КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Понятие сценария и узла обработки
|
|
|
|
В Deductor Studio для аналитика основополагающим понятием является сценарий.
Сценарий представляет собой последовательность операций с данными, представленную в виде иерархического дерева. В дереве каждая операция образует узел, заголовок которого содержит: имя источника данных, наименование применяемого метода обработки, используемые при этом поля и т.д. Кроме этого, слева от наименования узла стоит значок, соответствующий типу операции.
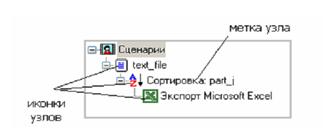
Если узел имеет подчиненные узлы, то слева от его названия будет расположен значок «+», щелчок по которому позволит развернуть узел, т.е. сделать видимыми все его подчиненные узлы, при этом значок «+» поменяется на «–». Щелчок по значку «–», наоборот, сворачивает все подчиненные узлы.
С помощью клавиш Ctrl+↑ и Ctrl+↓ можно перемещать узлы по дереву вверх-вниз в пределах подчинения родительскому узлу.
Сценарий состоит из ветвей. Deductor не имеет собственных средств для ввода данных, поэтому сценарий всегда начинается с узла импорта из какого-либо источника. Любой вновь создаваемый узел импорта будет находиться на верхнем уровне (подчиненным главному узлу Сценарии).
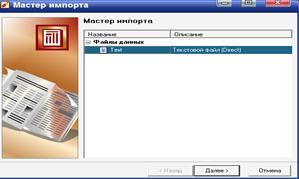
Создание нового узла импорта осуществляется с помощью Мастера импорта. Вызвать мастер можно следующими способами:
· кнопка  на панели инструментов закладки Сценарии;
на панели инструментов закладки Сценарии;
· клавиша F6;
· контекстное меню Мастер импорта.
При вызове мастера импорта откроется окно первого шага мастера.
Импорт из текстовых файлов с разделителями
Структурированный текстовый файл с разделителями - один из самых распространенных форматов хранения данных. Такой файл представляет собой обычный текстовый файл, столбцы данных в котором разделены однотипными символами-разделителями, например символами табуляции, пробела, точки с запятой и т.д.Процесс импорта данных из текстового с разделителями файла в мастере импорта (категория
|
|
|
Текстовой файл (Direct)) содержит следующие шаги:
· указание имени файла;
· настройка параметров импорта;
· настройка импортируемых полей;
· запуск процесса импорта;
· выбор способа визуализации;
· задание сведений об узле.
На шаге Указание имени файла, нажав кнопку  , необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных. После этого в поле Имя файла окна Мастера импорта появится имя выбранного файла и путь.
, необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных. После этого в поле Имя файла окна Мастера импорта появится имя выбранного файла и путь.
Допускается вручную ввести путь к файлу в строке поля Имя файла.
Имеется возможность использовать как абсолютные, так и относительные пути для файлов.
Здесь также доступны настройки:
· Начать импорт со строки – номер строки, начиная с которой будет делаться импорт данных из файла.
· флаг Первая строка является заголовком – установка флажка означает, что узел будет импортировать данные с учетом того, что все записи первой строки являются заголовками столбцов.
· Кодировка – ANSI (Windows) или ANCII (MS DOS).
Выберем текстовый файл Banks идущий в поставке Deductor (по умолчанию расположен в каталоге /Samples директории установки Deductor)
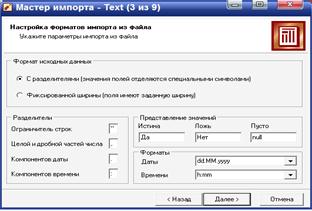
На шаге Настройка параметров импорта нужно настроить параметры импорта данных из текстового файла, так как существует несколько форматов структурированных текстовых файлов. Доступные опции:
· переключатель Формат исходных данных, который определяет символ-разделитель в файле (например: символ табуляции, пробел, запятая). Разделитель чаще всего присутствует. Если же нет, то нужно выбрать переключатель Фиксированной ширины (поля имеют заданную ширину), а позже установить ширину каждого поля.
· Ограничитель строк – при задании данного параметра необходимо указать, какой именно ограничитель строкового значения нужно использовать при импорте данных из текстового файла. Обычно таким ограничителем является символ двойной кавычки ".
