КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коды без памяти. Коды Хаффмена
|
|
|
|
Простейшими кодами, на основе которых может выполняться сжатие данных, являются коды без памяти. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
Префиксным множеством двоичных последовательностей S называется конечное множество двоичных последовательностей, таких, что ни одна последовательность в этом множестве не является префиксом, или началом, никакой другой последовательности в S.
К примеру, множество двоичных слов S1 = {00, 01, 100, 110, 1010, 1011 } является префиксным множеством двоичных последовательностей, поскольку, если проверить любую из 30 возможных совместных комбинаций (wi wj) из S1, то видно, что wi никогда не явится префиксом (или началом) wj. С другой стороны, множество S2 = { 00, 001, 1110 } не является префиксным множеством двоичных последовательностей, так как последовательность 00 является префиксом (началом) другой последовательности из этого множества - 001.
Таким образом, если необходимо закодировать некоторый вектор данных X = (x1, x2,… xn) с алфавитом данных Aразмера k, то кодирование кодом без памяти осуществляется следующим образом:
- составляют полный список символов a1, a2, aj...,ak алфавита A, в котором aj - j -й по частоте появления в X символ, то есть первым в списке будет стоять наиболее часто встречающийся в алфавите символ, вторым – реже встречающийся и т.д.;
- каждому символу aj назначают кодовое слово wj из префиксного множества двоичных последовательностей S;
- выход кодера получают объединением в одну последовательность всех полученных двоичных слов.
Формирование префиксных множеств и работа с ними – это отдельная серьезная тема из теории множеств, выходящая за рамки нашего курса, но несколько необходимых замечаний все-таки придется сделать.
|
|
|
Если S = { w1, w2,..., wk } - префиксное множество, то можно определить некоторый вектор v(S) = (L1, L2,..., Lk), состоящий из чисел, являющихся длинами соответствующих префиксных последовательностей (Li - длина wi ).
Вектор (L1, L2,..., Lk), состоящий из неуменьшающихся положительных целых чисел, называется вектором Крафта. Для него выполняется неравенство
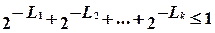 . (2.5)
. (2.5)
Это неравенство называется неравенством Крафта. Для него справедливо следующее утверждение: если S - какое-либо префиксное множество, то v(S) - вектор Крафта.
Иными словами, длины двоичных последовательностей в префиксном множестве удовлетворяют неравенству Крафта.
Если неравенство (2.5) переходит в строгое равенство, то такой код называется компактным и обладает наименьшей среди кодов с данным алфавитом длиной, то есть является оптимальным.
Ниже приведены примеры простейших префиксных множеств и соответствующие им векторы Крафта:
S1 = {0, 10, 11} и v(S1) = (1, 2, 2);
S2 = {0, 10, 110, 111} и v(S2) = (1, 2, 3, 3);
S3 = {0, 10, 110, 1110, 1111} и v(S3) = (1, 2, 3, 4, 4);
S4 = {0, 10, 1100, 1101, 1110, 1111} и v(S4) = (1, 2, 4, 4, 4, 4);
S5 = {0, 10, 1100, 1101, 1110, 11110, 11111} и v(S5) = (1, 2, 4, 4, 4, 5, 5);
S6 = {0, 10, 1100, 1101, 1110, 11110, 111110, 111111}
и v(S6) = (1,2,4,4,4,5,6,6).
Допустим мы хотим разработать код без памяти для сжатия вектора данных X = (x1, x2,… xn) с алфавитом Aразмером в k символов. Введем в рассмотрение так называемый вектор частот F = (F1, F2,..., Fk), где Fi - количество появлений i -го наиболее часто встречающегося символа из A в X. Закодируем X кодом без памяти, для которого вектор Крафта L = (L1, L2,..., Lk).
Тогда длина двоичной кодовой последовательности B(X) на выходе кодера составит
L*F = L1*F1 + L2*F2 +... + Lk*Fk . (2.6)
Лучшим кодом без памяти был бы код, для которого длина B(X) - минимальна. Для разработки такого кода нам нужно найти вектор Крафта L, для которого произведение L*F было бы минимальным.
|
|
|
Простой перебор возможных вариантов - вообще-то, не самый лучший способ найти такой вектор Крафта, особенно для большого k.
Алгоритм Хаффмена, названный в честь его изобретателя - Дэвида Хаффмена, - дает нам эффективный способ поиска оптимального вектора Крафта L для F, то есть такого L, для которого точечное произведение L*F – минимально. Код, полученный с использованием оптимального L для F, называют кодом Хаффмена.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 263; Нарушение авторских прав?; Мы поможем в написании вашей работы!