КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Просмотр дерева двоичного поиска
|
|
|
|
BinTreeSearch(Arrаy, v):
1. if a=l(v) then return "1" else
2. if а<l(v) then
3. if v имеет левого сына w then return BinTreeSearch(Arrаy, w)
4. else return "0" else
5. if v имеет правого сына w then return BinTreeSearch(Arrаy, w)
6. else return "0"
Деревья двоичного поиска также удобны для выполнения операций MIN и УДАЛИТЬ. Для нахождения наименьшего элемента в дереве двоичного поиска Т просматривается путь v 0, v 1 ,¼, v p, где v 0 – корень дерева T, v i – левый сын узла v i-1, l £ i £ p, и у узла v p нет левого сына. Метка в узле v p является наименьшим элементом в T. В некоторых задачах может оказаться удобным иметь указатель на v p, чтобы обеспечить доступ к наименьшему элементу за постоянное время.
Реализовать операцию Delete (a, S) немного труднее. Допустим, что элемент а, подлежащий удалению, расположен в узле v. Возможны три случая:
1) v — лист; в этом случае v удаляется из дерева;
2) у v в точности один сын; в этом случае делаем отца узла v отцом его сына, тем самым удаляя v из дерева (если v – корень, то его сына делаем новым корнем);
3) у v два сына; в этом случае находим в левом поддереве узла v наибольший элемент b, рекурсивно удаляем из этого поддерева узел, содержащий b, и метим узел v элементом b. (Заметим, что среди элементов", меньших а, b будет наибольшим элементом всего дерева.)
Пример 3.3. На рис. 15 иллюстрируется пример удаления узла из бинарного дерева поиска. Предположим, что надо удалить узел 25 из данного дерева. Он расположен в корне, у которого два сына. Наибольшее число, меньшее 25, расположенное в левом поддереве корня,– это 15. Удаляем из дерева узел с меткой 15 и заменяем 25 на 15 в корне. Полученное дерево показано на рис. б. ÿ
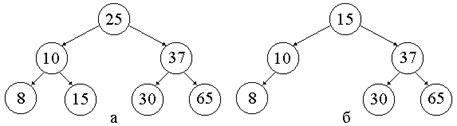
Рис. 15: Дерево двоичного поиска до (а) и после (б) выполнения операции УДАЛИТЬ (узел 25).
|
|
|
В качестве упражнения предлагаем написать программу на C++ для операции УДАЛИТЬ. Заметим, что одно выполнение любой из операций ПРИНАДЛЕЖАТЬ, ВСТАВИТЬ, УДАЛИТЬ и MIN можно осуществить за время О (п),
Подсчитаем временнýю сложность последовательности из п операций ВСТАВИТЬ, когда рассматриваемое множество представлено деревом двоичного поиска. Время, требуемое, чтобы в дерево двоичного поиска вставить элемент a, ограничено по порядку числом сравнений, производимых между а и элементами, уже находящимися в дереве. Поэтому время можно измерять числом производимых сравнений.
В худшем случае добавление к дереву п элементов может потребовать квадратичного времени. Например, допустим, что последовательность элементов, которые надлежит добавить, оказалась упорядоченной (в порядке возрастания). Тогда дерево поиска будет просто цепью правых сыновей. Но если вставляется п случайных элементов, то, как показывает следующая теорема, вставка потребует время 0 (п log п).
Теорема 11. Среднее число сравнений, необходимых для вставка п случайных элементов в дерево двоичного поиска, пустое вначале, равно O(n log n) для n³ 1.
Доказательство. Пусть Т (п) – число сравнений, производимых между элементами последовательности a 1, a 2,¼, a n при построении дерева двоичного поиска, T (0)= 0. Пусть b 1, b 2,¼, b n – та же последовательность в порядке возрастания.
