КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Проектирование нечетких систем
|
|
|
|
Нечеткие системы (независимо от того, являются ли они нечеткими моделями или нечеткими контроллерами) (рис. 6) включают два главных компонента:
· Базу знаний (БЗ), в которой хранятся доступные или приобретенные знания о задаче, требующей решения, в форме нечетких правил;
· Механизм инференции, использующий методы нечетких рассуждений, базирующиеся на базе правил и входных сигналах, для получения выходного сигнала системы.
Оба этих компонента должны быть спроектированы так, чтобы построить систему для конкретного приложения:
· БЗ формируют из знаний экспертов или путем обучения с помощью машинных методов;
· Механизм инференции строят путем выбора нечетких операторов для каждого компонента (конъюнкция, импликация, дефаззификация и т.п.).
В ряде случаев операторы также параметризуются и могут быть настроены автоматическими методами.
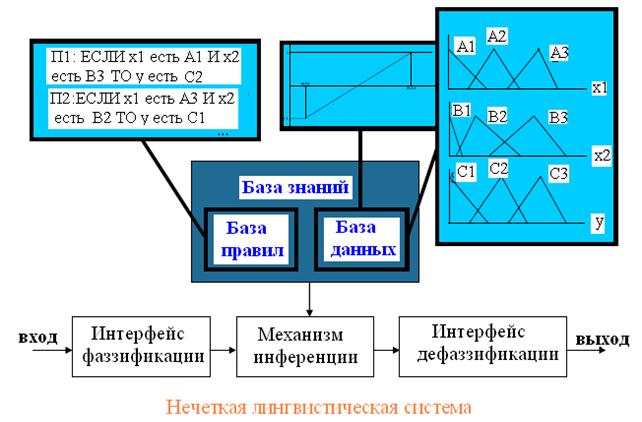
Рис. 7
Проектирование БЗ затрагивает две подзадачи:
1. Определение базы данных (БД):
· Универсум для переменных;
· Масштабирующие коэффициенты или функции;
· Гранулированность (число лингвистических терм) для каждой переменной;
· Функции принадлежности, описывающие термы.
2. Составление базы правил (БП): формулировка базовых правил.
Как уже отмечено, существуют два различных метода для проектирования базы знаний (БЗ): информация от экспертов и с помощью машинных методов обучения на основе численной информации, полученной с помощью нечеткого моделирования или путем симуляции проектируемой системы управления.
Классификация генетических нечетких систем
С точки зрения оптимизации, чтобы найти соответствующую нечеткую систему, надо ее представить как эквивалентную параметрическую структуру и затем определить значения параметров, обеспечивающих оптимум для конкретной функции приспособленности. Поэтому первый шаг в проектировании ГНЛС решить вопрос о том, какая часть нечеткой системы подлежит оптимизации путем кодирования ее параметров в хромосомы. В этом разделе мы представим классификацию ГНЛС, соответствующую различным частям нечеткой системы, кодируемым с помощью генетической модели.
|
|
|
Обычно методы проектирования ГНЛС разделяют на два процесса, настройка (т.е. адаптация) и обучение. При этом будем исходить из факта, существует или нет исходная БЗ, включая БД и БП. Тогда в рамках ГНЛС мы вводим следующее деление.
· Генетическая настройка. Если существует БЗ, мы применяем процесс генетической настройки для улучшения свойств нечеткой системы, но не изменяем БП. Т.е. мы настраиваем параметры НЛС с целью улучшения ее свойств, сохраняя неизменной БП.
· Генетическое обучение. Вторая возможность обучать компоненты БП, к которым можно отнести адаптацию механизма инференции. Т.е. мы затрагиваем обучение компонентов БП, наряду с другими компонентами НЛС.
1) Генетическая настройка базы данных. Осуществляется путем определения предварительно вида и параметров масштабирующих функций входа и выхода, а также функций принадлежности, и затем настройки этих параметров и тем самым изменения формы масштабирующих функций и функций принадлежности с помощью ГА (рис. 8).
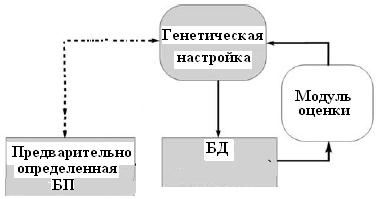
Рис. 8
2) Генетическое обучение базы правил. Генетическое обучение БП предполагает предопределенное множество функций принадлежности в БД, к которым правила обращается посредством лингвистических терм.

Рис. 9
Когда рассматривается задача обучения базы правил, открывается широкий диапазон возможностей. Имеется три главных подхода: питтсбургский, мичиганский и итеративный методы обучения. Питтсбургский и мичиганский подходы являются наиболее распространенными методами для обучения правил, разработанные в области ГА. Первый из них характеризуется представлением всего набора (совокупности) правил как генетического кода (хромосомы), «хромосома=набор правил», сохраняя неизменной популяцию кандидатов на роль правил и, используя селекцию, и генетические операторы для создания новых поколений наборов правил. Мичиганский подход рассматривает другую модель, в которой члены популяции являются отдельными правилами, «хромосома=правило» и набор правил представляется всей популяцией. В третьем случае, итеративном методе с помощью хромосом кодируют отдельные правила, и новое правило настраивается и добавляется в набор правил, итеративным способом.
|
|
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 775; Нарушение авторских прав?; Мы поможем в написании вашей работы!