КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лексический анализатор
Часть транслятора, которая выполняет лексический анализ, называется лексическим анализатором. Лексический анализатор воспринимает исходный текст программы и преобразует его в последовательность лексем - промежуточный язык, удобный для синтаксического анализа. Кроме этого, лексический анализатор строит таблицы (массивы) идентификаторов и констант. Таким образом, основными функциями лексического анализатора являются: построение последовательности лексем; построение таблицы идентификаторов; построение таблицы констант; расстановка ссылок для передачи управления.
Для повышения эффективности последующих действий лексемы обычно представляются в виде пары (код, значение). На этапе синтаксического анализа используется первая компонента пары - код. Вторая компонента - значение, используется при семантических вычислениях. Для языка МИЛАН будем использовать определения лексем, представленные в таблице 7. Заметим, что при распознавании идентификаторов и констант лексическим анализатором используются следующие правила грамматики: 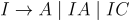 ,
, 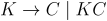 ,
, 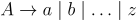 ,
, 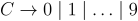 .
.
Таким образом, в последовательности лексем идентификаторы и константы становятся терминалами и грамматика языка упрощается.
Таблица 7
Таблица лексем
| Название лексемы | Код | Запись в языке | Обозначение | Значение |
| Служебные слова: BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | BEGIN DO ELSE END ENDDO ENDIF IF OUTPUT READ THEN WHILE | ||
| Точка с запятой | ; | tz | ||
| Знак отношения: = <> > < >= <= | = <> > < >= <= | otn | k(=)=0 k(<>)=1 k(>)=2 k(<)=3 k(>=)=4 k(<=)=5 | |
| Операция типа сложения: + - | + - | ots | k(+)=0 k(-)=1 | |
| Операция типа умножения: * / | * / | otu | k(*)=0 k(/)=1 | |
| Присваивание | := | oprsv | ||
| Открывающаяся скобка | ( | os | ||
| Закрывающаяся скобка | ) | zs | ||
| Идентификатор | a, b23 | id | Указатель на таблицу идентификаторов | |
| Константа без знака | 32, 0274 | int | Указатель на таблицу констант |
Рассмотрим синтаксическую диаграмму (R-схему) лексического анализатора языка МИЛАН (рис. 6), которая описывает первые три функции: построение массив лексем, таблицы констант и идентификаторов.

Рис. 6. R-схема лексического анализатора языка МИЛАН
Рассмотрим семантические функции к R-схеме лексического анализатора языка МИЛАН. Введем следующие обозначения:
- $Position - текущая позиция в строке, просматриваемая лексическим анализатором;
- $Number_String - текущая строка программы, просматриваемая лексическим анализатором;
- * - при любом условии (любой символ).
Семантические функции к R-схеме лексического анализатора:
y0: подготовка (инициализация таблиц и переменных), $Position=0, $Number_String=1;
y1: чтение следующего символа программы на языке МИЛАН;
y2: увеличение счётчика текущей позиции ($Position++);
y3: переход на новую строку в программе, увеличение счётчика текущей строки, и сброс счётчика позиции ($Number_String++, $Position=0);
y4: накопление символов ключевого слова или идентификатора;
y5: проверка на принадлежность выделенного слова к ключевым словам;
y6: проверка на принадлежность выделенного слова к идентификаторам;
y7: накопление символов константы;
y8: проверка на принадлежность выделенной константы таблице констант;
y9: запись сформированной лексемы в массив лексем;
y10: завершение работы лексического анализатора;
y11: формирование лексемы;
Ограничения: Программа на языке МИЛАН должна содержать <=15 идентификаторов, <= 15 констант, <=500 лексем
Пример №1: Рассмотрим пример обработки лексическим анализатором программы на языке МИЛАН, вычисляющую сумму пяти вводимых чисел.
| BEGIN x:=0; n:=5; WHILE n>0 DO z:= READ; x:= x+z; n:= n-1 ENDDO; OUTPUT(x) END |
Результаты работы лексического анализатора:
1) Таблица лексем
| номер | ||||||||||
| 1, 0 | 19, 1 | 16, 0 | 20, 1 | 12, 0 | 19, 2 | 16, 0 | 20, 2 | 12, 0 | ||
| 11, 0 | 19, 2 | 13, 2 | 20, 1 | 2, 0 | 19, 3 | 16, 0 | 9, 0 | 12, 0 | 19, 1 | |
| 16, 0 | 19, 1 | 14, 0 | 12, 0 | 12, 0 | 19, 2 | 16, 0 | 19, 2 | 14, 1 | 20, 3 | |
| 5, 0 | 12, 0 | 8, 0 | 19, 1 | 19, 1 | 18, 0 | 4, 0 |
2) Таблица идентификаторов 3) Таблица констант
| номер | идентификатор |
| x | |
| n | |
| z |
| номер | константа |
В языке МИЛАН имеются операторы, изменяющие линейный порядок вычислений. Это операторы цикла и развилки. Для организации правильных вычислений необходимо на некоторые лексемы поставит ссылки на номера лексем, куда будет передано управление при выполнении определенных условий. Такие ссылки будем записывать на место значения лексемы.
Для оператора цикла на лексему DO необходимо поставить ссылку $r - номер лексемы, следующей за лексемой ENDDO. На эту лексему будет передано управление, если условие цикла - ложь. Для лексемы ENDDO поставить ссылку $s - номер лексемы WHILE, увеличенный на 1. Это лексема, с которой начинается условие цикла. На нее передается управление после выполнения тела цикла (рис. 7, а).
Для оператора развилки на лексему IF необходимо поставить ссылку $r - номер лексемы, стоящей после лексемы ELSE в полной форме оператора развилки (рис. 7, б), и стоящей после лексемы ENDIF в сокращенной форме (рис. 7, в). На эти лексемы передается управление при ложном условии оператора развилки.

