КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Хешування паролів
|
|
|
|
Алгоритм Хаффмана. Алгоритм заснований на тому факті, що деякі символи із стандартного 256-символьного набору в довільному тексті можуть зустрічатися частіше за середній період повтору, а інші, відповідно, – рідше. Отже, якщо для запису поширених символів використовувати короткі послідовності біт, завдовжки менше 8, а для запису символів, що зустрічаються рідко – довгі, то сумарний об'єм файлу зменшиться.
Загальні принципи архівації. Класифікація методів. Наступною великою темою є архівація даних. Як Вам відомо, переважна більшість сучасних форматів запису даних містять їх у вигляді, зручному для швидкого маніпулювання, для зручного прочитання користувачами. При цьому дані займають об'єм більший, ніж це дійсно потрібно для їх зберігання. Алгоритми, які усувають надмірність запису даних, називаються алгоритмами стискування даних, або алгоритмами архівації. В даний час існує величезна кількість програм для стискування даних, заснованих на декількох основних способах.
Навіщо ж потрібна архівація в криптографії? Річ у тому, що в сучасному криптоаналізі, тобто науці про протистояння криптографії, з очевидністю доведено, що вірогідність злому криптосхеми за наявності кореляції між блоками вхідної інформації значно вище, ніж за відсутності такої. А алгоритми стискування даних за визначенням і мають своїм основним завданням усунення надмірності, тобто кореляцій між даними у вхідному тексті.
Всі алгоритми стискування даних якісно поділяються на:
1 алгоритми стискування без втрат, при використанні яких дані відновлюються без щонайменших змін;
2 алгоритми стискування з втратами, які видаляють з потоку даних інформацію, що трохи впливає на суть даних, або взагалі не сприймається людиною (такі алгоритми зараз розроблені лише для аудіо- та відео-зображень).
|
|
|
У криптосистемах, природно, використовується лише перша група алгоритмів.
Існує два основні методи архівації без втрат:
- алгоритм Хаффмана (англ. Huffman), орієнтований на стискування послідовностей байт, не зв'язаних між собою;
- алгоритм Лемпеля-Зіва (англ. Lempel, Ziv), орієнтований на стискування будь-яких видів текстів, тобто використання неодноразового повторення "слів" – послідовностей байт.
Практично всі популярні програми архівації без втрат (ARJ, RAR, ZIP) використовують об'єднання цих двох методів – алгоритм LZH.
Хаффман запропонував дуже простий алгоритм визначення того, який символ необхідно кодувати яким кодом для отримання файлу з довжиною, дуже близькою до його ентропії (тобто інформаційній насиченості). Нехай у нас є список всіх символів, що зустрічаються у вихідному тексті, причому відома кількість появ кожного символу в ньому. Випишемо їх вертикально в ряд у вигляді вічок майбутнього графа з правого краю аркуша (рис. 4.5а). Виберемо два символи з найменшою кількістю повторень в тексті (якщо три або більше число символів мають однакові значення, вибираємо будь-які два з них). Проведемо від них лінії вліво до нової вершини графа і запишемо в неї значення, рівне сумі частот повторення кожного з об'єднуваних символів (рис.4.5б). Далі не братимемо до уваги при пошуку найменших частот повторення два об'єднані вузли (для цього зітремо числа в цих двох вершинах), але розглядатимемо нову вершину як повноцінне вічко з частотою появи, рівній сумі частот появи двох вершин, що з'єдналися. Повторюватимемо операцію об'єднання вершин до тих пір, поки не прийдемо до однієї вершини з числом (рис.4.5в і 4.5г), для перевірки. вочевидь, що в ній буде записана довжина кодованого файлу. Тепер розставимо на двох ребрах графа, що виходять з кожної вершини, біти 0 і 1 довільно – наприклад, на кожному верхньому ребрі 0, а на кожному нижньому – 1. Тепер для визначення коду кожної конкретної букви необхідно просто пройти від вершини дерева до неї, виписуючи нулі і одиниці по маршруту слідування. Для рис. 4.5 символ "А" отримує код "100", символ "Б" – код "0", символ "К" – код "101", а символ "О" – код "11".
|
|
|
В теорії кодування інформації показується, що код Хаффмана є префіксним, тобто код жодного символу не є початком коду якого-небудь іншого символу. Перевірте це на нашому прикладі. А з цього виходить, що код Хаффмана однозначно відновлюваний одержувачем, навіть якщо не повідомляється довжини коду кожного переданого символу. Одержувачеві пересилають лише дерево Хаффмана в компактному вигляді, а потім вхідна послідовність кодів символів декодується ним самостійно без якої-небудь додаткової інформації.
