КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Помилка вибіркової середньої арифметичної
|
|
|
|
Вивчаючи певну ознаку неможливо дослідити усі об’єкти генеральної сукупності тому, що вона, як правило, дуже чисельна. Можливо навіть складається з нескінченно великого числа членів. Тому робиться вибірка об’єктів, які і досліджуються. При цьому постає таке питання: чи можливо за результатами, отриманими при вивченні вибірки робити висновки про всю генеральну сукупність?
Характеризуючи цілу сукупність лише за її частиною, неможливо уникнути помилок, які називаються помилками репрезентативності.
Навіть при ідеальній організації дослідницької роботи з’являються помилки такого типу.
Помилка репрезентативності середньої арифметичної залежить від двох величин: від різноманітності ознаки у генеральній сукупності і від чисельності вибірки. Чим менша степінь різноманітності (на її величину вказує середнє квадратичне відхилення) і чим більша кількість вибраних для дослідження об’єктів, тим менша величина помилки репрезентативності вибіркового середнього арифметичного. Для розрахунку величини помилки використовується формула: m = 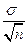 ,
,
де 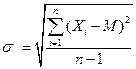 ,
,
Xi – значення і- тої варіанти, і=1,...,n;
М – середнє арифметичне вибірки;
n – об’єм вибіркової сукупності.
Приклад 3.
За даними прикладів 1 і 2 обчислимо помилку середньої арифметичної:
m = 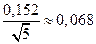 .
.
Критерій вірогідності різниці двох середніх значень (критерій Стьюдента)
Однією з важливих задач біологічного дослідження є отримання даних про результати дії зовнішніх факторів на живий об’єкт. Для проведення дослідів вибираються дві групи об’єктів (не обов’язково однієї чисельності), одна з яких є піддослідною, а інша – контрольною.
Наприклад, необхідно виявити ефективність застосування деякого препарату, що має метою підвищення опору організму по відношенню до конкретної інфекції.
|
|
|
Дослід може бути поставлений так: беруть дві групи тварин. Тваринам однієї групи препарат вводять, а іншим – не вводять. Перша група буде піддослідною, а друга – контрольною. Потім тваринам обох груп вводять інфекцію і спостерігають, скільки днів переживуть тварини піддослідної групи і контрольної.
У таблиці зведені результати досліду:
| Число днів | n | M | 
| m | |||||||
| Дослід | 6,25 | 1,25 | 0,22 | ||||||||
| Контроль | 5,22 | 0,97 | 0,2 |
З таблиці видно, що середні значення для піддослідної і контрольної груп не співпадають. Але це недостатньо для доведення ефективності препарату.
Насправді, кожна група тварин є випадковою вибіркою з генеральної сукупності. Та, як відомо, для різних вибірок, отриманих з однієї і тієї ж генеральної сукупності, середні арифметичні будуть різними.
Покажемо це на простому прикладі.
Нехай є генеральна сукупність, яка складається з 5 варіант (N=5).
xi: 8, 16, 20, 24, 32.
(Числа можуть позначати висоту рослин у сантиметрах).
Замінимо вивчення усієї генеральної сукупності вивченням вибірок з неї об’ємом n =4. Ось ці вибірки: 1) 8, 16, 20, 24;
2) 8, 16, 20, 32;
3) 8, 16, 24, 32;
4) 8, 20, 24, 32;
5) 16, 20, 24, 32.
Обчислюючи для кожної вибірки середнє арифметичне, отримуємо такі значення: М1 =17, М2 =19, М3 =20, М4 =21, М5 =23.)
Тому виникає питання: чи вважати розбіжність між середніми значеннями в піддослідній і контрольній групах просто розбіжністю між двома вибірковими середніми, чи ця розбіжність обумовлена ефективною дією препарату? Або, інакше кажучи, чи можливо узагальнити висновок про ефективність препарату і розглядати вибірки піддослідної і контрольної груп, як вибірки з різних генеральних сукупностей?
Таке питання відноситься до проблем вірогідності різниці середніх арифметичних.
|
|
|
Розглянемо загальний метод розв’язання цієї проблеми.
Починають з припущення, що обидві вибірки зроблені з однієї генеральної сукупності. Тоді різниця між вибірковими середніми пояснюється існуванням такої різниці взагалі. Таке припущення називають нульовою гіпотезою і позначають Н0.
Далі обчислюють ймовірність того, що при умові правильності нульової гіпотези, розбіжність між вибірковими середніми (М1 – М2) може досягти тієї величини, яка є. Якщо ця ймовірність виявиться малою, то нульова гіпотеза відкидається. Граничне допустиме значення ймовірності називають рівнем значущості і позначають a. Яке ж значення ймовірності вважати малим? Як правило, вибирають одне з таких значень a = 0,05 = 5 %, a = 0,01 = 1 %, a = 0,001 = 0,1 %. Різниця між вибірковими середніми вважається значущою (тобто, реальною), якщо ймовірність правильності нульової гіпотези менша за рівень значущості. У такому разі нульова гіпотеза відкидається.
