КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Функции СУБД
Классификация СУБД
Классификация по типу принятой модели данных
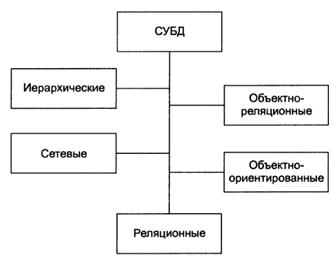
Классификацию баз данных по модели данных иллюстрирует рис. 5
 .
.
Рис. 5. Классификация баз данных по модели данных
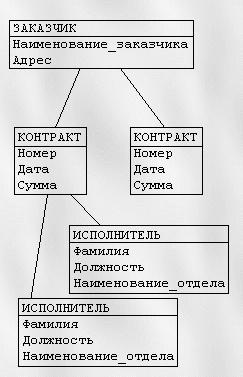
Иерархические базы данных основаны на иерархической модели данных, в которой связь между объектами базы данных образует перевернутое дерево. При такой модели каждый нижележащий элемент иерархии соединен только с одним расположенным выше элементом.
http://www.mstu.edu.ru/study/materials/zelenkov/ch_3_1.html
Рис. 6. Пример иерархической модели данных
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
· Атрибут (элемент данных) - наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
· Запись - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов
· Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные.
Недостатки иерархических БД:
- Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рис. (6)). Таким образом, мы вынуждены дублировать информацию.
Сетевые базы данных основаны на сетевой модели данных, в которой связи между объектами данных могут быть установлены в произвольном порядке.
http://www.mstu.edu.ru/study/materials/zelenkov/ch_3_2.html
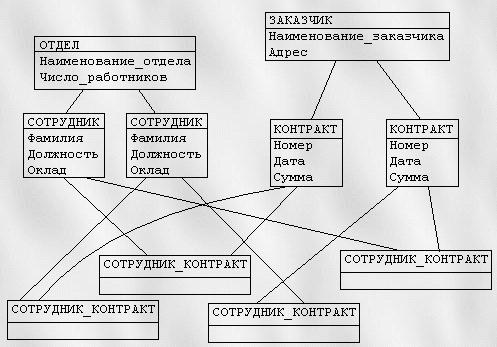
Рис. 7. Пример сетевой модели данных
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между между записью-владельцем и записью-членом также имеет вид 1:N. Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одногогруппового отношения.
Реляционные базы данных основаны на реляционной модели данных, в которой каждая единица данных в базе данных однозначно определяется именем таблицы (называемой отношением), идентификатором записи (кортежа) и именем поля.
http://www.mstu.edu.ru/study/materials/zelenkov/ch_4_1.html
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation - "отношение"). Отношения удобно представлять в виде таблиц. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей.

Рис. 8. Пример реляционной модели данных
Объектно-реляционные базы данных содержат объектно-ориентированные механизмы построения структур данных (как минимум, механизмы наследования и поддержки методов) в виде расширений языка и программных надстроек над ядром СУБД.
http://www.fnti.kiae.ru/content/data_base.htm#19
Объектно-реляционная модель данных (ОРМД) реализована с помощью реляционных таблиц, но включает объекты, аналогичного понятию объекта в объектно-ориентированном программировании. В ОРМД используются такие объектно-ориентированные компоненты, как пользовательские типы данных, инкапсуляция, полиморфизм, наследование, переопределение методов и т.п.
К сожалению, до настоящего времени разработчики не пришли к единому мнению о том, что должна обеспечивать ОРМД. В 1999 г. был принят стандарт SQL-99, а в 2003 г. вышел второй релиз этого стандарта, получивший название SQL-3, который определяет основные характеристики ОРМД. Но до сих пор объектно-реляционные модели, поддерживаемые различными производителями СУБД, существенно отличаются друг от друга. О перспективах этого направления свидетельствует тот факт, что ведущие фирмы–производители СУБД, в числе которых Oracle, Informix, INGRES и др., расширили возможности своих продуктов до объектно-реляционной СУБД (ОРСУБД).
В большинстве реализаций ОРМД объектами признаются агрегат и таблица (отношение), которая может входить в состав другой таблицы. Методы обработки данных представлены в виде хранимых процедур и триггеров, которые являются процедурными объектами базы данных, и связаны с таблицами. На концептуальном уровне все данные объектно-реляционной БД представлены в виде отношений, и ОРСУБД поддерживают язык SQL.
Объектно-ориентированные базы данных определяют как новое поколение баз данных, основанное на сочетании трех принципов: реляционной модели, стандартов на описание объектов и принципов объектно-ориентированного программирования.
http://www.fnti.kiae.ru/content/data_base.htm#19
Моделирование данных в ООМД базируется на понятии объекта. ООМД обычно применяется в сложных предметных областях, для моделирования которых не хватает функциональности реляционной модели (например, для систем автоматизации проектирования (САПР), издательских систем и т.п.).
