КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Метод списочных расписаний
|
|
|
|
Планирование для единичного ББ заключается в построении как можно более короткого плана. Поскольку эта проблема имеет переборный характер, внимание было сосредоточено на эвристических алгоритмах планирования. Среди таких алгоритмов наиболее подходящими оказались списочные расписания. Алгоритмы планирования по списку при линейном росте времени планирования при увеличении числа планируемых объектов, дают результаты, отличающиеся от оптимальных всего на 10-15%.
В таких расписаниях оператором присваиваются приоритеты по тем или
иным эвристическим правилам, после чего операторы упорядочиваются по
убыванию или возрастанию приоритета в виде линейного списка. В процессе
планирования затем осуществляется назначение операторов процессорам в по-
рядке их извлечения из списка.
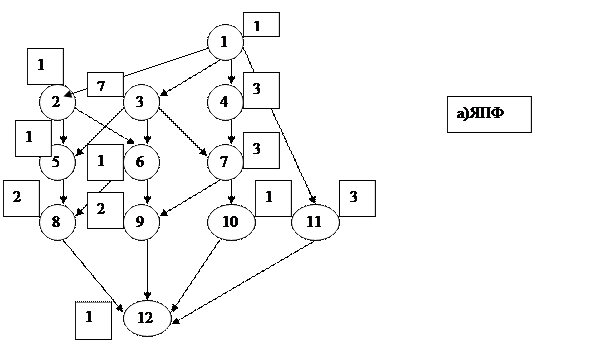
На рисунке (а) представлена исходная ЯПФ. Номера вершин даны внутри
кружков, а время исполнения — около вершин. На рисунке (б) приведены уровни вершин. Под уровнем вершины понимается длина наибольшего пути из этой вершины в конечную. Построим для примера два расписания из множества возможных. Для каждого из них найдем характеристики всех вершин по соот
ветствущим алгоритмам и примем значения этих характеристик в качестве ве-
личин приоритетов этих вершин.
В первом расписании величина приоритета вершины есть ее уровень. Это
расписание УР. Во втором расписании величина приоритета вершины есть ее
уровень без учета времени исполнения, то есть здесь веса всех вершин полага-
ются одинаковыми (единичными).
| УР | УР без учета веса | ||
| П | В | П | В |
|
|
|
б) Приоритеты и списки вершин
(П— приоритеты, В — номера вершин)
в) Уровни вершин
| номера вершины | ||||||||||||
| уровни |
г) Реализация расписаний (Р1, Р2 — процессоры, X — простой процессора)
УР (по уровню вершин)
| Р1 | ||||||||||||||
| Р2 | Х | Х |
УР без учета веса вершин
| Р1 | Х | Х | ||||||||||||||
| Р2 | Х | Х | Х | Х |
Об оптимальности расписания можно судить по количеству простоев про-
цессоров. Первое расписание дает 2, второе — 5.
Классификация Фишера для мелкозернистого паралеллизма
Мелкозернистый параллелизм – это параллелизм в обработке смежных ко
манд, операторов, небольших векторов данных.
Чтобы реализовать этот вид параллелизма, компилятор и аппаратура должны выполнить следующие действия: определить зависимости между операциями; определить операции, которые не зависят ни от каких еще не завершенных операций; спланировать время и место выполнения операций.
В соответствиис этим архитектуры с МЗП можно классифицировать сле-
дующим образом:
1. Последовательностные архитектуры: архитектуры, в которых компиляторне помещает в программу в явном виде какую-либо информацию о параллелизме. Компилятор только перестраивает код для упрощения действий аппа-
ратуры по планированию. Представителями этого класса являются супер-
скалярные процессоры.
2. Архитектуры с указанием зависимостей: в программе компилятором явно представлены зависимости, которые существуют между операциями, неза-
|
|
|
висимость между операциями определяет аппаратура. Этот класс представ-
ляют процессоры потока данных.
3. Независимостные архитектуры: архитектуры, в которых компилятор помещает в программу всю информацию о независимости операций друг от друга. Это VLIW-архитектуры.
Классы микропроцессоров по Фишеру
| Тип архитектуры | Кто определяет зависимость по данным | Кто определяет независимость по данным | Кто планирует время и место выполнения | Представители |
| Последователь- ностные | Аппаратура | Аппаратура | Аппаратура | Сперскалярный Pentium |
| Зависимостные | компилятор | Аппаратура | Аппаратура | Потоковый Pentium Pro |
| Независимостн- ые | компилятор | компилятор | компилятор | VLIW про- цессоры |
Суперскалярные процессоры.
В таких архитектурах компилятор не производит выявление параллелизма, поэтому программы для последовательностных архитектур не содержат явно выраженной информации об имеющемся параллелизме, и зависимости между командами должны быть определены аппаратурой.
В некоторых случаях компилятор может для облегчения работы аппаратуры производить упорядочивание команд. Если команда не зависит от всех других команд, она может быть запущена. Возможны два варианта последовательной архитектуры: суперконвейер и суперскалярная организация. В первом случае параллелизм на уровне команд нужен для того, чтобы исключить остановки конвейера. Здесь аппаратура должна определить зависимости между командами и принять решение, когда запускать очередную команду. Если конвейер способен вырабатывать один результат в каждом такте, такой конвейер называется суперконвейером. За счет уменьшения объема работы в одном такте возникает возможность повысить частоту тактирования процессора. При этом, чем длинее конвейер, тем выше частота. Современные конвейеры имеют длину до 30 этапов.
Дальнейшая цель – построение процессора с несколькими конвейерами,
что позволяет запускать несколько команд каждый такт. Такой процессор называется суперскалярным.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 409; Нарушение авторских прав?; Мы поможем в написании вашей работы!