Если a 1, a 2,¼, a n – случайная последовательность элементов, то a 1 с равной вероятностью совпадает с b j для любого j, 1 £ j £ n. Элемент a i становится корнем дерева двоичного поиска, и в окончательном дереве j–1 элементов b 1, b 2,¼, b j-1 будут находиться в левом поддереве корня и п–j элементов b j+1, b j+2,¼, b n – в правом поддереве.
Подсчитаем среднее число сравнений, необходимых для вставки элементов b 1, b 2,¼, b j-1 в дерево. Каждый из этих элементов когда-нибудь сравнивается с корнем, и это дает j–1 сравнений с корнем. Затем по индукции получаем, что еще потребуется Т (j–1) сравнений, чтобы вставить b 1, b 2,¼, b j-1 в левое поддерево. Итак, необходимо j–1 + T (j–1) сравнений, чтобы вставить b 1, b 2,¼, b j-1 в дерево двоичного поиска. Аналогично п–j+Т (п–j) сравнений потребуется, чтобы вставить в дерево элементы b j+1, b j+2,¼, b n.
|
|
|
Поскольку j с равной вероятностью принимает любое значение от 1 до n, то
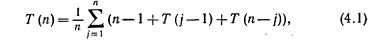
или, с учетом простых алгебраических преобразований,
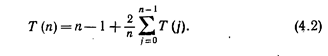
Способом, описанным в разделе 2.4, можно показать, что
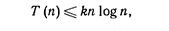
где k = ln 4 = 1,39. Таким образом, в среднем на вставку п элементов в дерево двоичного поиска тратится 0(п log п) сравнений. ÿ
Итак, методами этого раздела можно выполнить случайную последовательность из п операций ВСТАВИТЬ, УДАЛИТЬ, ПРИНАДЛЕЖАТЬ и MIN за среднее время О (п log п). Выполнение в худшем случае занимает квадратичное время. Однако даже это худшее время можно улучшить до О (п log п) с помощью одной из схем сбалансированных деревьев, которые обсуждаются далее.
3.5. Оптимальные деревья двоичного поиска
В разд. 4.3 по данному множеству S={ a 1, a 2,¼, a n}, являющемуся подмножеством некоторого большого универсального множества U, строилась структура данных, позволяющая эффективно выполнить последовательность s, составленную только из операций ПРИНАДЛЕЖАТЬ. Рассмотрим снова эту задачу, но теперь предположим, что кроме множества S задается для каждого а Î U вероятность появления в s операции Member (a, S). Теперь желательно построить дерево двоичного поиска для S так, чтобы последовательность s операций ПРИНАДЛЕЖАТЬ можно было выполнить в префиксном режиме с наименьшим средним числом сравнений.
Пусть a 1, a 2,¼, a n –элементы множества S в порядке возрастания и p i – вероятность появления в s операции Member (a, S). Пусть q 0 – вероятность появления в s операции Member (a, S) для некоторого а < a i, а q i – вероятность появления в s операции Member (a, S) для некоторого а, а i < a < а i+1. Наконец, пусть q n – вероятность появленияв s операции Member (a, S) для некоторого а>а n. Для определения стоимости дерева двоичного поиска удобно добавить к нему n+1 фиктивных листьев, чтобы отразить элементы из U–S. Эти листья будут обозначаться числами 0, 1, ¼, п.
|
|
|
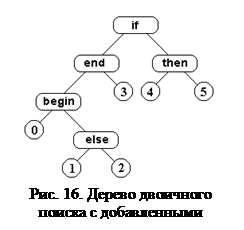 На рис. 16 показано дерево двоичного поиска, изображенное на рис. 13, с добавленными фиктивными листьями. Например, лист с меткой 3 представляет те элементы а, для которых end < a < if.
На рис. 16 показано дерево двоичного поиска, изображенное на рис. 13, с добавленными фиктивными листьями. Например, лист с меткой 3 представляет те элементы а, для которых end < a < if.
