КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Матричний процесор
|
|
|
|
Призначення матричних обчислювальних систем багато в чому схоже з призначенням векторних КС - обробка великих масивів даних. В основі матричних систем лежить матричний процесор (array processor), що складається з регулярного масиву процесорних елементів (ПЕ). Системи подібного типу мають загальний пристрій, що управляє та генерує потік команд, і велике число ПЕ, що працюють паралельно і обробляють кожен свій потік даних. З метою забезпечення достатньої ефективності системи при рішенні широкого кола завдань необхідно організувати зв'язки між процесорними елементами так, щоб якнайповніше завантажити процесори роботою. Саме характер зв'язків між ПЕ і визначає різні властивості системи.
Між матричними і векторними системами є істотна різниця: матричний процесор інтегрує безліч ідентичних функціональних блоків (ФБ), що логічно об'єднані в матрицю і працюють в SIMD-стилі. Не так істотно, як конструктивно реалізована матриця процесорних елементів - на єдиному кристалі або на декількох. Важливий сам принцип - ФБ логічно зкомпоновані в матрицю і працюють синхронно, тобто присутній тільки один потік команд для всіх. Векторний процесор має вбудовані команди для обробки векторів даних, що дозволяє ефективно завантажити конвеєр з функціональних блоків. У свою чергу, векторні процесори простіше використовувати, тому що команди для обробки векторів - це більш зручніша для людини модель програмування, чим SIMD.
Паралельна обробка множинних елементів даних здійснюється масивом процесорів (Мпр). Єдиний потік команд, керуючий обробкою даних в масиві процесорів, генерується контролером масиву процесорів (КМП). КМП виконує послідовний програмний код, реалізує операції умовного і безумовного переходів, транслює в Мпр команди, дані і сигнали управління (рис.4.1).
|
|
|

Рисунок 4.1 – Матричний процесор
4.2 Матрична комп’ютерна система
Узагальнена модель матричної КС зображена на рис.4.2.
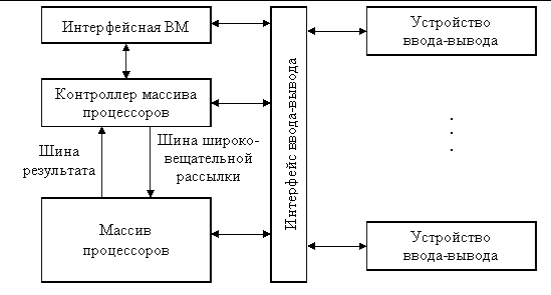
Рисунок 4.2 – Узагальнена модель матричної КС
Компоненти матричної КС:
- масив процесорів (Мпр) здійснює паралельну обробку множинних елементів даних;
- контроллер масиву процесорів (КМП) генерує єдиний потік команд, керує обробкою даних в масиві процесорів, виконує послідовний програмний код, реалізує операції умовного і безумовного переходів, транслює в Мпр команди, дані і сигнали управління. Команди обробляються процесорами в режимі жорсткої синхронізації;
- сигнали управління використовуються для синхронізації команд і пересилок, а також для управління процесом обчислень, зокрема визначають, які процесори масиву повинні виконувати операцію, а які - ні;
- шина широкомовної розсилки служить для передачі команд, даних і сигналів управління з КМП в масив процесорів;
- шина результату служить для трансляції результатів обчислень з Мпр в КМП (це потрібно, оскільки виконання операцій умовного переходу залежить від результатів обчислень);
- інтерфейсна ОМ (front-end computer) служить для забезпечення користувача зручним інтерфейсом при створенні і відладці програм. В ролі такої ОМ виступає універсальна обчислювальна машина, на яку додатково покладається завдання завантаження програм і даних в КМП. Крім того, завантаження програм і даних в КМП може проводитися і безпосередньо з пристроїв введення/виведення, наприклад з магнітних дисків. Після завантаження КМП приступає до виконання програми, транслюючи в Мпр по широкомовній шині відповідні SIMD-команди.
