КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Функції роботи зі списками
Підведення проміжних підсумків
Відсортувавши список та відфільтрувавши у ньому тільки потрібні записи, можна скористатися командою «Данные\Итоги» для одержання різноманітних підсумкових даних.
Командою «Итоги» можна додати підсумкові рядки для кожної групи даних у списку, а також виконати інші розрахунки на груповому рівні. За допомогою цієї команди неважко обчислити, наприклад, середнє значення заданого поля для кожної групи записів, знайти кількість записів у кожній групі, кількість порожніх елементів у кожній групі, обчислити стандартне відхилення для кожної групи і т. д. Можна підвести також і загальні підсумки, застосувавши обрану функцію не тільки до груп записів, але і до всього списку. Користувач може задати також місце розташування підсумків наприкінці або на початку списку, що буває істотно для довгих списків. Можна додати також проміжні підсумки для окремих підгруп існуючих груп записів і створити, таким чином, вкладені проміжні підсумки.
Для створення проміжних підсумків необхідно:
1. Відсортувати список по полю, по якому окремі записи повинні бути розбиті на групи.
2. Виконати команду «Данные\Итоги».
3. У вікні діалогу «Промежуточные итоги» зі списку «При каждом изменении в» виберіть поле, по якому список розбитий на групи записів.
4. У списку «Операция» оберіть функцію, що повинна використовуватися при визначенні проміжних підсумків.
5. У полі «Добавить итоги по» вкажіть поля, по яким повинні бути визначені проміжні підсумки.
6. У разі потреби, скиньте прапорець «Итоги под данными», щоб відобразити рядки з підсумками над відповідними даними.
7. Якщо окремі групи записів повинні бути розташовані та виведені до друку на різних сторінках, встановіть прапорець параметра «Конец страницы между группами».
8. Закрийте вікно діалогу натисканням кнопки «OK».
Excel пропонує користувачеві групу функцій «Работа с базой данных», призначених для обробки списків. Більшість з цих функцій мають “аналоги” у групі функцій «Статистические». Наприклад, БДСУММ() та СУММ(), ДСРЗНАЧ() та СРЗНАЧ() і т. д. Головна відмінність зводиться до того, що функції зазначеної групи баз даних дозволяють опрацьовувати тільки ті клітинки діапазону даних, що задовольняють заданим критеріям.
Загальні правила звертання до функцій баз даних наступні:
1. Перший аргумент задає весь список, а не окремий стовпчик.
2. Другий аргумент задає поле (стовпчик), елементи якого необхідно опрацювати. Другий аргумент може бути іменем поля (заголовком стовпчика) у вигляді текстової константи або порядковим номером поля (стовпчика) у списку.
3. Третій аргумент задає діапазон критеріїв.
Зазначені функції виглядають дещо складніше, ніж їх “статистичні аналоги”, але є більш потужними та гнучкими. Вони дозволяють об'єднати виконання обчислень та відбір даних, не вимагаючи попередньої фільтрації та копіювання потрібних даних. Функції даної групи дозволяють обчислювати суму та добуток, знаходити мінімальні та максимальні значення, визначати середнє значення, підраховувати кількість записів, оцінювати дисперсію та стандартне відхилення, вибирати окреме значення зі списку.
Лекція 17
МАТЕМАТИЧНА СТАТИСТИКА В ЕХСЕL
1 Статистичні функції. Статистична обробка даних інженерного експерименту.
2 Числові характеристики дискретних випадкових величин.
3 Оцінка параметрів розподілу випадкових величин.
Зараз в процесі обробки та інтерпретації даних великого значення набувають ймовірнісно-статистичні методи аналізу. Дані, що отримані в окремих точках спостережень, варто розглядати як випадкові події. Теорія ймовірностей вивчає закономірності випадкових подій у часі та просторі і прийоми їх кількісного опису.
Аналіз даних проводиться із застосуванням методів математичної статистики, яка дає можливість вивести оцінки характеристик випадкової величини серед яких використовуються: числові характеристики; характеристики розподілу; характеристики взаємозв’язку.
До основних числових характеристик відносяться: математичне очікування (середнє арифметичне), мода, медіана, дисперсія, середньоквадратичне відхилення, коефіцієнт варіації, асиметрія, ексцес. Розрахувати перераховані статистичні характеристики можна за допомогою зазначених нижче формул, так і статистичних функцій Excel.
Якщо виміри виконані в одинакових умовах, тобто рівноточні, то центр групування результатів таких вимірів визначається середнім арифметичним (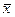 )
)
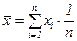 (17.1)
(17.1)
функція Excel – СРЗНАЧ(число1; число2;…).
Мода - це найбільш ймовірне значення випадкової величини МОДА (число1; число2;…).
Медіана - таке значення випадкової величини відносно якого одинаково ймовірно прояв випадкової величини більше або менше цього значення МЕДИАНА (число1; число2;…).
Дисперсія (s2) – це математичне очікування квадрату відхилення випадкової величини від її математичного відхилення ДИСП(число1; число2;…)
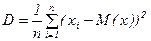 (17.2)
(17.2)
Середньоквадратичне відхилення s - міра розсіювання окремих даних навколо середнього арифметичного. СТАНДОТКЛОН(число1; число2;…)
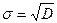 (17.3)
(17.3)
Коефіцієнт асиметрії – характеризує ступінь несиметричності розподілу відносно середнього. Додатня асиметрія вказує на відхилення розподілу в бік додатніх значень, від’ємна асиметрія вказує на відхилення розподілу в бік від’ємних значень. СКОС(число1; число2;…)
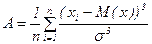 (17.4)
(17.4)
Коефіцієнт ексцесу - характеризує відносну гостроту або згладженість розподілу порівняно з нормальним розподілом. Додатній ексцес означає відносно гострокіневий розподіл, від’ємний – відносно згладжений розподіл. ЭКСЦЕСС(число1; число2;…).
