КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Трассировочные ресурсы
|
|
|
|
Трассировочные ресурсы
Кроме отображения (map) цифровых узлов на отдельные логические ячейки требуется также распределить их по кристаллу и запрограммировать электрические соединения между отдельными ячейками (place & route). Реализация всего многообразия соединений, характерных для проектов различного типа, представляет собой достаточно сложную задачу. Обычное увеличение количества трассировочных линий и точек их подключения к логическим ячейкам не вполне решает задачу качественной трассировки. Кроме увеличения площади кристалла (и его удорожания) в этом случае будет наблюдаться ухудшение временных характеристик чрезмерно длинных линий, пытающихся обеспечить большое количество связей. Но какая-то часть сигналов, от которых в большой степени зависят временные характеристики всего проекта в целом, требует быстрого распространения по кристаллу. Поэтому современные ПЛИС содержат иерархически организованные уровни трассировочных ресурсов, обеспечивающих баланс между количеством соединений и их временными характеристиками.
Основная и наиболее явная часть трассировочных ресурсов называется главной трассировочной матрицей (Global Routing Matrix, GRM) и к ней вполне применимы рассуждения о трассировочных линиях, приведенные выше. Эту матрицу можно условно считать «ресурсом общего назначения», поскольку достаточно легко подобрать примеры, когда существенно лучшие результаты достигались бы с использованием ресурсов совершенно иного типа.
Наиболее ярким примером такого ресурса являются глобальные линии распространения тактового сигнала. Синхронный стиль проектирования в современных условиях наиболее предпочтителен (исследование этого вопроса является темой отдельной большой публикации), поэтому эффективность распределения по кристаллу тактового сигнала является, в некотором роде, определяющей для успешной реализации проекта, работающего на большой частоте. Эту задачу несколько облегчает тот факт, что тактовый сигнал подается на вполне определенный (тактовый) вход триггеров логических ячеек и тактовые входы выделенных устройств с синхронным интерфейсом (например, блочной памяти). Поэтому тактовые линии не перегружены коммутационными устройствами и могут быть более или менее равномерно распределены по кристаллу, обеспечивая минимальные относительные задержки распространения. Эффективность работы этих линий дополнительно обеспечивается блоками автоподстройки задержки (Delay Locked Loop, DLL), а в более поздних ПЛИС — блоками управления тактовым сигналом (Digital Clock Management, DCM). Подробное описание этих устройств вряд ли целесообразно приводить в данной статье, поскольку с точки зрения сравнения возможностей серий Spartan и Virtex более интересной будет информация о количестве таких блоков.
|
|
|
Ранние семейства, использовавшие DLL, обычно содержали по 4 таких устройства, подключаемых к так называемым глобальным тактовым входам. Эти входы, по одному на каждую «четверть» блоков ввода-вывода, представляют собой обычные программируемые входы, пригодные к использованию разработчиком, однако блоки автоподстройки задержки могут располагаться только после них. На этот момент всегда необходимо обращать внимание при разработке устройств на ПЛИС. Для семейств Virtex/E/Spartan-II/IIE использовались первичные (primary) и вторичные (secondary) тактовые входы. Функциональные возможности для всех этих семейств в принципе одинаковы, хотя в более скоростных устройствах Virtex реализованы и более скоростные блоки.
Четыре устройства управления тактовым сигналом (каждое со своим входом) позволяют организовать на одном кристалле четыре независимые области, каждая из которых использует собственный тактовый сигнал. Такое свойство становится особенно привлекательным при организации распределенных вычислительных систем, когда на одном кристалле располагается несколько устройств, каждое из которых может быть независимо включено или выключено, переведено на пониженную частоту и т. п. Соответственно, управление тактовым сигналом является дополнительным предметом для обсуждения. В этой связи интересно, что все устройства Spartan-3 содержат по 4 DCM, вплоть до объема в 5 млн вентилей (кроме самого младшего устройства, в котором таких блоков нет), а в более мощной серии Virtex (имеются в виду устройства Virtex-II и выше, в которых и появились DCM) их количество составляет 4, 8 или 12 в зависимости от объема кристалла. Увеличенное количество независимых тактовых сетей, которые могут быть реализованы в этих ПЛИС, позволяет говорить, что данная серия гораздо больше предназначена для построения высокопроизводительных распределенных систем обработки сигналов. Разумеется, возможностей аналогичных блоков семейства Spartan-3 это не отменяет, но опять-таки складывается впечатление, что ПЛИС Virtex предназначены для работы «без ограничений» (разработка уникальных высокопроизводительных устройств или прототипирование новых изделий, когда разработчик не хочет ограничивать себя возможностями платформы), а серия Spartan больше предназначена для относительно небольших партий изделий, когда становятся понятными требования к аппаратной платформе, и окончательно определяется, какая именно из ПЛИС Spartan удовлетворяет требованиям проекта.
