне бути прийняте рішення виражати намір на наявному контенті чи, приймаючи до уваги, що план перекладача включає рішення змінити будь-які із параметрів (наприклад, перетворити інформативний текст у полемічний), виражати намір на іншому контенті;
б) що робити із встановленою ремотематичною структурою оригіналу. Збереження чи зміна оригінальних ремо-тематичних відношень вимагає рішення щодо участі перекладача і знання наявних опцій;
в) що робити із встановленим стилем оригіналу. Тут знову вибір між збереженням і зміною.
І саме прагматичний процесор повинен виконати ці відображення підходящих намірів, ремотематичних структур і параметрів дискурсу – mode, tenor i domain.
3.2. Семантичний синтез. Семантичний процесор цільової мови одержує індикацію ілокутивної сили, створює структуру, яка несе пропозиційний контент і напрацьовує задовільну пропозицію, яку можна передати на наступну стадію синтезу.
3.3. Синтаксичний синтез. Синтаксичний процесор цільової мови приймає на вході результати семантичного синтезатора і сканує його FLS, щоб знайти підходящі лексичні позиції, а також сканує FSS у пошуку відповідного типа клаузи, яка буде представляти пропозицію. Якщо у FSS відсутня структура клаузи, яка може передати встановлене значення, то пропозиція пропускається через механізм розбору (який тепер функціонує як синтаксичний синтезатор) і, насамкінець, через систему запису, яка реалізує клаузу як ланцюжок символів, які складають текст на цільовій мові.
Після цього процес завершує цикл оброблення клаузи тексту на вихідній мові і повертається до початкового тексту і наступної клаузи.
Висновки
1. Розглянуто більш детальному рівні загальну схему перекладу та її основні компоненти і процеси.
2. Розглянуто особливості реалізації стадії синтаксичного аналізу вихідних повідомлень.
3. Розглянуто особливості реалізації стадії семантичного аналізу вихідних повідомлень.
4. Розглянуто особливості реалізації стадії прагматичного аналізу вихідних повідомлень.
5. Розглянуто особливості реалізації стадій прагматичного, семантичного і синтаксичного синтезу вихідних повідомлень.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 537; Нарушение авторских прав?; Мы поможем в написании вашей работы!