Розглядаючи масив процесорів, слід враховувати, що для зберігання множинних наборів даних в ніьому, крім безлічі процесорів, повинно бути присутнім і безліч модулів пам'яті. Крім того, в масиві повинна бути реалізована мережа взаємозв'язків, як між процесорами, так і між процесорами і модулями пам'яті.
|
|
|
Таким чином, під терміном масив процесорів розуміють блок, що складається з процесорів, модулів пам'яті і мережі з'єднань. Додаткову гнучкість при роботі з даною системою забезпечує механізм маскування, що дозволяє залучати до участі в операціях лише певну підмножину з наявних в масиві процесорів. Маскування реалізується як на стадії компіляції, так і на етапі виконання, при цьому процесори, виключені шляхом установки в нуль відповідних бітів маски, під час виконання команди простоюють.
Інтерфейсна ОМ (ІОМ) сполучає матричну SIMD-систему із зовнішнім світом, використовуючи для цього який-небудь з мережевих інтерфейсів, наприклад Ethernet, як це має місце в системі MasPar MP-1. Інтерфейсна ОМ працює під управлінням операційної системи, найчастіше ОС UNIX. На ІОМ користувачі готують, компілюють і відладжують свої програми. Спочатку програми завантажуються з інтерфейсної ОМ в контроллер управління масивом процесорів. Потім КМП в процесі виконання програми розподіляє команди і дані по процесорних елементах масиву. У деяких КС, наприклад в Massively Parallel Computer MPP, при створенні, компіляції і відладці програм КМП і інтерфейсна ОМ використовуються спільно.
На роль ІОМ підходять різні обчислювальні машини. Так, в системі СМ-2 в цій якості виступає робоча станція SUN-4, в системі MasPar - DECstation 3000, а в системі МРР - DEC VAX-11/78.
Функції контролера масиву процесорів:
- виконує послідовний програмний код;
- реалізує команди розгалуження програми;
- транслює команди і сигнали управління в процесорні елементи.
Рис.4.3. ілюструє одну з можливих реалізацій КМП, зокрема прийняту в пристрої управління системи PASM (Partitioned SIMD/MIMD computer).
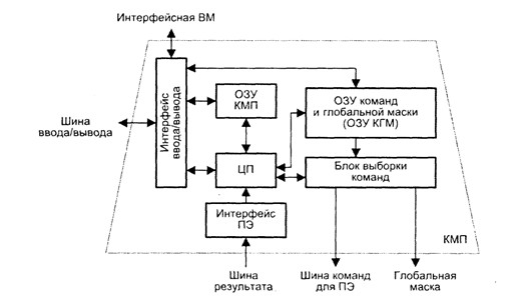
Рисунок 4.3 – Контролер масиву процесорів
При завантаженні з ІОМ програма через інтерфейс введення/виведення вводиться в оперативний запам’ятовуючий пристрій КМП (ОЗП КМП). Команди для процесорних елементів і глобальна маска, що формується на етапі компіляції, також через інтерфейс введення/виведення завантажуються в ОЗП команд і глобальної маски (ОЗП КГМ). Потім КМП починає виконувати програму, витягуючи або одну скалярну команду з ОЗП КМП, або множинні команди з ОЗП КГМ. Скалярні команди - команди, що здійснюють операції над скалярними даними, що зберігаються в КМП та виконуються центральним процесором (ЦП) контролера масиву процесорів. У свою чергу, команди, що оперують паралельними змінними, що зберігаються в кожному ПЕ, перетворюються в блоці вибірки команд в простіші одиниці виконання - нанокоманди. Нанокоманди спільно з маскою пересилаються через шину команд для ПЕ на виконання в масив процесорів. Наприклад, команда складання 32-розрядних слів в КМП системи МРР перетвориться в 32 нанокоманди однорозрядного складання, які кожним ПЕ обробляються послідовно. У більшості алгоритмів подальший порядок обчислень залежить від результатів і/або прапорів умов попередніх операцій. Для забезпечення такого режиму в матричних системах статусна інформація, що зберігається в процесорних елементах, повинна бути зібрана в єдине слово і передана в КМП для вироблення рішення про розгалуження програми. Наприклад, в пропозиції
|
|
|
IF A (умова A) THEN DO В
оператор В буде виконаний, якщо умова А справедлива у всіх ПЕ. Для коректного включення/відключення процесорних елементів КМП повинен знати результат перевірки умови А у всіх ПЕ. Така інформація передається в КМП по однонаправленій шині результату. У системі СМ-2 ця шина названа GLOBAL. У системі МРР для тієї ж мети організована структура, звана деревом SUM-OR. Кожен ПЕ розміщує вміст свого однорозрядного регістра ознаки на вході дерева, яке за допомогою операції логічного складання комбінує цю інформацію і формує слово результату, використовуване в КМП для ухвалення рішення.
