КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Синдромное декодирование линейных блочных кодов
|
|
|
|
Покажем, как можно использовать синдром принятого вектора не только для обнаружения, но и для исправления ошибок.
Пусть U = (U0 , U1 , …, Un-1 ), e = (е0 , е1, …, еn-1) и r = (r0 , r1, r2 , …, rn- 1) являются передаваемым кодовым словом, вектором-ошибкой и принятым вектором соответственно. Тогда
r = U + e (3.25)
и синдром
S = r×HT = (U + e)× HT = U× HT + e× HT = 0 + e× HT = e× HT, (3.26)
поскольку для любого кодового слова U × HT = 0.
Таким образом, синдром принятой последовательности r зависит только от ошибки, имеющей место в этой последовательности, и совершенно не зависит от переданного кодового слова. Задача декодера, используя эту зависимость, определить элементы (координаты) вектора ошибок. Найдя вектор ошибки можно восстановить кодовое слово как
U* = r + e. (3.27)
На примере одиночных ошибок при кодировании с использованием линейного блочного (7,4)-кода покажем, как вектор ошибки связан с синдромом, и как, имея синдром, локализовать и устранить ошибки, возникшие при передаче.
Найдем значения синдрома для всех возможных одиночных ошибок в последовательности из семи символов:
e_ = (0000000),
| T | ||
| e_ × H T = (0000000) × | = (000) ; | |
e0 = (1000000),
| T | ||
| e0× H T = (1000000) × | = (110); | |
e1 = (0100000),
| T | ||
| e1× H T = (0100000) × | = (011); | |
e2 = (0010000),
| T | ||
| e2× H T = (0010000) × | = (111); | |
e3 = (0001000),
| T | ||
| e3× H T = (0001000) × | = (101) ; | |
e4 = (0000100),
| T | ||
| e4× H T = (0000100) × | = (100); | |
e5 = (0000010),
| T | ||
| e5× H T = (0000010) × | = (010); | |
e6 = (0000001),
| T | ||
| e6× H T = (0000001) × | = (001). | |
Все возможные для (7,4)-кода одиночные ошибки и соответствующие им векторы синдрома приведены в табл. 3.3.
|
|
|
Таблица 3.3
| Вектор ошибки | Синдром ошибки | Десятичный код синдрома |
Из этой таблицы видно, что существует однозначное соответствие между сочетанием ошибок (при одиночной ошибке) и его синдромом, то есть, зная синдром, можно совершенно однозначно определить позицию кода, в которой произошла ошибка.
Например, если синдром, вычисленный по принятому вектору, равен (111), это значит, что произошла одиночная ошибка в третьем символе, если S = (001) – то в последнем, и т.д.
Если место ошибки определено, то устранить ее уже не представляет никакого труда.
Полная декодирующая схема для (7,4)-кода Хемминга, использующая синдром вектора r не только для обнаружения, но и для исправления ошибок, приведена на рис. 3.6.
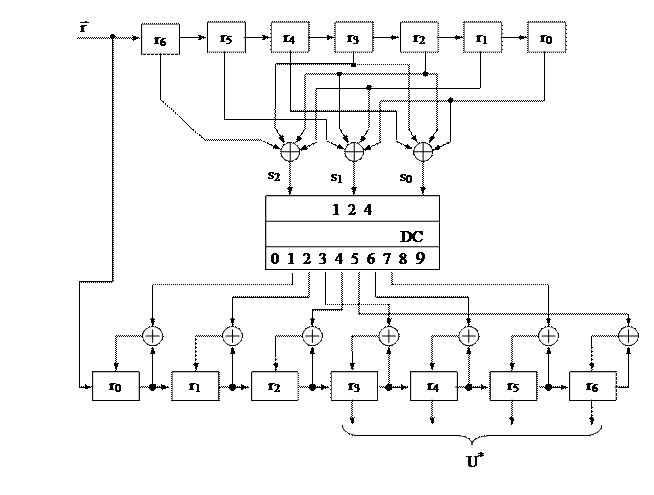
Рис. 3.6
А теперь посмотрим, что произойдет, если в принятой последовательности будет не одна, а, например, две ошибки. Пусть ошибки возникли во второй и шестой позициях e = (0100010). Соответствующий синдром определится как
S = (0100010) 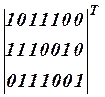 = (001).
= (001).
Однако синдром S = (001) соответствует также и одиночной ошибке в седьмой позиции (e6 ). Следовательно, наш декодер не только не исправит ошибок в позициях, в которых они произошли, но и внесет ошибку в ту позицию, где ее не было. Таким образом, видно, что (7,4)-код не обеспечивает исправления двойных ошибок, а также ошибок большей кратности.
Это, однако, обусловлено не тем, каким образом производится декодирование, а свойствами самого кода. Несколько позднее будет показано, от чего зависит исправляющая способность кода, то есть сколько ошибок он может исправить.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 3177; Нарушение авторских прав?; Мы поможем в написании вашей работы!