Рис. 7. Расстановка ссылок
Пример №2: После расстановки ссылок в последовательности лексем примера №1 изменяться две лексемы: 14 - (2, 31) и 30 - (7, 11).
Алгоритм расстановки ссылок в общем случае должен обрабатывать вложенные структуры циклов и развилок. Для такой обработки необходимо использовать два независимых стека: один для циклов WHILE, другой для развилок IF. Синтаксическая диаграмма (R-схема) расстановки ссылок представлена на рис 8.
Для описания семантических функций синтаксической диаграммы расстановки ссылок введем обозначения:
- $Tab_Lexems[..]->Code - массив номеров лексем;
- $Tab_Lexems[..]->Value -массив значений лексем;
- $Number_Lexem - номер очередной рассматриваемой лексемы в массиве лексем;
- $Stek_do - стек для циклов WHILE;
- $Stek_if - стек для развилок IF.

Рис. 8. R-схема расстановки ссылок
Семантические функции к R-схеме расстановки ссылок:
y0: подготовка (инициализация стеков и переменных), номер очередной лексемы $Number_Lexem=1, прочитать лексему с номером $Number_Lexem;
y1: значение $Number_Lexem занести стек $Stek_do ($Number_Lexem→$Stek_do);
y2: снять вершину стека $Stek_do в переменную $s ($s ← $Stek_do), снять вершину стека $Stek_do в переменную $r ($r ← $Stek_do), значение $r+1 присвоть лексеме с номером $Number_Lexem [ENDDO→WHILE+1]($Tab_Lexems[$Number_Lexem]->Value=$r+1), значение $Number_Lexem+1 присвоить лексеме с номером $s [DO→ENDDO+1] ($Tab_Lexems[$s]->Value=$Number_Lexem+1);
y3: значение $Number_Lexem занести в стек $Stek_if ($Number_Lexem→$Stek_if);
y4: снять вершину стека $Stek_if в переменную $r ($r ← $Stek_if), присвоить значение $Number_Lexem+1 лексеме c номером $r [THEN→ELSE+1] ($Tab_Lexems[$r]->Value=$Number_Lexem+1), занести в $Stek_if значение $Number_Lexem ($Number_Lexem→$Stek_if);
y5: снять вершину стека $Stek_if в переменную $r ($r←$Stek_if), присвоить значение $Number_Lexem+1 лексеме c номером $r [THEN→ENDIF+1, ELSE→ENDIF+1] ($Tab_Lexems[$r]->Value=$Number_Lexem+1) занести в $Stek_if значение $Number_Lexem ($Number_Lexem→$Stek_if);
y6: завершить работу;
y7: $Number_Lexem++, прочитать очередную лексему с номером $Number_Lexem;
|
|
Дата добавления: 2014-10-15; Просмотров: 638; Нарушение авторских прав?; Мы поможем в написании вашей работы!