КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Мультипроцесори складно будувати, але легко програмувати. Мультикомпьютеры легко будувати, але складно програмувати
Тому стали робитися спроби створення гібридних систем, які відносно легко конструювати і відносно легко програмувати. Це привело до усвідомлення того, що сумісну пам'ять можна реалізовувати по-різному, і в кожному випадку будуть якісь переваги і недоліки.
Практично всі дослідження в області архітектури з паралельною обробкою направлені на створення гібридних форм, які поєднують в собі переваги обох архітектур. Тут важливо отримати таку систему, яка продовжуватиме справно працювати при додаванні все нових і нових процесорів.
9.3 Багаторівнева організація загальної пам'яті
Сучасні комп'ютерні системи не монолітні, а складаються з ряду рівнів. Це дає можливість реалізувати загальну пам'ять на будь-якому з декількох рівнів:
- загальна пам'ять реалізована на апаратному забезпеченні (одна копія операційної системи з однією таблицею розподілу пам'яті. Для ОС пам'ять монолітна);
- загальна пам'ять реалізована на основі ОС і апаратного забезпечення (такий підхід називається DSM ( Distributed Shared Memory - розподілена спільно використовувана пам'ять ). Кожна машина містить свою власну віртуальну пам'ять і власні таблиці сторінок. По суті, операційна система просто викликає бракуючі сторінки не з диска, а з пам'яті. Але у користувача створюється враження, що машина містить загальну розділену пам'ять);
- реалізація загальної розділеної пам'яті на рівні програмного забезпечення (при такому підході абстракцію розділеної пам'яті створює мова програмування, і ця абстракція реалізується компілятором).
9.4 Пам'ять з чергуванням адрес
Фізично пам'ять комп’ютерної системи складається з декількох модулів (банків), при цьому істотним питанням є те, як в цьому випадку розподілений адресний простір (набір всіх адрес, які може сформувати процесор). Один із способів розподілу віртуальних адрес по модулях пам'яті полягає в розбитті адресного простору на послідовні блоки. Якщо пам'ять складається з n банків, то комірка з адресою i при поблочному розбитті знаходитиметься в банку з номером i/n. У системі пам'яті з чергуванням адрес (interleaved memory) послідовні адреси розташовуються в різних банках: комірка з адресою i знаходиться в банку з номером i mod n. Нехай, наприклад, пам'ять складається з чотирьох банків, по 256 байт в кожному. У схемі, орієнтованій на блокову адресацію, першому банку будуть виділені віртуальні адреси 0-255, другому - 256-511 і т.д. В схемі з чергуванням адрес послідовні комірки в першому банку матимуть віртуальні адреси 0, 4, 8, а у другому банку - 1, 5, 9 і т.д.
Розподіл адресного простору по модулях дає можливість одночасної обробки запитів на доступ до пам'яті, якщо відповідні адреси відносяться до різних банків. Процесор може в одному з циклів зажадати доступ до комірки i, а в наступному циклі - до комірки j. Якщо i і j знаходяться в різних банках, інформація буде передана в послідовних циклах. Тут під циклом розуміємо цикл процесора, тоді як повний цикл пам'яті займає декілька циклів процесора. Таким чином, в даному випадку процесор не повинен чекати, поки буде завершений повний цикл звернення до комірки i. Розглянутий прийом дозволяє підвищити пропускну спроможність: якщо система пам'яті складається з достатнього числа банків, є можливість обміну інформацією між процесором і пам'яттю з швидкістю одне слово за цикл процесора, незалежно від тривалості циклу пам'яті.
Рішення про те, який варіант розподілу адрес вибрати (поблочний або з розшаруванням), залежить від очікуваного порядку доступу до інформації. Програми компілюються так, що послідовні команди розташовуються в комірках з послідовними адресами, тому висока вірогідність, що після команди, витягнутої з комірки з адресою i, виконуватиметься команда з комірки i +1. Елементи векторів компілятор також поміщає в послідовні комірки, тому в операціях з векторами можна використовувати переваги методу чергування (рис.9.3). З цієї причини у векторних процесорах зазвичай застосовується який-небудь варіант чергування адрес. У мультипроцесорах із спільно використовуваною пам'яттю, проте, використовується поблочна адресація, оскільки схеми звертання до пам'яті в MIMD-системах можуть сильно відрізнятися. У таких системах метою є з'єднати процесор з блоком пам'яті і задіяти максимум інформації, що знаходиться в ньому, перш ніж перемкнутися на інший блок пам'яті.