|
|
|
· Разделитель дробной и целой части числа – при задании данного параметра необходимо указать символ, разделяющий дробную и целую части в числовых значениях, содержащихся в файле.
· Разделитель компонентов даты – указывается символ, разделяющий компоненты даты в соответствующих значениях, содержащихся в файле.
· Разделитель компонентов времени – указывается символ, разделяющий компоненты времени в соответствующих значениях, содержащихся в файле.
· Форматы Даты/Времени – указываются форматы даты/времени, используемые в импортируемом файле.
· Представление значений – опция для полей логического типа, которое может принимать одно из трех значений – истина (true), ложь (false) и пустое значение (null). Определяет регламент записи в эти значения. Так, при настройках по умолчанию для любого логического поля значение Да будет восприниматься как истина, Нет – как ложь.
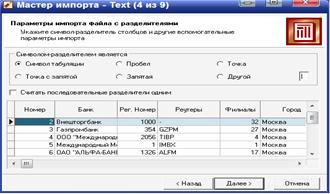
Следующее окно мастера зависит от установленного переключателя в флажке Формат исходных данных. Если был выбран формат С разделителями, то появится вкладка, на которой нужно явно указать символ-разделитель (по умолчанию – табуляция). Здесь же находится флаг Считать последовательные разделители одним – в случае последовательно идущих символов-разделителей они будут восприниматься за один. Такое бывает, например, когда символом-разделителем выступают несколько пробелов.
Предпросмотр текстового файла в виде таблицы внизу (загружаются только первые 10 строк) позволяет убедиться в корректности выбора настроек импорта даже не запуская его.
Если был выбран флаг формат Фиксированной ширины, то появится вкладка, на которой нужно задать границы каждого поля. Создание, как и удаление маркера границы, производится одним щелчком мыши. Двигая маркеры границ столбцов, можно изменять их, если они расставлены неправильно. Данные, распределенные по столбцам, показываются в области предварительного просмотра.
На шаге Настройка параметров столбцов нужно настроить следующие параметры столбцов импортируемых данных, указав соответствующие значения в полях.
|
|
|
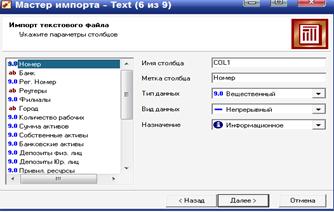
Имя столбца – указывается имя, которое будет служить идентификатором столбца в последующих узлах. По умолчанию предлагается заголовок столбца из текстового файла, если на предыдущем шаге был установлен флажок Первая строка является заголовком.
Иначе будут предложены имена типа COL1, COL2 и т.д. Можно ввести любые имена, которые семантически отражают содержимое столбца, однако допускаются только латинские символы, и имя столбца должно быть уникальным в пределах всех столбцов импортируемого файла.
Метка столбца – название, под которым данный столбец будет виден в визуализаторах. Допускаются любые символы, уникальность имен не обязательна.
Тип данных – указывается тип данных, содержащихся в столбце. Тип выбирается из списка, открываемого щелчком по кнопке в правой части поля:

Вид данных – характер данных, содержащихся в столбце:

Непрерывными могут быть только числовые данные. Дискретный характер носят, как правило, строковые данные.
Назначение – определяет порядок использования поля набора данных, полученного в результате импорта столбца (поля), при дальнейшей обработке импортированных данных:

На шаге Запуск процесса импорта стартует сам процесс импорта данных с ранее настроенными параметрами. Ход процесса импорта отображается с помощью индикатора. Если процесс импорта остановился, это сигнализирует о возможных ошибок при чтении данных. В этом случае появляется окно с сообщением об ошибке.
В случае возникновения ошибок несоответствия типов процесс импорта будет продолжен, но после его окончания будет отображен журнал регистрации ошибок с информацией о месте и причине их появления.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 765; Нарушение авторских прав?; Мы поможем в написании вашей работы!