Наприклад, при отриманні послідовності "01001101000" ним спочатку відділяється перший символ "Б": "0-1001101000", потім знову починаючи з вершини дерева – "А" "0-100-1101000", потім аналогічно декодується весь запис "0-100-11-0-100-0" "БАОБАБ".
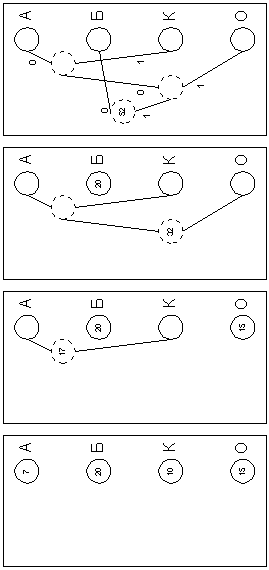
Рисунок 4.5 - Алгоритм Хаффмана
4.4.3 Алгоритм Лемпеля-Зіва. Класичний алгоритм Лемпеля-Зіва – LZ77, названий так за роком своєї публікації, гранично простий. Він формулюється таким чином: "якщо у вихідному потоці, що пройшов раніше, вже зустрічалася подібна послідовність байт, причому запис про її довжину і зсув від поточної позиції коротше чим сама ця послідовність, то у вихідний файл записується посилання (зсув, довжина), а не сама послідовність". Так фраза "КОЛОКОЛ_ ОКОЛО_КОЛОКОЛЬНИ" закодується як "КОЛО(-4,3)_(-5,4)О_(-14,7) ЬНИ".
Поширений метод стискування RLE (англ. Run Length Encoding), який полягає в записі замість послідовності однакових символів одного символу і їх кількості, є підкласом даного алгоритму. Розглянемо, наприклад, послідовність "ААААААА". За допомогою алгоритму RLE вона буде закодована як "(А,7)", в той же час її можна досить добре стискувати і за допомогою алгоритму LZ77: "А(-1,6)". Дійсно, міра стискування саме такої послідовності ним гірше (приблизно на 30-40%), але сам по собі алгоритм LZ77 більш універсальний, і може набагато краще обробляти послідовності, які взагалі нестискуються методом RLE.
|
|
|
Від методів, що підвищують криптостійкість системи в цілому, перейдемо до блоку хешування паролів – методу, що дозволяє користувачам запам'ятовувати не 128 байт, тобто 256 шістнадцяткових цифр ключа, а деякий осмислений вираз, слово або послідовність символів, що називається паролем. Дійсно, при розробці будь-якого криптоалгоритму слід враховувати, що в половині випадків кінцевим користувачем системи є людина, а не автоматична система. Це ставить питання про те, чи зручно, і взагалі чи реально людині запам'ятати 128-бітовий ключ (32 шістнадцяткових цифри). Насправді межа запам’ятовуваності становить 8-12 подібних символів, а, отже, якщо ми заставлятимемо користувача оперувати саме ключем, тим самим ми практично змусимо його до запису ключа на якому-небудь листку паперу або електронному носієві, наприклад, в текстовому файлі. Це, природно, різко знижує захищеність системи.
Для вирішення цієї проблеми були розроблені методи, що перетворюють вимовний, осмислений рядок довільної довжини, – пароль, у вказаний ключ заздалегідь заданої довжини. У переважній більшості випадків для цієї операції використовуються так звані хеш-функції (від англ. hashing – дрібна нарізка і перемішування). Хеш-функцією називається таке математичне або алгоритмічне перетворення заданого блоку даних, яке володіє такими властивостями:
1 хеш-функція має нескінченну область визначення;
2 хеш-функція має кінцеву область значень
3 вона необоротна
4 зміна вхідного потоку інформації на один біт змінює близько половини всіх біт вихідного потоку, тобто результату хеш-функції.
Ці властивості дозволяють подавати на вхід хеш-функції паролі, тобто текстові рядки довільної довжини на будь-якій національній мові і, обмеживши область значень функції діапазоном 0..2N-1, де N – довжина ключа в бітах, отримувати на виході досить рівномірний розподілені блоки інформації – ключі.
|
|
|
Неважко відмітити, що вимоги 3 і 4 до хеш-функції, виконують блокові шифри. Це вказує на один з можливих шляхів реалізації стійких хеш-функцій – проведення блокових криптоперетворень над матеріалом рядка-пароля. Цей метод і використовується в різних варіаціях практично у всіх сучасних криптосистемах. Матеріал рядка-пароля багато разів послідовно використовується як ключ для шифрування деякого заздалегідь відомого блоку даних – на виході виходить зашифрований блок інформації, що однозначно залежний лише від пароля і при цьому має досить хороші статистичні характеристики. Такий блок або декілька таких блоків і використовуються як ключ для подальших криптоперетворень.
