КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Современные проблемы развития элементной базы
Увеличение скорости вычислений влияет на коэффициент в функции роста. В определенных масштабах это будет давать значительный прирост эффективности, но при увеличении размерности входных данных этот выигрыш может быстро нивелироваться скорость роста функции.
Какие либо методы с уменьшением размерности тоже не всегда будут иметь значимый эффект. Разобьем наш массив на 4 части и каждую часть поручим выполнять отдельному ядру. Что мы получим? На сортировку каждой части понадобится ровно O((n / 4)^2). Возведем получившееся выражение в квадрат, получив таким образом сложность равную O(1/16*n^2 + n),
Поскольку анализ у нас асимптотический, то при достаточно больших n, ф-ия n^2 будет вносить гораздо больший вклад в итоговый результат, чем n и поэтому мы спокойно можем им пренебречь, как наиболее медленно возрастающем членом, также за малозначимостью принебрегаем коэффициентом 1/16, что в итоге дает нам все тоже O(n^2).
Небольшие размерности входных данных:
Сложность f=10x при нормальных размерах входных данных лучше g=x^2. Но при размерах <10 первый алгоритм эффективнее.
f является «о» малым от g, если для любого ε > 0 найдутся значения х при которых 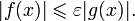
x^2 = o (x)
x^2 < ε *x при х< ε
Хотя f=x^2 растет быстрее g=x, в некоторых случаях εx>x^2 для любых коэффициентов.
Грубо говоря в применении к алгоритмам в данном случае функция с большей скоростью роста эффективна при малой размерности входных данных, и коэффициентами этого не поправить.
На определенном интервале коэффициенты влияют значительнее, чем зависимость от входных данных, или наоборот. Поэтому в каждом конкретном случае нужно смотреть что эффективнее, улучшать коэффициенты или зависимость от входа.
Амортизационный анализ применяется для оценки времени выполнения нескольких операций с какой-либо структурой данных (например, стеком). Чтобы оценить время выполнения какой-либо последовательности операций, достаточно умножить максимальную длительность операции на общее число операций. Иногда, однако, удаётся получить более точную оценку времени выполнения последовательности операций (или, что равносильно, среднего времени выполнения одной операции), используя тот факт, что во многих случаях после длительных операций несколько следующих операций выполняются быстро. Оценки такого рода называются амортизационным анализом (amortized analysis) структуры данных (точнее, её реализации).
Классы сложности:
В теории алгоритмов классами сложности называются множества вычислительных задач, примерно одинаковых по сложности вычисления. (P-сложные, экспоненциально сложные и др.).
Для каждого класса существует категория задач, которые являются «самыми сложными». Это означает, что любая задача из класса сводится к такой задаче, и притом сама задача лежит в классе. Такие задачи называют полными задачами для данного класса. Полные задачи — хороший инструмент для доказательства равенства классов. Достаточно для одной такой задачи предоставить алгоритм, решающий её и принадлежащий более маленькому классу, и равенство будет доказано.
К классу P относятся задачи, которые могут быть решены за время, полиномиально зависящее от объёма исходных данных, с помощью детерминированной вычислительной машины (например, машины Тьюринга).
NP — задачи, которые могут быть решены за полиномиально выраженное время с помощью недетерминированной вычислительной машины, то есть машины, следующее состояние которой не всегда однозначно определяется предыдущими. Работу такой машины можно представить как разветвляющийся на каждой неоднозначности процесс: задача считается решённой, если хотя бы одна ветвь процесса пришла к ответу.
Другое определение класса NP: к классу NP относятся задачи, решение которых мы можем проверить за полиномиальное время.
В общем случае нет оснований полагать, что для той или иной NP-задачи не может быть найдено P-решение. Вопрос о возможной эквивалентности классов P и NP (то есть о возможности нахождения P-решения для любой NP-задачи) считается многими одним из основных вопросов современной теории сложности алгоритмов.
Сама постановка вопроса об эквивалентности классов P и NP возможна благодаря введению понятия NP-полных задач. NP-полные задачи составляют подмножество NP-задач и отличаются тем свойством, что все NP-задачи могут быть тем или иным способом сведены к ним.
Из этого следует, что если для NP-полной задачи будет найдено P-решение, то P-решение будет найдено для всех задач класса NP. Это будет означать, что все задачи, принадлежащие классу NP, можно будет решать за полиномиальное время, что сулит огромную выгоду с вычислительной точки зрения. Сейчас NP-полные задачи можно решить за экспоненциальное время, что почти всегда неприемлемо.
В августе 2010 года Винэй Деолаликар разослал некоторым ученым на проверку своё доказательство неравенства P и NP. Стивен Кук назвал его «относительно серьезной попыткой решения проблемы P vs NP». Однако уже в том же месяце были найдены недостатки в доказательстве. Сейчас оно дорабатывается.
