КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Статистические характеристики случайной величины
|
|
|
|
Одномерная статистическая модель
В основе одномерной статистической модели лежат три гипотезы: а) измеренные значения х 1, х 2,..., хn носят случайный характер; б) они не зависят друг от друга; в) значения образуют однородную совокупность. Измеренные значения принято называть реализациями случайной величины х.
Гипотеза о случайном характере свойств обусловлена тем, что природные геологические системы и объекты являются весьма сложными, на каждое измеренное значение влияет множество разнонаправленных факторов. Кроме того, каждое измерение сопровождается случайной погрешностью. Данная гипотеза позволяет применять для математической обработки значений х 1, х 2, …, хn аппарат (теоремы, формулы, уравнения, законы) теории вероятностей.
Вторая гипотеза о независимости измеренных значений менее очевидна. Она предполагает, что на результат каждого отдельного измерения не влияют результаты предыдущих или соседних измерений. Из этой гипотезы вытекает важное следствие, что для математической обработки не существенно пространственное размещение пунктов наблюдений, т.е. результаты измерений можно располагать в любом порядке, на выводы это не влияет. Эта гипотеза не всегда соответствует действительности: соседние измерения нередко зависят друг от друга, что можно проверить с помощью специального математического аппарата.
Статистическая обработка результатов измерений имеет смысл лишь только для однородных совокупностей, что лежит в основе третьей гипотезы. Если совокупность неоднородная, то ее необходимо разделить на однородные совокупности и каждую из них исследовать отдельно.
В основе большинства вычислений лежит расчет статистических характеристик случайной величины. К наиболее распространенным статистическим характеристикам одномерной случайной величины относятся размах, медиана, мода, среднее значение, дисперсия, среднеквадратичное отклонение, коэффициент вариации, асимметрия и эксцесс.
|
|
|
Пусть имеется n измерений свойства х. Необходимо найти статистические характеристики этого множества измерений.
Размах – это разность между максимальным х max и минимальным х min значениями свойства: p = хmax – х min.
Медиана – средний член упорядоченного ряда значений. Для нахождения медианы нужно расположить все значения в порядке возрастания или убывания и найти средний по порядку член ряда. В случае n – четного числа в середине ряда окажутся два значения, тогда медиана будет равна их полусумме.
Мода – значение во множестве наблюдений, которое встречается наиболее часто.
Среднее значение – это среднеарифметическое из всех измеренных значений:
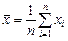 . (2.1)
. (2.1)
Существуют другие виды средних (среднее взвешенное, среднее геометрическое, среднее гармоническое и др.), которые вычисляются в особых случаях и здесь не рассматриваются.
Медиана, мода и среднее значение являются характеристиками положения – около них группируются измеренные значения случайной величины.
Дисперсия – это число, равное среднему квадрату отклонений значений случайной величины от ее среднего значения:
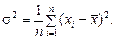 (2.2)
(2.2)
Среднеквадратичное отклонение – это число, равное квадратному корню из дисперсии:
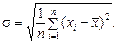 (2.3)
(2.3)
Среднеквадратичное отклонение имеет размерность, совпадающую с размерностью случайной величины и среднего значения. Например, если значения случайной величины измерены в метрах, то и среднеквадратичное отклонение также будет выражаться в метрах.
Коэффициент вариации – это отношение среднеквадратичного отклонения к среднему значению:
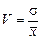 . (2.4)
. (2.4)
|
|
|
Коэффициент вариации выражается в долях единицы или (после умножения на 100) в процентах. Вычисление коэффициента вариации имеет смысл для положительных случайных величин.
Дисперсия, среднеквадратичное отклонение и коэффициент вариации, а также размах являются мерами рассеяния значений случайной величины около среднего значения. Чем они больше, тем сильнее рассеяние.
Асимметрия – степень асимметричности распределения значений случайной величины относительно среднего значения,
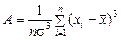 . (2.5)
. (2.5)
Эксцесс – степень остро- или плосковершинности распределения значений случайной величины относительно нормального закона распределения,
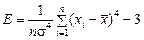 . (2.6)
. (2.6)
Асимметрия и эксцесс являются безразмерными величинами. Они отражают особенности группировки значений случайной величины около среднего значения.