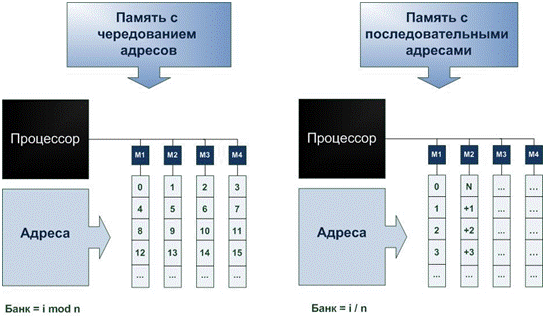
Рисунок 9.3 – Пам'ять з чергуванням адрес та пам'ять з послідовними адресами
9.5 Асоціативна пам'ять
Зазвичай в пристроях, що запам'ятовують, доступ до інформації вимагає вказівки адреси комірки. Проте значно зручніше шукати інформацію не за адресою, а спираючись на яку-небудь характерну ознаку, що міститься в самій інформації. Такий принцип лежить в основі ЗП, відомого як асоціативний пристрій, що запам'ятовує (АЗП). У літературі зустрічаються і інші назви подібного ЗП: пам'ять, що адресується за змістом (content addressable memory); пам'ять, що адресується по даним (data addressable memory); пам'ять з паралельним пошуком (parallel search memory); каталогова пам'ять (catalog memory); інформаційний ЗП (information storage); тег. пам'ять (tag memory).
Асоціативний ЗП - це пристрій, здатний зберігати інформацію, порівнювати її з деяким заданим зразком і вказувати на їх відповідність або невідповідність один одному (рис.9.4).
На відміну від звичайної машинної пам'яті (пам'яті довільного доступу або RAM), в якій користувач задає адресу пам'яті і ОЗП повертає слово даних, що зберігається за цією адресою, АП розроблена так, щоб користувач задавав слово даних, і АП шукає його у всій пам'яті, щоб з'ясувати, чи зберігається воно де-небудь в ній. Якщо слово даних знайдене, АП повертає список одної або більше адрес зберігання, де слово було знайдене (і в деякій архітектурі, також повертає саме слово даних, або інші зв'язані частини даних). Таким чином, АП - апаратна реалізація того, що в термінах програмування назвали б асоціативним масивом.
Асоціативна ознака - ознака, по якій проводиться пошук інформації.
Ознака пошуку - кодова комбінація, виступаюча в ролі зразка для пошуку.
Асоціативна ознака може бути частиною шуканої інформації або додатково додаватися їй. У останньому випадку її прийнято називати тегом або ярликом.
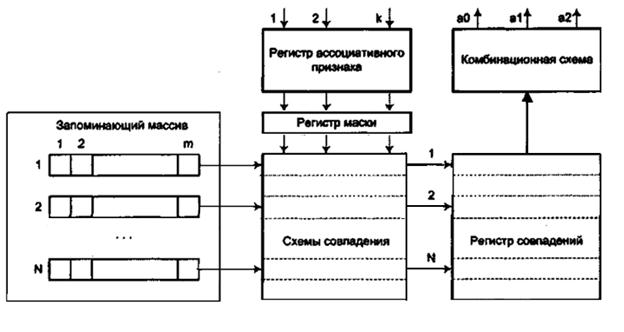
Рисунок 9.4 – Структура асоціативного ЗП
Асоціативний ЗП включає:
- запам'ятовуючий масив для зберігання N m-розрядних слів, в кожному з яких декілька молодших розрядів займає службова інформація;
- регістр асоціативної ознаки, куди розміщується код шуканої інформації (ознака пошуку). Розрядність регістра k зазвичай менше довжини слова т;
- схеми співпадіння, які використовуються для паралельного порівняння кожного біта всіх слів, що зберігаються, з відповідним бітом ознаки пошуку і вироблення сигналів співпадіння;
- регістр співпадіння, де кожній комірці запам'ятовуючого масиву відповідає один розряд, в який заноситься одиниця, якщо всі розряди відповідної комірки співпали з однойменними розрядами ознаки пошуку;
- регістр маски, що дозволяє заборонити порівняння певних бітів;
- комбінаційну схему, яка на підставі аналізу вмісту регістра співпадіння формує сигнали, що характеризують результати пошуку інформації.
При зверненні до АЗП спочатку в регістрі маски обнуляються розряди, які не повинні враховуватися при пошуку інформації. Всі розряди регістра співпадіння встановлюються в одиничний стан. Після цього в регістр асоціативної ознаки заноситься код шуканої інформації (ознака пошуку) і починається її пошук, в процесі якого схеми співпадіння одночасно порівнюють перший біт всіх комірок запам'ятовуючого масиву з першим бітом ознаки пошуку. Ті схеми, які зафіксували неспівпадання, формують сигнал, що переводить відповідний біт регістра співпадіння в нульовий стан. Так само відбувається процес пошуку і для решти незамаскованих бітів ознаки пошуку. У результаті одиниці зберігаються лише в тих розрядах регістра співпадіння, які відповідають коміркам, де знаходиться шукана інформація. Конфігурація одиниць в регістрі співпадінь використовується як адреси, по яких проводиться прочитування з запам'ятовуючого масиву. Із-за того що результати пошуку можуть виявитися неоднозначними, вміст регістра співпадіння подається на комбінаційну схему, де формуються сигнали, що сповіщають про те, що шукана інформація:
- а0 - не знайдена;
- а1 - міститься в одній комірці;
- а2 - міститься більш ніж в одній комірці.