Обобщение детерминированной машины Тьюринга, в которой, из любого состояния и значений на ленте, машина может совершить один из нескольких (можно считать, без ограничения общности — двух) возможных переходов, а выбор осуществляется вероятностным образом (подбрасыванием монетки)
В теории алгоритмов классом сложности BPP (от англ. bounded-error, probabilistic, polynomial) называется класс предикатов, быстро (за полиномиальное время) вычислимых и дающих ответ с высокой вероятностью (причём, жертвуя временем, можно добиться сколь угодно высокой точности ответа). Задачи, решаемые вероятностными методами и лежащие в BPP, возникают на практике очень часто.
Это верно, поскольку если есть машина Тьюринга, распознающая язык с вероятностью ошибки p за время O(nk), то точность можно сколь угодно хорошо улучшить за счёт относительно небольшого прироста времени. Если мы запустим машину n раз подряд, а в качестве результата возьмём результат большинства запусков, то вероятность ошибки значительно упадёт, а время станет равным O(nk+1).
В теории алгоритмов классом сложности BQP (от англ. bounded error quantum polynomial time) называется класс проблем разрешимости, которые могут быть решены квантовым компьютером за полиномиальное время
Вопрос о существовании алгоритма факторизации с полиномиальной сложностью на классическом компьютере является одной из важных открытых проблем современной теории чисел. В то же время факторизация с полиномиальной сложностью возможна на квантовом компьютере с помощью алгоритма Шора (класс BQP).
Предполагаемая большая вычислительная сложность задачи факторизации лежит в основе криптостойкости некоторых алгоритмов шифрования с открытым ключом, таких как RSA.
Полный перебор
Метод ветвей и границ
Для ускорения перебора метод ветвей и границ использует отсев подмножеств допустимых решений, заведомо не содержащих оптимальных решений.
Распараллеливание вычислений
...
Динамическое программирование
разбиение задачи на последовательность простых
и оптимизация за счет выполнения каждой задачи только один раз
Эвристические алгоритмы
Эвристический алгоритм (эвристика) — алгоритм решения задачи, не имеющий строгого обоснования, но, тем не менее, дающий приемлемое решение задачи в большинстве практически значимых случаев.
эвристика, в отличие от корректного алгоритма решения задачи, обладает следующими особенностями:
Она не гарантирует нахождение лучшего решения.
Она не гарантирует нахождение решения, даже если оно заведомо существует (возможен «пропуск цели»).
Она может дать неверное решение в некоторых случаях.
Приближенные алгоритмы
...
В областях искусственного интеллекта, таких, как распознавание образов, эвристические алгоритмы широко применяются также и по причине отсутствия общего решения поставленной задачи. Различные эвристические подходы применяются в антивирусных программах, компьютерных играх и т. д
Системы компьютерной алгебры
Система компьютерной алгебры (СКА, англ. computer algebra system, CAS) — это приложение, помогающее выполнять символьные вычисления. Основная задача СКА — это работа с математическими выражениями в аналитической (символьной) форме.
Аналитическое вычисление не сталкивается с такими проблемами численного программирования как ошибки округления, проблемы сходимости и проблемы устойчивости.
Основными проблемами самого процесса вычисления является чаще всего экспоненциальное время работы алгоритмов и промежуточное разрастание выражения во время вычислений
Среди различных вариантов выбранного процесса вычисления можно отметить два следующих, а именно, полное рекурсивное вычисление выражения и метод отложенных вычислений.
Data Mining
Развитие методов записи и хранения данных привело к бурному росту объемов собираемой и анализируемой информации. Объемы данных настолько внушительны, что человеку просто не по силам проанализировать их самостоятельно, хотя необходимость проведения такого анализа вполне очевидна, ведь в этих "сырых" данных заключены знания, которые могут быть использованы при принятии решений. Для того чтобы провести автоматический анализ данных, используется Data Mining.
Data Mining – это процесс обнаружения в "сырых" данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Методы Data Mining лежат на стыке баз данных, статистики и искусственного интеллекта
Задачи, решаемые методами Data Mining, принято разделять на
описательные (англ. descriptive);
предсказательные (англ. predictive).
В описательных задачах самое главное — это дать наглядное описание имеющихся скрытых закономерностей, в то время как в предсказательных задачах на первом плане стоит вопрос о предсказании для тех случаев, для которых данных ещё нет.
Задачи, решаемые методами Data Mining:
1. Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
2. Регрессия, в том числе задачи прогнозирования. Установление зависимости непрерывных выходных от входных переменных.
3. Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов. Объекты внутри кластера должны быть "похожими" друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация.
4. Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
5. Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y.
6. Анализ отклонений – выявление наиболее нехарактерных шаблонов.
Data Mining основаны на применении
1. деревьев решений,
2. нейронных сетей, нечеткой логики.
3. генетических алгоритмов, эволюционного программирования,
4. ассоциативной памяти,
Деревья принятия решений обычно используются для решения задач классификации данных или, иначе говоря, для задачи аппроксимации заданной булевой функции.
Дерево принятия решений — это дерево, на ребрах которого записаны атрибуты, от которых зависит целевая функция, в листьях записаны значения целевой функции, а в остальных узлах — атрибуты, по которым различаются случаи. Чтобы классифицировать новый случай, надо спуститься по дереву до листа и выдать соответствующее значение.
Предположим, что нас интересует, выиграет ли наша любимая футбольная команда следующий матч. Мы знаем, что это зависит от ряда параметров; перечислять их все — задача безнадежная, поэтому ограничимся основными:
1. выше ли находится соперник по турнирной таблице;
2. дома ли играется матч;
3. пропускает ли матч кто-либо из лидеров команды;
4. идет ли дождь.
http://compblog.ilc.edu.ru/blog/63.html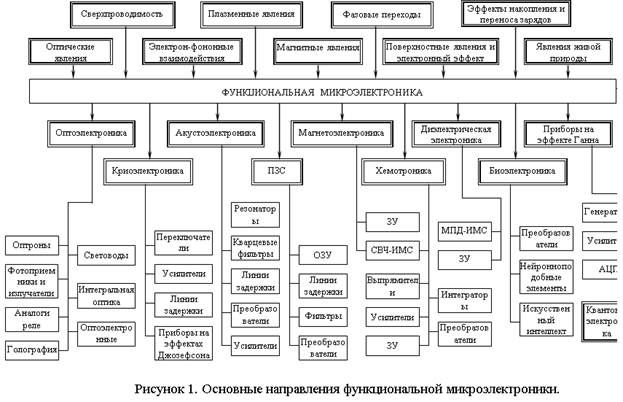
- Квантовый компьютер
- Механический компьютер
- Оптический компьютер
- Электронный компьютер
- Биологический компьютер
переход к конструированию ЭВМ на СБИС и ультраСБИС должен сопровождаться снижением тактовой частоты работы схемы. Дальнейший прогресс в повышении производительности может быть обеспечен либо за счет архитектурных решений, либо за счет новых принципов построения и работы микросхем.
Проблемы развития элементной базы:
Новые литографии и сверхточные материалы
Степень микроминиатюризации, размер кристалла ИС, производительность и стоимость технологии напрямую определяется типом литографии. 5-10 лет назад доминировала оптическая литография. Дальнейшие успехи связаны с электронной (лазерной), ионной и рентгеновской литографией. Послойные рисунки на моторезисторе микросхем наносились световым лучом, а эта литография позволяла получить более тонкий луч.
Сверхчистые материалы и высоковакуумные технологии
Микроскопическая толщина линий, сравнимая с диаметром молекул, требует высокой чистоты используемых и напыляемых материалов, применения вакуумных установок и снижения рабочих температур. Поэтому новые заводы по производству микросхем представляют собой уникальное оборудование, размещаемое в “сверхчистых” помещениях.
Борьба с потребляемой и рассеиваемой мощностью
Уменьшение линейных размеров микросхем и повышение уровня их интеграции заставляют проектировщиков искать средства борьбы с потребляемой() и рассеиваемой() мощностью. При сокращении линейных размеров микросхем в 2 раза, их объёмы изменяются в 8 раз. Пропорционально этим цифрам должны меняться значения и, иначе схемы будут перегреваться и выходить из строя. За последние 10 лет быстродействия процессоров Intel выросло в 5-6 раз, а энергопотребление в 18 раз. Напряжение линейных микросхем упало до 1,5V и менее, а напряжение питания новейших многоядерных микропроцессов Intel = 1,35V. Дальнейшее понижение нежелательно, так как в электронных схемах всегда должно быть обеспечено необходимое соотношение “сигнал-шум”, характеризующее устойчивую работу компьютера. Протекание тока по микроскопическим проводникам сопряжено с выделением большого количества тепла. Поэтому, создавая сверхбольшие интегральные схемы, проектировщики вынуждены снижать тактовую частоту работы процессора. Дальнейший прогресс в повышении производительности может быть обеспечен либо за счёт архитектурных решений, либо за счёт новых принципов построения и работы микросхем.
Пути развития элементарной базы:
|
|
Дата добавления: 2014-01-07; Просмотров: 829; Нарушение авторских прав?; Мы поможем в написании вашей работы!