|
|
|
Если тот факт, что тактовые сигналы крайне желательно подключать к вполне определенным выводам ПЛИС, широко известен разработчикам, то, как правило, не существует особенной необходимости интересоваться внутренним строением прочих трассировочных ресурсов. Организацию внутренних соединений с их помощью берут на себя средства САПР, выбирающие оптимальные способы соединения отдельных логических ячеек.
Очевидным решением является прямое соединение соседних ячеек. Однако при этом такие виды связей как магистрали данных, длинные линии с большим коэффициентом разветвления и прочие подобные им реализуются весьма неэффективно. Действительно, передать сигнал на пятую ячейку в том же ряду оказывается возможным только с помощью пяти последовательных передач сигнала соседним ячейкам. С другой стороны, реализовать соединения «каждый с каждым» в ПЛИС объемом несколько десятков тысяч ячеек попросту нереально.
|
|
|
В этой связи в FPGA Xilinx комбинируются несколько видов трассировочных ресурсов:
· Длинные линии (long line), идущие вдоль ряда логических ячеек, и подключаемые к каждой шестой ячейке в ряду.
· Hex line, подключаемые к каждой третьей ячейке.
· Double line, подключаемые «через одну» ячейку.
· Уже упоминавшиеся выше прямые соединения (direct line), подключающие ячейку к каждой из 8 соседних.
Виды трассировочных ресурсов, перечисленных в этом списке, представлены на рис. 6.
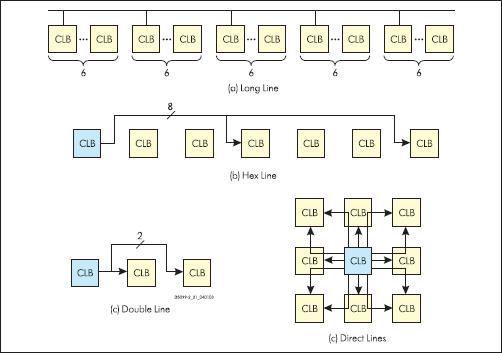
Рис. 6. Иерархия трассировочных ресурсов FPGA Xilinx
Очевидно, что простые проекты можно реализовать, используя небольшое количество трассировочных линий. Это дает возможность упростить топологию кристалла, уменьшив таким образом его цену — явно напрашивающееся решение для серии Spartan. Действительно, для простых проектов вполне достаточно относительно простой трассировочной матрицы. Однако экономия на трассировочных ресурсах в высокопроизводительных high-end FPGA может привести к весьма неприятным эффектам. В частности, при больших коэффициентах заполнения кристалла задержки распространения резко увеличиваются (трассировка насыщенного проекта достаточно сложна для САПР). Наиболее неприятным для разработчика может стать появление так называемых wire-through логических ячеек, или, в переводе, ячеек, реализующих сквозное соединение. При недостаточном количестве трассировочных линий и невозможности пустить проводник «в обход» САПР иногда удается использовать внутренние ресурсы ячейки таким образом, чтобы они передавали на выход копию входного сигнала. Естественно, задержки сигнала, пропущенного через комбинаторную логику ячейки, возрастают, и таких ситуаций следует всячески избегать. Более того, при этом первоначальные оценки разработчика, относящиеся к требуемому логическому объему ПЛИС, необходимо скорректировать в большую сторону. Таким образом, недостаток трассировочных ресурсов может стать источником целого комплекса негативных явлений, и этого следует избегать, особенно для high-end FPGA.
|
|
|
Следует подчеркнуть, что решение САПР об использовании ячеек в качестве своеобразного трассировочного ресурса нельзя считать неэффективным. Напротив, возможность реализации такого «последнего средства» свидетельствует о некотором алгоритмическом запасе устойчивости САПР. Альтернативой явился бы отказ трансляции некоторых проектов, наступающий при относительно небольшом коэффициенте использования кристалла.
