КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модели архитектур совместно используемой памяти
 |
В системах с общей памятью все процессоры имеют равные возможности по дос-
тупу к единому адресному пространству. Единая память может быть построена
как одноблочная или по модульному принципу, но обычно практикуется второй
вариант.
Вычислительные системы с общей памятью, где доступ любого процессора к па-
мяти производится единообразно и занимает одинаковое время, называют систе-
мами с однородным доступом к памяти и обозначают аббревиатурой UMA (Uniform
Memory Access). Это наиболее распространенная архитектура памяти параллель-
ных ВС с общей памятью [120].
Технически UMА-системы предполагают наличие узла, соединяющего каждый
из п процессоров с каждым из т модулей памяти. Простейший путь построения
таких ВС — объединение нескольких процессоров (Pi) с единой памятью (Mp) по-
средством общей шины — показан на рис. 11.3, а. В этом случае, однако, в каждый
момент времени обмен по шине может вести только один из процессоров, то есть
процессоры должны соперничать за доступ к шине. Когда процессор Рi, выбирает
из памяти команду, остальные процессоры Pj (i не равно j) должны ожидать, пока
шина освободится. Если в систему входят только два процессора, они в состоянии рабо-
тать с производительностью, близкой к максимальной, поскольку их доступ к шине
можно чередовать; пока один процессор декодирует и выполняет команду, другой
вправе использовать шину для выборки из памяти следующей команды. Однако
когда добавляется третий процессор, производительность начинает падать. При
наличии на шине десяти процессоров кривая быстродействия шины (рис. 11.3, в)
становится горизонтальной, так что добавление 11-го процессора уже не дает по-
|
|
|
вышения производительности. Нижняя кривая на этом рисунке иллюстрирует тот
факт, что память и шина обладают фиксированной пропускной способностью, оп-
ределяемой комбинацией длительности цикла памяти и протоколом шины, и в
многопроцессорной системе с общей шиной эта пропускная способность распре-
делена между несколькими процессорами. Если длительность цикла процессора
больше по сравнению с циклом памяти, к шине можно подключать много процес-
соров. Однако фактически процессор обычно намного быстрее памяти, поэтому
данная схема широкого применения не находит
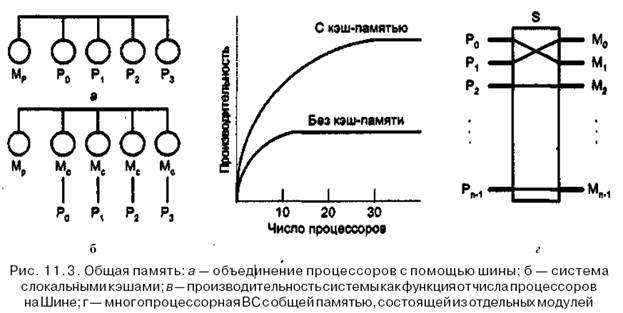
Альтернативный способ построения многопроцессорной ВС,с общей памятью
на основе UMA показан на рис. 11.3, г. Здесь шина заменена коммутатором, марш-
рутизирующим запросы процессора к одному из нескольких модулей памяти.
Несмотря на то что имеется несколько модулей памяти, все они входят в единое
виртуальное адресное пространство. Преимущество такого подхода в том, что ком-
мутатор в состоянии параллельно обслуживать несколько запросов. Каждый про-
цессор может быть соединен со своим модулем памяти и иметь доступ к нему на
максимально допустимой скорости. Соперничество между процессорами может
возникнуть при попытке одновременного доступа к одному и тому же модулю па-
мяти, В этом случае доступ получает только один процессор, а прочие — блокиру-
ются.
К сожалению, архитектура UMA не очень хорошо масштабируется. Наиболее
распространенные системы содержат 4-8 процессоров, значительно реже
32-64 процессора. Кроме того, подобные системы нельзя отнести к отказоустой-
чивым, так как отказ одного процессора или модуля памяти влечет отказ всей ВС
Другим подходом к построению ВС с общей памятью является неоднородный
доступ к памяти, обозначаемый как NUMA (Non-Uniform Memory Access). Здесь
по-прежнему фигурирует единое адресное пространство, но каждый процессор
|
|
|
имеет локальную память. Доступ процессора к собственной Локальной памяти
производится напрямую, что намного быстрее, чем доступ к удаленной памяти через
коммутатор или сеть. Такая система может быть дополнена глобальной памятью,
тогда локальные запоминающие устройства играют роль быстрой кэш-памяти для
глобальной памяти. Подобная схема может улучшить производительность ВС, но
не в состоянии неограниченно отсрочить выравнивание прямой производитель-
ности. При наличии у каждого процессора локальной кэш-памяти (рис. 11.3,6)
существует высокая вероятность (р > 0,9) того, что нужные команда или данные
уже находятся в локальной памяти. Разумная вероятность попадания в локаль-
ную память существенно уменьшает число обращений процессора к глобальной
памяти и, таким образом, ведет к повышению эффективности. Место излома кри-
вой производительности (верхняя кривая на рис. 11.3, в), соответствующее точке,
в которой добавление процессоров еще остается эффективным, теперь перемеща-
ется в область 20 процессоров, а точка, где кривая становится горизонтальной, -
в область 30 процессоров.