При создании объектно-ориентированных СУБД (ООСУБД) используются разные методы, а именно:
· встраивание в объектно-ориентированный язык средств, предназначенных для работы с БД;
· расширение существующего языка работы с базами данных объектно-ориентированными функциями;
· создание объектно-ориентированных библиотек функций для работы с БД;
· создание нового языка и новой объектно-ориентированной модели дан-ных
К достоинствам ООМД можно отнести широкие возможности моделирования предметной области, выразительный язык запросов и высокую производительность. Каждый объект в ООМД имеет уникальный идентификатор (OID – object identifier). Обращение по OID происходит существенно быстрее, чем поиск в реляционной таблице.
Среди недостатков ООМД следует отметить отсутствие общепринятой модели, недостаток опыта создания и эксплуатации ООБД, сложность использования и недостаточность средств защиты данных.
Классификация по архитектуре
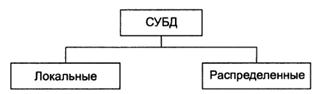
Классификацию баз данных по архитектуре иллюстрирует рис. 9
 .
.
Рис. 9. Классификация баз данных по архитектуре
В локальных базах данных все данные и объекты СУБД находятся на одном компьютере.
В распределенных базах данных различные части данных (группы таблиц, таблицы и даже фрагменты таблиц) и объекты СУБД могут находиться на разных компьютерах.
Пример. В качестве примера можно привести сложное производство (или сеть супермаркетов), разные части которого находятся в разных городах. Каждое предприятие накапливает «свои» данные. Необходимо, чтобы каждое из предприятий имело доступ к одним и тем же данным, как своим, так и данным других предприятий. Решением данной проблемы может быть создание одной локальной базы данных на одном компьютере с механизмом удаленного доступа. Однако это решение нерационально, поскольку быстрый доступ к данным будут получать клиентские компьютеры только того предприятия, на котором находится СУБД. Другим решением данной проблемы может быть создание на каждом предприятии своей копии СУБД. В этом случае возникает затруднение с синхронизацией данных между копиями (особенно в масштабах нашей страны, где в Хабаровске может быть разгар рабочего дня. а в Москве — глубокая ночь). Распределенная СУБД в этом случае обеспечивает механизм хранения данных в разных базах данных таким образом, что при обращении совокупность разных баз данных выглядит как одна база. Тогда часто используемые данные («свои» данные) находятся в той части базы данных, которая расположена на предприятии. Л при необходимости обратиться к «чужим» данным, СУБД делает запрос к удаленной СУБД и получает данные оттуда. Совокупность разных баз данных на разных компьютерах с точки зрения клиента выглядит как одна база данных.
Классификация по способу доступа к БД
Классификацию баз данных по способу доступа иллюстрирует рис. 10
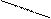

|
|
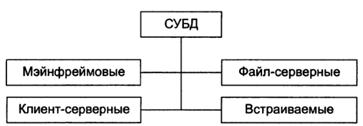
Рис. 10. Классификация баз данных по архитектуре
В мэйнфреймовых базах данных пользовательское рабочее место представляет собой текстовый или графический терминал, а вся информация обрабатывается на том же компьютере, где находится СУБД.
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере, а ядро СУБД находится на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
Клиент-серверные СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней но отношению к клиенту программой, и при необходимости его можно заменить другим. Недостаток клиент-серверных СУБД состоит в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Встраиваемая СУБД представляет собой программную библиотеку, которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить посредством запросов на языке SQL либо путем вызова функций библиотеки из приложения пользователя. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют развертывания сервера.
Рисунки на стр. 23
Двухзвенная архитектура клиент-серверной БД
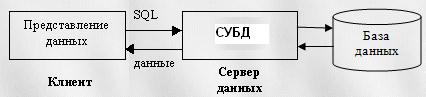
Трехзвенная архитектура БД

Классификация по скорости обработки информации
Классификацию баз данных по скорости обработки информации иллюстрирует рис. 11.
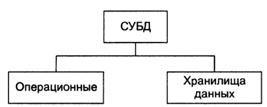
Рис. 11. Классификация баз данных по скорости обработки информации
Операционные (operational), или рабочие (production), базы данных обладают высокими скоростями реакции на запрос, извлечения и представления информации.
Хранилища данных и многомерные хранилища данных (data warehouse, OLAP) -это базы данных с очень большим объемом информации, подготовка представления которой занимает значительный объем времени.