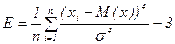 (17.5)
(17.5)
Для всіх перерахованих функцій кількість аргументів обмежена до 30.
Якщо об’єм вибірки невеликий (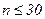 ), то за розрахованими значеннями коефіцієнтів асиметрії та ексцесу можна судити про нормальність розподілу, для іншого розподілу статистичні оцінки можуть бути несправедливими. Будь-які параметри вибірки, в тому числі асиметрія та ексцес є випадковими аеличинами, отже навіть для нормального розподілу можуть відрізнятись від нуля. Розраховують емпіричні дисперсії асиметрії та ексцесу:
), то за розрахованими значеннями коефіцієнтів асиметрії та ексцесу можна судити про нормальність розподілу, для іншого розподілу статистичні оцінки можуть бути несправедливими. Будь-які параметри вибірки, в тому числі асиметрія та ексцес є випадковими аеличинами, отже навіть для нормального розподілу можуть відрізнятись від нуля. Розраховують емпіричні дисперсії асиметрії та ексцесу:
 (17.6)
(17.6)
За такими дисперсіями можна оцінити, чи суттєво вибіркові асиметрія та ексцес відхиляються від своїх маткматичних очікувань, тобто від нуля. Якщо
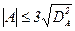 і
і 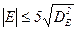 (17.7),
(17.7),
то робимо висновок, що спостережений розподіл нормальний, в протилежному випадку гіпотезу нормальності варто відкинути або вважвти сумнівною.
Гістограма – спрощена модель кривої густини розподілу випадкової величини. Побудувавши її та порівнявши з еталонними графіками основних законів, можна приблизно судити про ступінь подібності між ними. Для побудови гістограми значення випадкової величини розбивають на визначене число розрядів (інтервалів групування) і підраховують, скільки їх попадає в кожний розряд. Потім по осі абсцис відкладають розряди, а по осі ординат - відповідні їм частоти В переважній більшості випадків оптимальний крок інтервалу групування 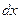 розраховується за формулою Стерджеса:
розраховується за формулою Стерджеса:
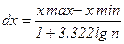 , (17.6)
, (17.6)
де 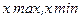 - максимальне і мінімальне значення ознаки;
- максимальне і мінімальне значення ознаки;
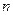 - об’єм вибірки.
- об’єм вибірки.
Отриманий результат необхідно округлити до цілого числа.
Якщо гістограма симетрична відносно вертикальної осі, яка проходить через її вершину, то можна говорити про можливість нормального закону розподілу. За виглядом побудованої гістограми можна судити про ступінь відхилення від нормального розподілу.
Перевіряючи гіпотезу про відповідність фактичного закону розподілу ознаки нормальному, ми можемо її прийняти, відкинути або прийти до висновку, що для прийняття рішення недостатньо даних. Гіпотеза може бути прийнята як правильна за рівнем значимості і позначають a. Величина a вибирається досить малою за принципом практичної неможливості малоймовірних подій. В основному приймають для a одне значення: 0.05. ДОВЕРИТ(альфа; середньоквадратичне відхилення; розмір вибірки).
Дослідження й оптимізація складних, неорганізованих даних можливі лише за допомогою статистичних, імовірнісних методів. Вихідною точкою для таких досліджень є аналог фізичної формули – математичної моделі системи, що носить назву моделі експерименту або рівняння регресії. Проте не завжди експериментальний матеріал дає можливість знайти зручний і точний вид моделі. У більш загальному випадку математична модель створюється на підставі статистичного методу – регресійного аналізу.
Рівняння регресії представляє математичну форму залежності фізичної величини, що досліджується, від факторів, що впливають на неї. Вибір того або іншого виду рівняння (що залежить від самого дослідника, який пропонує модель) визначає точність співпадіння моделі з реальними даними. Такий вибір виду рівняння визначається дослідником на підставі початкових даних про процес, вивчення факторів, що впливають на процес, від яких залежить величина, що вимірюється, а також зручності використання математичної моделі даного конкретного виду. Регресійний аналіз зводиться до визначення на підставі експериментальних даних коефіцієнтів моделі (коефіцієнтів регресії).
При статистичній оцінці ступеня подібності моделі експериментальним результатам найчастіше використовують критерій величини квадрата відхилення цих результатів від розрахункових значень, отриманих на підставі даної моделі. Процедура оцінки значень коефіцієнтів регресії і подібності, при якій квадрат відхилення є мінімальним, зветься методом найменших квадратів (МНК).
Розглянемо випадок, коли між двома величинами прослідковується лінійна залежність 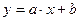 , що графічно зображується прямою лінією.
, що графічно зображується прямою лінією.
Параметри a та b підбираються за МНК.
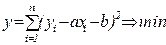 , (17.1)
, (17.1)
де n – кількість табличних значень 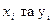 .
.
|
Дата добавления: 2014-01-07; Просмотров: 449; Нарушение авторских прав?; Мы поможем в написании вашей работы!