Рассмотренные статистические характеристики относятся к множеству значений х 1, х 2,..., хn. Если множество представляет собой выборку из генеральной совокупности, то возникает задача оценки ее статистических характеристик по выборочным данным. Наибольшее значение имеют оценка математического ожидания и дисперсии генеральной совокупности.
Математическое ожидание случайной величины М (х) – это ее среднее значение в генеральной совокупности. Оно, за редким исключением, бывает неизвестно, и приходится пользоваться его приближенной оценкой (точечной оценкой) – выборочным средним значением 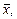 определяемым по формуле (2.1). При увеличении числа наблюдений выборочное среднее стремится к пределу – к математическому ожиданию.
определяемым по формуле (2.1). При увеличении числа наблюдений выборочное среднее стремится к пределу – к математическому ожиданию.
Дисперсия генеральной совокупности D (х) – это число, равное среднему квадрату отклонений случайной величины от ее математического ожидания. Если математическое ожидание известно, то дисперсию находят по формуле
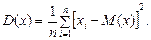 (2.7)
(2.7)
Если математическое ожидание неизвестно, то определяют оценку дисперсии по формуле
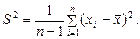 (2.8)
(2.8)
Единица в знаменателе формулы (2.8) отражает одну использованную степень свободы: вместо математического ожидания в формулу подставлено выборочное среднее значение. При увеличении числа наблюдений n оценка дисперсии S 2 стремится к дисперсии генеральной совокупности D (х).
Формулы (2.2) и (2.8) похожи друг на друга, но применяют их в разных случаях. Первая используется для характеристики выборки, а вторая – для характеристики генеральной совокупности.
|
|
|
В ряде задач возникает необходимость рассчитывать статистические характеристики суммы или разности случайных величин, а также произведения случайной величины на постоянный множитель.
Пусть имеется случайная величина х. Если умножить ее значения на постоянный множитель, то получим новую случайную величину у = ах. Статистические характеристики новой случайной величины преобразуются следующим образом:
| среднее значение | у ср = ах ср; |
| дисперсия | 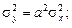
|
| среднеквадратичное отклонение | s у = а s х. |
При этом коэффициент вариации, асимметрия и эксцесс не изменят своих значений. Очевидно, что деление значений случайной величины на постоянную величину а равносильно умножению на обратную величину 1/ а и приведенные формулы сохраняют свою силу.
Если к случайной величине х прибавить постоянное слагаемое а, т.е. у = х + а, то изменится и среднее значение: 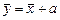 . Однако значения дисперсии, среднеквадратичного отклонения, асимметрии и эксцесса сохранятся. Вычитание постоянного слагаемого равносильно изменению знака слагаемого а на – а.
. Однако значения дисперсии, среднеквадратичного отклонения, асимметрии и эксцесса сохранятся. Вычитание постоянного слагаемого равносильно изменению знака слагаемого а на – а.
Наибольший интерес представляет ситуация, когда производится сложение (вычитание) двух и более случайных величин. Пусть имеются две независимые случайные величины х и у, их сумма (разность) образует третью случайную величину z = x ± y. Статистические характеристики меняются следующим образом:
| среднее значение | 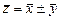 ; ;
|
| дисперсия | 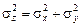 . .
|
Если имеется n независимых случайных величин х 1, х 2,..., хn и находится их сумма z = x 1 + x 2 +... + xn, то имеем соотношения:
| средние значения | 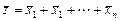 ; ;
| |
| дисперсии | 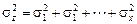 . .
| (2.9) |
Особенно большое значение имеет последнее равенство, известное как теорема сложения дисперсий: дисперсия суммы независимых случайных величин равна сумме их дисперсий. Используя эту теорему, можно доказать, что дисперсия среднего значения 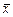 из n значений хi в n раз меньше дисперсий исходных значений хi:
из n значений хi в n раз меньше дисперсий исходных значений хi:
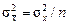 . (2.10)
. (2.10)
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 4309; Нарушение авторских прав?; Мы поможем в написании вашей работы!