КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Нечисловые алгоритмы
|
|
|
|
Расчет таблицы значений функции.
Лекция 11
Многие задачи, решаемые на ЭВМ, в конечном счете, сводятся к формированию таблиц значений функций, которые в дальнейшем используются для накопления результатов, построения графиков и анализа результатов. Таблица должна содержать аргумент и одну или несколько функций. Для хранения таблицы можно использовать несколько одномерных массивов (каждый для отдельной функции), либо один двумерный массив, в котором аргумент и функции хранятся в столбцах массива. Использование двумерного массива является более предпочтительным, так как все данные хранятся в одном месте.
В качестве исходных данных можно задавать: начальное значение аргумента (XH), конечное значение аргумента (XK) и шаг изменения аргумента (DX), либо начальное значение и шаг аргумента (XH, DX) и количество рассчитываемых точек (N).
Особенности, которые надо учитывать в алгоритме:
1. Использовать циклический процесс.
2. Накапливать и выводить надо аргумент и функции.
3. Надо предусматривать средства контроля данных, если возможно аварийное завершение программы (знаменатель может быть равен нулю, аргумент логарифма или корня меньше нуля и т.п.). При этом надо формировать признаки завершения вычислительного процесса и вывод соответствующих сообщений.
Пример. Алгоритм вычисления таблицы значений функции
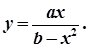
В данном случае таблица должна содержать два столбца; первый столбец для аргумента Х и второй - для функции У. В качестве исходных данных для организации вычислительного процесса зададим ХН, ДХ и N. Кроме того, входными данными являются параметры функции A и B. Результаты будем накапливать в массиве FY(100,2), то есть таблица может содержать не более 100 строк (количество строк в таблице определяется характером решаемой задачи и определяется программистом).
|
|
|
Функция содержит знаменатель, поэтому в алгоритме необходимо предусмотреть проверку знаменателя на равенство нулю. Так как нулевой может быть всего одна точка, то после вывода сообщения (например, такого: точка разрыва – знаменатель равен нулю") можно продолжить вычислительный процесс.
Схема алгоритма решения этой задачи приведена на рис.3.11.1. В алгоритме, кроме указанных выше переменных, используются следующие переменные: К – счетчик циклов (параметр цикла); Х – текущее значение аргумента; Z – значение знаменателя.
Во втором блоке на рис.3.11.1указан размер массива. После ввода исходных данных задаются начальные значения Х и К и далее организован циклический процесс вычисления функции У (цикл с предусловием). В каждом цикле сначала вычисляется значение знаменателя (Z) и осуществляется проверка Z на равенство нулю.
Рис.3.11.1
До сих пор мы рассматривали алгоритмы, в которых основными являются математические операции. Существует класс алгоритмов, в котором основными являются не математические вычисления, а операции сравнения и пересылки. Такие алгоритмы принято называть нечисловыми. Сюда относятся задачи связанные с:
- обработкой символьных данных;
- сортировкой данных;
- поиском данных.
3.12.1. Обработка символьных данных.
В ЭВМ можно хранить и обрабатывать не только числа, но и символы. Обычно для хранения символа используется ячейка память из восьми двоичных разрядов, в которой хранится код символа. Существуют различные системы кодирования символов, но всегда последовательности символов упорядочены и каждому символу соответствует определенный номер. Поэтому символы можно сравнивать и говорить о том, что один символ больше или меньше другого.
Существует много задач связанных с обработкой символьных данных: задачи связанные с построением редакторов; формирование сообщений программы; организация диалогового режима работы программы. При решении задач связанных с обработкой символьных данных можно использовать следующие типы данных (они имеются в языках программирования):
|
|
|
- символьные и строковые константы;
- символьные и строковые переменные;
- символьные и строковые массивы.
Пример 1.
Пусть последовательность символов (цифры и буквы латинского алфавита) хранится в массиве MS. Надо определить, сколько букв в этой последовательности.
Алгоритм. Так как символы пронумерованы последовательно в цикле будем сравнивать каждый элемент массива с символом 'A' (должно выполняться условие MS(K) >= 'A') и символом 'Z' (MS(K) <= 'Z'). Если эти два условия выполняются одновременно, то в данном элементе массива хранится буква и счетчик букв (обозначим его KS) надо увеличить на единицу.
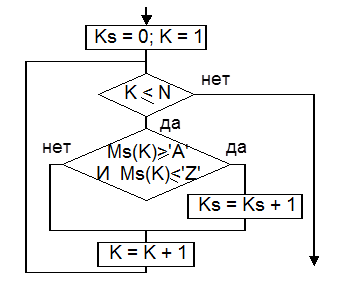
Рис.3.11.2.
Схема алгоритма решения этой задачи приведена на рис.3.11.2. В алгоритме используются: K – счетчик элементов массива; N – количество обрабатываемых элементов массива. Заметим, что символ "И" в блоке сравнения элементов массива – это логическая операция И.
Пример 2. Алгоритм исключения символа.
Пусть имеем строку символов в массиве MS. Надо составить алгоритм исключения из этой строки всех символов, заданных переменной SK, обрабатывать N элементов массива MS.
Идея алгоритма:
- в цикле определяем номер элемента массива MS, который совпадает с заданным символом SK;
- сдвигаем все символы, расположенные справа, на одну позицию влево
- заносим пробел на последнюю позицию.
Уточнение алгоритма: После каждого сдвига символов влево правую границу можно уменьшить на единицу.
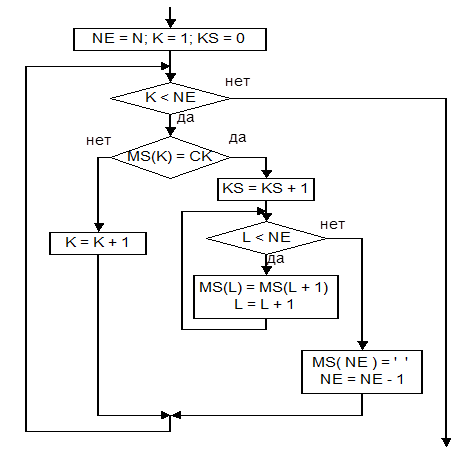
Рис.3.11.3.
Фрагмент схемы алгоритма исключения символов приведен на рис.3.11.3. В схеме алгоритма обозначено: N – количество символов в массиве MS; NE – динамическая длина массива; K, L – счетчики (параметры циклов); KS – количество исключенных символов.
3.12.2. Сортировка данных.
Существует большой класс задач, в которых надо упорядочивать данные (числа, последовательности символов) в определенном порядке – по возрастанию или по убыванию. Особенностью таких задач является то, что массив данных может быть большим – десятки и сотни тысяч данных, поэтому сортировать надо в самом массиве. Методы, использующие пересылку данных в другой массив, интереса не представляют.
|
|
|
Мерой эффективности алгоритмов сортировки являются количество сравнений (С) и количество пересылок данных (М). Простые методы требуют порядка С2 операций сравнения, а эффективные – порядка С log(C) операций. К настоящему времени придумано много различных алгоритмов сортировки. Все они делятся на три класса:
- сортировка выбором;
- сортировка включением;
- сортировка обменом.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1037; Нарушение авторских прав?; Мы поможем в написании вашей работы!