Вибір того чи іншого конкретного значення a визначається конкретними задачами дослідника. Наприклад, якщо досліджується новий лікарський засіб і треба довести його нешкідливість для життя, то навіть рівень значущості 0,001 буде зависоким. Навпаки, якщо мова йде про підвищення продуктивності стада за рахунок недорогої зміни раціону, то достатньо і невеликої впевненості у позитивному результаті.
Критерій, який дозволяє визначити вірогідність різниці вибіркових середніх, був сформульований англійським математиком Вільямом Госсетом (1876 – 1937), який працював під псевдонімом Стьюдента. Критерій носить назву критерію Стьюдента.
Згідно з ним обчислюється величина t = 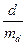 , яка потім порівнюється з табличною величиною tst.
, яка потім порівнюється з табличною величиною tst.
Чисельник d – різниця між середніми арифметичними двох вибіркових груп (знак різниці значення не має: d = | М1 –М2 |), md = 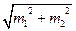 - помилка вибіркової різниці; m1,m2 – помилки репрезентативності порівнюваних вибіркових середніх (m1 =
- помилка вибіркової різниці; m1,m2 – помилки репрезентативності порівнюваних вибіркових середніх (m1 = 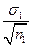 , m2 =
, m2 = 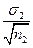 ,
, 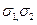 - середні квадратичні відхилення відповідних вибірок, n1, n2 – об’єми вибірок).
- середні квадратичні відхилення відповідних вибірок, n1, n2 – об’єми вибірок).
За таблицею 1 визначається значення tst, яке залежить від двох параметрів:
величини n = n1+n2-2 (n називається числом степенів волі) і ймовірності Р=1-a ( ймовірність впевненості у неправильності нульової гіпотези).
|
|
|
Якщо t £ tst , то нульова гіпотеза приймається (згідно прикладу це означає, що препарат не ефективний). Якщо ж t > tst, то Н0 відкидається.
Приклад 4.
За даними прикладу 3, оцінимо ефективність препарату, використовуючи критерій Стьюдента. Гіпотеза Н0: препарат не ефективний.
Середнє арифметичне значення кількості днів, які пережили тварини піддослідної групи М1 = 6,25, а контрольної М2 = 5,22. Кількість тварин піддослідної групи (об’єм вибірки) n1 = 32, а контрольної n2 = 23. Середні квадратичні відхилення s1 =1,25, s2 = 0,97. Помилки репрезентативності:
m1 =0,22, m2 = 0,2. Отже, згідно критерію Стьюдента обчислюємо величину t = , де d = | М1 –М2 | = | 6,25 – 5,22 | = 1,03; md = = = 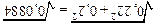 »0,297.
»0,297.
t = 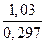 »3,47.
»3,47.
За таблицею 1 визначимо значення величини tst. Число степенів волі
n = n1 + n2 – 2= 32+23 -2= 53»50.
При різних рівнях значущості, маємо t 0,05 = 2,01; t 0,01 = 2,68; t 0,001 = 3,5.
Так як t > t 0,01, то нульова гіпотеза відкидається з ймовірністю 0,99.
Висновок: препарат можна вважати ефективним у 99%.
Метод j (фі)
Метод визначення вірогідності різниці часток (проценту) появи ознаки у вибіркових сукупностях, який запропонований англійським статистиком Р.Е.Фішером (1890 – 1962). Метод може бути застосований при будь-яких значеннях часток, але найчастіше ним користуються, якщо р < 0,2 або р > 0,8.
Фішер показав, що визначити вірогідність різниці часток точніше і простіше, якщо замість кожної частки взяти кут, синус якого дорівнює корню квадратному з цієї частки. Тоді частки перетворюються в кути j за формулою:
j = 0,0349 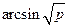 , де p – частка,
, де p – частка,
j – кут у радіанах.
Таке перетворення значно уточнює визначення вірогідності різниці малих (менших 0,2) та великих (більше 0,8) часток.
Вірогідність різниці часток визначається за допомогою метода j такою формулою:F = (j1 - j2)2 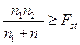 , n1,n2 – об’єми вибірок;
, n1,n2 – об’єми вибірок;
Fst – величина, що знаходиться за таблицею 2. Fst залежить від n1 =1 і n2 = = n1+n2-2.
Приклад 5.
Порівнюється частка 0,00055, яка отримана по групі з n1 =5440, з часткою 0,0054, отриманою по групі з n2 =551. Вірогідність різниці цих часток за допомогою метода j можна визначити так:
j1 =0,0349*1,354 =0,047; j2 = 0,0349*4,21=0,147;
F = 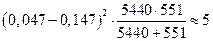 ;
;
|
|
|
n1 =1; n2 = 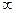 , отже за таблицею 2 для різних рівнів значущості F 0,05=3,8, F 0,01 =6,6,F 0,001 = 10,8.
, отже за таблицею 2 для різних рівнів значущості F 0,05=3,8, F 0,01 =6,6,F 0,001 = 10,8.
Нульова гіпотеза відкидається (з ризиком помилитися 0,05: у 5%, бо F > F0.05)
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 1294; Нарушение авторских прав?; Мы поможем в написании вашей работы!