Формування вмісту регістра співпадіння і сигналів a0, a1, а2 носить назву операції контролю асоціації. Вона є складовою частиною операцій прочитування і запису, хоча може мати і самостійне значення.
При прочитуванні спочатку проводиться контроль асоціації по аргументу пошуку. Потім, при а0=1 прочитування відміняється через відсутність шуканої інформації, при a1=1 прочитується слово, на яке указує одиниця в регістрі збігів, а при а2=1 скидається сама старша одиниця в регістрі збігів і витягується відповідне їй слово. Повторюючи цю операцію, можна послідовно рахувати всі слова.
Запис в АП проводиться без вказівки конкретної адреси, в першу вільну комірку. Для відшукання вільної комірки виконується операція прочитування, в якій не замасковані тільки службові розряди, що показують, як давно проводилося звернення до даної комірки, і вільною вважається або порожня комірка, або та, яка найдовше не використовувалася.
Головна перевага асоціативних ЗП визначається тим, що час пошуку інформації залежить тільки від числа розрядів в ознаці пошуку і швидкості опиту розрядів і не залежить від числа комірок в запам'ятовуючому масиві.
Спільність ідеї асоціативного пошуку інформації зовсім не виключає різноманітності архітектури АЗП. Конкретна архітектура визначається поєднанням чотирьох чинників:
- виду пошуку інформації;
- техніки порівняння ознак;
- способу прочитування інформації при множинних співпадіннях;
- способу запису інформації.
У кожному конкретному застосуванні АЗП завдання пошуку інформації може формулюватися по-різному.
Види пошуку інформації:
- простий (потрібний повний збіг всіх розрядів ознаки пошуку з однойменними розрядами слів, що зберігаються в запам'ятовуючому масиві).
- складний:
- пошук всіх слів, великих або менших заданого. Пошук слів в заданих межах.
- пошук максимуму або мінімуму.
Багатократна вибірка з АЗП слова з максимальним або мінімальним значенням асоціативної ознаки (з виключенням його з подальшого пошуку), по суті, є впорядкованою вибіркою інформації. Впорядковану вибірку можна забезпечити і іншим способом, якщо вести пошук слів, асоціативна ознака яких по відношенню до ознаки опиту є найближчим великим або меншим значенням.
Очевидно, що реалізація складних методів пошуку пов'язана з відповідними змінами в архітектурі АЗП, зокрема з ускладненням схеми ЗП і введенням в неї додаткової логіки.
Техніка порівняння ознак
При побудові АЗУ вибирають з чотирьох варіантів організації опиту вмісту пам'яті. Варіанти ці можуть комбінуватися паралельно по групі розрядів і послідовно по групах. У плані часу пошуку найбільш ефективним можна рахувати паралельний опит як по словах, так і по розрядах, але не всі види запам'ятовуючих елементів допускають таку можливість.
Спосіб прочитування інформації при множинних співпадіннях:
- з ланцюгом черговості (за допомогою достатньо складного пристрою, де фіксуються слова, створюючі багатозначну відповідь. Ланцюг черговості дозволяє проводити читання слів в порядку зростання номера комірки АЗП незалежно від величини асоціативних ознак);
- алгоритмічно (в результаті серії опитувань).
Спосіб запису інформації:
- за адресою;
- з сортуванням інформації на вході АЗП по величині асоціативної ознаки (місцеположення комірки, куди буде поміщено нове слово, залежить від співвідношення асоціативних ознак знов записуваного слова і слів, що вже зберігаються в АЗП).
- по збігу ознак;
- з ланцюгом черговості.
Через високу вартість АЗП рідко використовується як самостійний вид пам'яті.
Контрольні запитання
1 Як здійснюється виконання команди Load R0, i в комп’ютерних системах з загальною пам’яттю?
2 Як організована багаторівнева загальна пам'ять?
3 Яка структура асоціативного запам’ятовуючого пристрою?
4 Як організована асоціативна пам'ять?
5 Як працює пам'ять з чергуванням адрес?
Лекція № 10
|
Дата добавления: 2014-01-07; Просмотров: 301; Нарушение авторских прав?; Мы поможем в написании вашей работы!