Требуется определить стоимость дерева двоичного поиска. Если элемент а равен метке l (v) некоторого узла v, то число узлов, посещенных во время выполнения операции Member (a, S), на единицу больше глубины узла v. Если a Ï S и a i< a < а i+1, то число узлов, посещенных при выполнении операции Member (a, S), равно глубине фиктивного листа i. Поэтому стоимость дерева двоичного поиска можно определить как
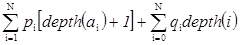 ,
,
где depth (¼) – глубина соответствующего узла дерева.
Теперь, если есть дерево двоичного поиска Т, обладающее наименьшей стоимостью, можно выполнить последовательность операций ПРИНАДЛЕЖАТЬ с наименьшим средним числом посещений узлов, просто применив для выполнения каждой операции ПРИНАДЛЕЖАТЬ алгоритм 14 на T.
Если даны числа p i и q i, то как найти дерево наименьшей стоимости? Подход "разделяй и властвуй" предлагает определить элемент a i, который надо поставить в корень. Это разбило бы данную задачу на две подзадачи: построение левого и правого поддеревьев. Однако, похоже, нет легкого пути определения корня без решения всей задачи. Поэтому придется решать 2п подзадач: по две для каждого возможного корня. Это естественно приводит к решению с помощью динамического программирования.
Для 0 £ i < j £ n обозначим через Т ij дерево наименьшей стоимости для подмножества { a i+1, a i+2, ¼, a j}. Пусть c ij – стоимость дерева Т ij, а r ij – его корень. Вес w ij дерева Т ij определяется как q i + (p i+1 + q i+1)+ ¼ +(p j + q j).
Дерево T ij состоит из корня a k, левого поддерева Т i,k–1 (т. е. дерева наименьшей стоимости для { a i+1, a i+2, ¼, a k–1}) и правого Т kj (т. е. дерева наименьшей стоимости для { a k+1, a k+2, ¼, a j}) (рис. 17). Если i=k–1, то нет левого поддерева, а при k=j нет правого поддерева. Для удобства Т ii будет трактоваться как пустое дерево. Вес w ii дерева Т ii равен q i, а его стоимость c ii равна 0.
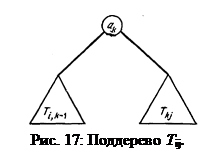 В Т ij, i<j, глубина каждого узла в левом и правом поддеревьях на единицу больше глубины того же узла в Т i,k–1 или Т kj. Поэтому стоимость c ij дерева Т ij можно выразить так:
В Т ij, i<j, глубина каждого узла в левом и правом поддеревьях на единицу больше глубины того же узла в Т i,k–1 или Т kj. Поэтому стоимость c ij дерева Т ij можно выразить так:
|
|
|
c ij= w i,k–1+ p k+ w kj+ c i,k–1+ c kj = w ij + c i,k–1+ c kj.
Следует брать здесь то значение k, которое минимизирует сумму c i,k–1+ c kj. Поэтому для нахождения оптимального дерева Т ij вычисляют для каждого k, i < k £ j, стоимость дерева с корнем a k, левым поддеревом Т i,k–1, и правым поддеревом Т kj, а затем выбирают дерево наименьшей стоимости. Приведем соответствующий алгоритм.
Алгоритм 15. Построение оптимального дерева двоичного поиска
Вход. Множество S вида { a 1, a 2, ¼, a n}, где a 1 <a 2 <¼<.a n Известны также вероятности q 0, q 1 ,¼, q n и p 1 ,¼, p n, где q i, 1 £ i<n, – вероятность выполнения операции Member (a, S) для a i <a<a i+1, q 0 – вероятность выполнения операции Member (a, S) для а<а 1, q n – вероятность выполнения операции Member (a, S) для a > a n, a p i, 1 £ i £ n, – вероятность выполнения операции Member (a, S).
Выход. Дерево двоичного поиска для S, обладающее наименьшей стоимостью.
Метод.
1. Для 0 £ i < j £ n вычисляются r ij и c ij в порядке возрастания разности j – i с помощью алгоритма динамического программирования.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 382; Нарушение авторских прав?; Мы поможем в написании вашей работы!