Характер використання блокового шифру для хешування визначається відношенням розміру блоку використовуваного криптоалгоритму і розрядності необхідного хеш-результату.
Якщо вказані вище величини збігаються, то використовується схема одноланцюгового блокового шифрування. Первинне значення хеш-результату H0 встановлюється рівним 0, весь рядок-пароль розбивається на блоки байт, рівні довжині ключа, що використовується для хешування блокового шифру, потім здійснюється перетворення за рекурентною формулою:
Hj=Hj-1 XOR EnCrypt(Hj-1,PSWj),
де EnCrypt(X,Key) – використовуваний блоковий шифр (рис.4.6).
Значення Hk використовується як шуканий результат.
У тому випадку, коли довжина ключа рівно в два рази перевершує довжину блоку, а подібна залежність досить часто зустрічається в блокових шифрах, використовується схема, що нагадує мережу Фейштеля. Характерним недоліком і приведеної вище формули, і хеш-функції, заснованої на мережі Фейштеля, є велика ресурсоємність відносно пароля. Для проведення лише одного перетворення, наприклад, блоковим шифром з ключем завдовжки 128 біт використовується 16 байт рядка-пароля, а сама довжина пароля рідко перевищує 32 символи. Отже, при обчисленні хеш-функції над паролем буде здійснено максимум 2 "повноцінних" криптоперення.
Вирішення цієї проблеми можна досягти двома шляхами:
1 заздалегідь "розмножити" рядок-пароль, наприклад, записавши його багато разів послідовно до досягнення довжини, скажімо, в 256 символів;
2 модифікувати схему використання криптоалгоритму так, щоб матеріал рядка-пароля "повільніше" витрачався при обчисленні ключа.
Іншим шляхом пішли дослідники Девіс і Маєр, що запропонували алгоритм також на основі блокового шифру, але який використовує матеріал рядка-пароля багато разів і невеликими порціями.
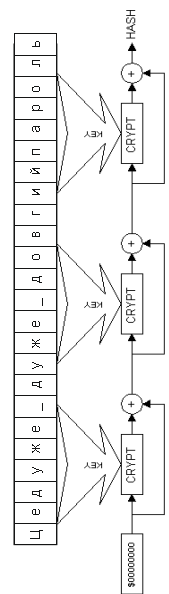
Рисунок 4.6 - блоковий шифр
Цей алгоритм має елементи обох приведених вище схем, але криптостійкість цього алгоритму підтверджена багаточисельними реалізаціями в різних криптосистемах. Алгоритм отримав назву "Tandem DM" (рис.4.7):
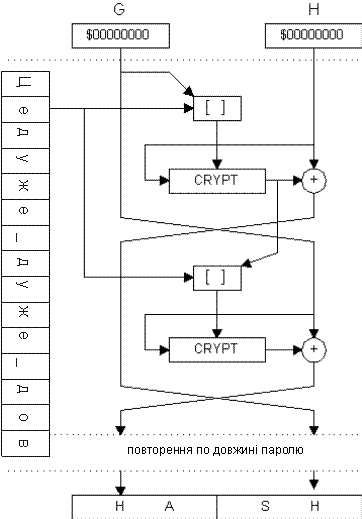
Рисунок 4.7 - Алгоритм "Tandem DM"
Квадратними дужками (X16=[A8,B8]) тут позначено просте об'єднання (склеювання) двох блоків інформації рівної величини в один – подвоєної розрядності. А як процедура EnCrypt(X,Key) знову може бути вибраний будь-який стійкий блоковий шифр. Як видно з формул, даний алгоритм орієнтований на те, що довжина ключа двократно перевищує розмір блоку криптоалгоритму. А характерною особливістю схеми є той факт, що рядок пароля прочитується блоками по половині довжини ключа, і кожен блок використовується в створенні хеш-результату двічі. Таким чином, при довжині пароля в 20 символів і необхідності створення 128 бітового ключа внутрішній цикл хеш-функції повториться 3 рази.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1366; Нарушение авторских прав?; Мы поможем в написании вашей работы!