В рамках концепции NUMA реализуется несколько различных подходов, обо-
значаемых аббревиатурами СОМА, CC-NUMA и NCC-NUMA.
В архитектуре только с кэш-памятью (СОМА, Cache Only Memory Architecture)
локальная память каждого процессора построена как большая кэш-память
для быстрого доступа со стороны ≪своего≫ процессора [44]. Кэши всех процессо-
ров в совокупности рассматриваются как глобальная память системы. Собственно
глобальная память отсутствует. Принципиальная особенность концепции СОМА
выражается в динамике. Здесь данные не привязаны статически к определенному
модулю памяти и не имеют уникального адреса, остающегося неизменным в тече-
ние всего времени существования переменной. В архитектуре СОМА данные пе-
реносятся в кэш-память того процессора, который последним их запросил, при этом
переменная не фиксирована уникальным адресом и в каждый момент времени
может размещаться в любой физической ячейке. Перенос данных из одного ло-
кального кэша в другой не требует участия в этом процессе операционной систе-
мы, но подразумевает сложную и дорогостоящую аппаратуру управления памя-
|
|
|
тью. Для организации такого режима используют так называемые каталоги кэшей.
Отметим также, что последняя копия элемента данных никогда из кэш-памяти не
удаляется.
Поскольку в архитектуре СОМА данные перемещаются в локальную кэш-па-
мять процессора-владельца, такие ВС в плане производительности обладают су-
щественным преимуществом над другими архитектурами NUMА. С другой сторо-
ны, если единственная переменная или две различные переменные, хранящиеся
в одной строке одного и того же кэша, требуются двум процессорам, эта строка
кэша должна перемещаться между процессорами туда и обратно при каждом дос-
тупе к данным. Такие эффекты могут зависеть от деталей распределения памяти
и приводить к непредсказуемым ситуациям.
Модель кэш-когерентного доступа к неоднородной памяти (CC-NUMA, Cache
Coherent Non-Uniform Memory Architecture) принципиально отличается от модели
СОМА. В системе CC-NUMA используется не кэш-память, а обычная физически
распределенная память. Не происходит никакого копирования страниц или дан-
ных между ячейками памяти. Нет никакой программно реализованной передачи
сообщений. Существует просто одна карта памяти, с частями, физически связан-
ными медным кабелем, и ≪умные≫ аппаратные средства. Аппаратно реализован-
ная кэш-когерентность означает, что не требуется какого-либо программного обес-
печения для сохранения множества копий обновленных данных или их передачи.
Со всем этим справляется аппаратный уровень. Доступ к локальным Модулям па-
мяти в разных узлах системы может производиться одновременно и происходит
быстрее, чем к удаленным модулям памяти.
Отличие модели с кэш-некогерентным доступом к неоднородной памяти (NCCNUMA,
Non-Cache Coherent Non-Uniform Memory Architecture) от CC-NUMA
очевидно из названия. Архитектура памяти предполагает единое адресное простран-
ство, но не обеспечивает согласованности глобальных данных на аппаратном уровне.
Управление использованием таких данных полностью возлагается на программное
обеспечение (приложения или компиляторы). Несмотря на это обстоятельство, пред-
|
|
|
ставляющееся недостатком архитектуры, она оказывается весьма полезной при по-
вышении производительности вычислительных систем с архитектурой памяти типа
DSM, рассматриваемой в разделе ≪Модели архитектур распределенной памяти≫.
В целом, ВС с общей памятью, построенные по схеме NUMA, называют архи-
тектурами с виртуалъной общей памятью (virtual shared memory architectures).
Данный вид архитектуры, в частности CC-NUMA, в последнее время рассматри-
вается как самостоятельный и довольно перспективный вид вычислительных сис-
тем класса MIMD, поэтому такие ВС ниже будут обсуждены более подробно.
|
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 385; Нарушение авторских прав?; Мы поможем в написании вашей работы!