4.3 Архітектура матричних комп’ютерних систем
У матричних SIMD-системах поширення набули два основні типи архітектурної організації масиву процесорних елементів.
У першому варіанті (рис.4.4), відомому як архітектура типу “процесорний елемент - процесорний елемент” (“ПЕ-ПЕ”):
- N процесорних елементів (ПЕ) зв'язані між собою мережею з'єднань;
|
|
|
- кожен ПЕ - це процесор з локальною пам'яттю;
- процесорні елементи виконують команди, що надходять з КМП по шині широкомовної розсилки, і обробляють дані що зберігаються в їх локальній пам'яті або поступають з КМП;
- обмін даними між процесорними елементами проводиться по мережі з'єднань, тоді як шина введення/виведення служить для обміну інформацією між ПЕ і пристроями введення/виведення;
- для трансляції результатів з окремих ПЕ в контроллер масиву процесорів служить шина результату;
- завдяки використанню локальної пам'яті апаратні засоби КС даного типу можуть бути побудовані дуже ефективно. У багатьох алгоритмах дії по пересилці інформації здебільшого локальні, тобто відбуваються між найближчими сусідами. З цієї причини архітектура, де кожен ПЕ пов'язаний тільки з сусідніми, дуже популярна. Як приклади обчислювальних систем з даною архітектурою можна згадати MasPar MP-1, Connection Machine CM-2, GF11, DAP, МРР, STARAN, PEPE, ILLIAC IV.
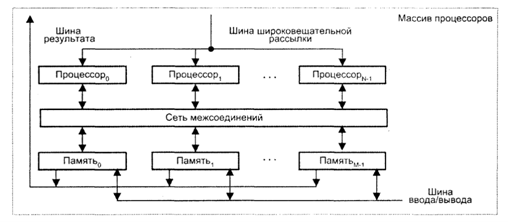
Рисунок 4.4 – Архітектура типу “процесорний елемент - процесорний елемент”
Другий вид архітектури – “процесор-пам'ять” (рис.4.5). В такій конфігурації двонаправлена мережа з'єднань зв'язує N процесорів з М модулями пам'яті. Процесори управляються КМП через широкомовну шину. Обмін даними між процесорами здійснюється як через мережу, так і через модулі пам'яті. Пересилка даних між модулями пам'яті і пристроями введення/виведення забезпечується шиною введення/ виведення. Для передачі даних з конкретного модуля пам'яті в КМП служить шина результату. Прикладами КС з розглянутою архітектурою можуть служити Burroughs Scientific Processor (BSP), Texas Reconfigurable Array Computer (TRAC).
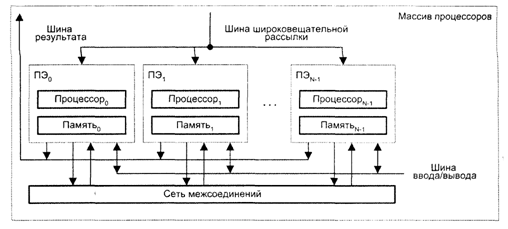
Рисунок 4.5 – Архітектура типу “процесор-пам'ять”
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 2660; Нарушение авторских прав?; Мы поможем в написании вашей работы!