Абстракция данных, управление словарем данных. Функционирование СУБД предусматривает, что определения элементов данных и их отношений (метаданные) хранятся в словаре данных (data dictionary). В свою очередь любые программы получают доступ к данным посредством СУБД. Для поиска необходимых структур данных и их отношений СУБД использует словарь данных, помогая избежать кодирования таких сложных взаимосвязей в каждой программе. Вдобавок любые изменения, которые делаются в структуре базы данных, автоматически регистрируются в словаре данных, что также освобождает программиста от необходимости модифицировать программы доступа к изменившимся структурам данных. СУБД обеспечивает абстракцию данных, тем самым устраняя в системе структурную зависимость и зависимость по данным.
Управление хранением данных. СУБД создает сложные структуры, необходимые для хранения данных, освобождая программистов от определения и программирования физических свойств данных. Современные СУБД обеспечивают хранение не только данных, но и связанных с данными экранных срорм, схем отчетов, правил проверки данных, кода процедур, систем обработки мультимедиа, форматов изображений, и т. п.
Преобразование и представление данных. СУБД берет на себя задачу структурирования вводимых данных, преобразуя их в 4юрму. удобную для хранения. Поэтому СУБД и в данном случае избавляет человека от рутинной работы по прескоразованию логической i (рормата данных В физический формат. Ооееиечивая независимость данных, СУБД преобразует логические запросы в команды, определяющие их физическое местоположение и извлечение. Таким образом, СУБД обеспечивает программную независимость и абстракцию данных.
Управление безопасностью. СУБД создает систему безопасности, которая обеспечивает защиту пользователя и конфиденциальность данных внутри БД. Пранила безопасности устанавливают, какие пользователи могут получить доступ к базе данных, к каким элементам данных пользователь может получить доступ, какие операции с данными (чтение, добавление, удаление или изменение) может выполнять пользователь.
Управление многопользовательским доступом. СУБД создает сложные структуры, обеспечивающие доступ к данным нескольких пользователей одновременно. Для того чтобы обеспечить целостность и непротиворечивость данных, в СУБД применяются сложные алгоритмы, гарантирующие, что несколько пользователей могут получить одновременный доступ к базе данных без риска нарушить ее целостность.
Управление резервным копированием и восстановлением. В СУБД имеются процедуры резервного копирования и восстановления данных, обеспечивающие их безопасность и целостность. Современные СУБД содержат специальные утилиты, с помощью которых администраторы базы данных могут выполнять регулярные и экстренные процедуры резервного копирования и восстановления данных. Восстановление данных производится после повреждения БД, например, в случае появления сбойного сектора на жестком лиске или после аварийного отключения питания. Такая возможность необходима для обеспечения целостности данных.
Управление целостностью данных. В СУБД предусмотрены правила, обеспечивающие целостность данных, что позволяет минимизировать избыточность данных н гарантировать их непротиворечивость. Для обеспечения целостности данных используются их связи, которые хранятся в словаре данных.
Поддержка языка доступа к данным и интерфейсов прикладного программирования. СУБД обеспечивает доступ к данным при помощи языка запросов. Язык запросов - это непроцедурный язык, то есть он предоставляет пользователю возможность определить, что необходимо выполнить, не указывая, как это сделать. В состав языка запросов СУБД входят два основных компонента: язык определения данных (Data Definition Language, DDL) и язык манипулирования данными (Data Manipulation Language, DML). DDL определяет структуры, в которых размещаются данные, a DML позволяет конечным пользователям извлекать данные из БД. СУБД также предоставляет программистам доступ к данным из процедурных языков третьего поколения, таких как COBOL, С, PASCAL и др. В составе СУБД имеются административные утилиты, ориентированные на администраторов и проектировщиков базы данных и предназначенные для внедрения, текущего контроля и обслуживания базы данных.
Интерфейсы взаимодействия с базш данных. Текущее поколение СУБД обеспечивает специальные программы взаимодействия, разработанные для того, чтобы база данных могла принимать запросы конечных пользователей в сетевом окружении. Фактически, возможности взаимодействия конечных пользователей с базой данных являются неотъемлемой составляющей современных СУБД. Например, СУБД предоставляет функции взаимодействия для получения доступа к базе данных, используя в качестве внешнего интерфейса интернет-браузер (Mozilla Firefox, Opera или Internet Explorer). В подобной среде взаимодействие может осуществляться несколькими способами:
- конечный пользователь может получать ответы на запросы, заполняя экранные формы с помощью выбранного им браузера;
· средствами СУБД можно автоматизировать публикацию форм отчетов в Интернете посредством веб-форматирования, что позволяет просматривать отчеты в любом браузере и др.
|
Дата добавления: 2014-01-07; Просмотров: 2079; Нарушение авторских прав?; Мы поможем в написании вашей работы!