Программируемые соединения различных типов, имеющиеся в составе любой ПЛИС, на первый взгляд могут казаться сугубо вспомогательными устройствами. Действительно, все оценки производителей, касающиеся программируемых устройств, используют в основном сведения о числе логических ячеек, реже уточняется объем блочной памяти и прочих выделенных ресурсов. Программируемые соединения при этом упоминаются редко, и считается, что их количество вполне достаточно для формирования на кристалле различных цифровых узлов. Отчасти ситуация обстоит именно так, хотя можно отметить, что практически никогда не удается получить 100%-ного заполнения кристалла FPGA ввиду невозможности провести соединения со всеми без исключения логическими ячейками (не хватит именно свободных трассировочных ресурсов). Сравнительные характеристики проектов на базе дешевой серии Spartan и высокопроизводительной Virtex также подтверждают, что количественный и качественный состав трассировочных линий оказывают прямое влияние на характеристики проектов.
В публикациях, посвященных архитектуре семейства Virtex и сравнительному анализу архитектур основных семейств ПЛИС Xilinx, рассматривались вопросы организации трассировочных ресурсов и типов этих ресурсов. В частности, одним из наиболее эффективных видов трассировочных линий являются короткие локальные связи, соединяющие соседние ячейки. Очевидно, что соединить близко расположенные ячейки по принципу «каждый с каждым» невозможно, и соединения в пределах некоей области могут выполняться путем последовательной передачи сигнала от ячейки к ячейке. В англо-язычной документации для такого элементарного шага используется термин hop. На рис. 6 показана схема соединений базовой ячейки (показана в центре) с соседними, причем цветами выделены ячейки, достижимые за 1, 2 и 3 шага (hops) локальных соединений.
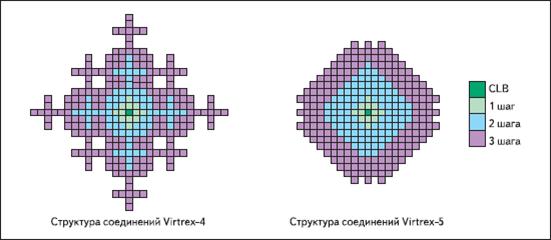
Рис. 6. Схема расположения логических ячеек, доступных за различное число шагов
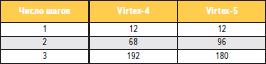
Изменения в схеме трассировочных ресурсов поясняются достаточно простой формулировкой: diagonal routing. Иными словами, в дополнение к вертикальным и горизонтальным трассировочным линиям, в Virtex-5 предусмотрены диагональные соединения между логическими ячейками. Это весьма интересное решение, которое к тому же обеспечивает существенно лучшие характеристики компактных цифровых узлов (до сотни ячеек). В таблице 1 приведено количество CLB, доступных за 1, 2 и 3 шага трассировки для ПЛИС Virtex-4 и Virtex-5. Видно, что основной выигрыш Virtex-5 получил для двух шагов: вместо 68 ячеек доступно 96 — почти в полтора раза больше. Такое решение существенно повышает привлекательность нового семейства в реальных проектах среднего и большого размера, поскольку в синтетических тестах, обычно имеющих небольшой объем, проблемы трассировки ресурсов зачастую в явном виде не проявляются.
Для реализации логических функций и локальных соединений использована
технология ExpressFabric. Она включает в себя реализацию таблиц истинности LUT (Look-Up Table) с 6 независимыми входами в сочетании с диагональной структурой локальных
программируемых соединений, как показано на рисунке 1. Данная технология позволяет реализовывать комбинаторную логику при помощи меньшего числа логических уровней
(последовательно соединенных ячеек) и использует меньшее количество соединений с соседними блоками по сравнению с Virtex-4. Все это уменьшает задержки распространения сигнала и, таким образом, увеличивает производительность проекта.
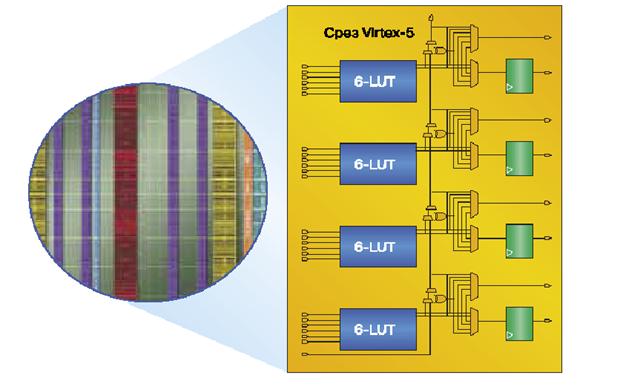
Рис. 5. Технология ExpressFabric ПЛИС Virtex-5
Таблица 1. Число логических ячеек, доступных за фиксированное число шагов в матрице локальных соединений
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 614; Нарушение авторских прав?; Мы поможем в написании вашей работы!