КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Априорный анализ и его роль в статистическом моделировании
|
|
|
|
Оценка эффективности и деловой активности субъектов экономического процесса и состояния социальной инфраструктуры общества во многом зависит от качества статистического анализа эмпирического материала, от того, насколько точно будут выявлены и научно обоснованны закономерности и тенденции развития.
Основные трудности, связанные с применением количественных математико-статистических методов, заключаются в том, что они достаточно нейтральны к исследуемым социально-экономическим явлениям и процессам.
Поэтому основным этапом проведения статистического исследования на информационной базе, характеризующей реальные социально-экономические явления, является критическая оценка исходных данных с точки зрения их достоверности и научной обоснованности, которая в статистическом моделировании реализуется методами априорного анализа, включающего в себя:
· выявление экономически обоснованных и существенных причинно-следственных связей между признаками и явлениями;
· оценку однородности исследуемой совокупности;
· анализ характера распределения совокупности по изучаемым признакам.
Понятия и категории, используемые при проведении анализа статистическими методами, должны быть точно определены.
Необходимо четко определить, к какому моменту или периоду времени относится исследуемое явление или процесс.
Одной из основополагающих предпосылок проведения научно-обоснованного статистического анализа, адекватно отражающего причинно-следственные связи и зависимости, тенденции развития реальных явлений и процессов в динамике, является однородность статистической совокупности.
Анализ однородности статистической совокупности целесообразно проводить в следующей последовательности:
|
|
|
· определение степени однородности всей совокупности по одному или нескольким существенным признакам;
· определение и анализ аномальных наблюдений;
· выбор оптимального варианта выделения однородных совокупностей.
В статистической теории и практике разработаны различные подходы к оценке степени однородности.
Проблемой оценки однородности совокупности занимались такие известные ученые, как Ю. Аболенцев, Г. Кильдишев, В. Овсиенко и другие.
Наиболее сложным и дискуссионным является вопрос о способах и критериях выделения однородных групп объектов в пределах исходной совокупности.
Важной предпосылкой получения научно-обоснованных результатов статистического анализа и моделирования является проверка гипотезы о близости распределения эмпирических данных нормальному закону. Для нормального закона распределения характерно:
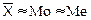 ; As = 0; Ex = 0
; As = 0; Ex = 0
Одним из недостатков данного подхода к оценке характера распределения является наличие субъективности в анализе достаточности величины отклонения 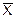 от Me и Mo от Me для подтверждения гипотезы.
от Me и Mo от Me для подтверждения гипотезы.
Любая исследуемая совокупность, наряду со значениями признаков, сложившихся под влиянием факторов, непосредственно характерных для анализируемого объекта, может содержать и значения факторов, полученных под воздействием иных факторов, не характерных для изучаемого объекта, так называемых аномальных наблюдений.
Такие значения резко отличаются от других значений в исследуемой совокупности и, следовательно, использование методологии статистического анализа без изучения аномальных наблюдений приводит к серьезным ошибкам.
Причинами появления в совокупности аномальных наблюдений могут быть ошибки, которые возникают при измерении и передаче информации, агрегировании показателей и так далее. Такие нехарактерные аномальные значения подлежат устранению и Половников В.А. в своей работе, такие наблюдения называет ошибками первого рода. В изучаемой совокупности так же аномальные наблюдения могут возникать из- за воздействия на экономический процесс факторов, объективно существующих, но которые проявляют свои экстремальные воздействия крайне редко. Эти ошибки исследователи относят к ошибкам второго рода и считают, что устранять их при анализе совокупности не следует. Таким образом, причины появления в совокупности аномальных наблюдений можно условно разделить на две группы:
|
|
|
1. Внешние, возникающие в результате технических ошибок (ошибки первого рода).
2. Внутренние, факторы объективно существующие в совокупности (ошибки второго рода).
Существует ряд методов выявления и устранения аномальных наблюдений
Выбор того или иного метода выявления и анализа аномальных наблюдений определяется объемом совокупности, характером исследуемых процессов и задачами анализа.
При анализе динамической или статической информации, наиболее широкое применение получил метод выявления аномальных наблюдений, основанный на определении q – статистики, предложенный в работе Хан Г. и Шапиро С.:
 (1.1)
(1.1)
где:
yt – отдельные уровни ряда;
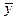 – средний уровень ряда;
– средний уровень ряда;
σy– среднеквадратическое отклонение эмпирических значений уровней ряда от их среднего уровня.
Если для расчетного значения выполняется неравенство:
qt ≥ qкр (р) (1.2)
с заранее заданным уровнем вероятности, то данное наблюдение считается аномальным и, после экономического анализа причин ошибок аномальности, подлежит замене скорректированным значением (в случае ошибки «I») и не подлежат корректировке (в случае ошибки «II»).Если же аномальное значение получилось из-за ошибок первого рода, то рассчитывают его новое значение по следующему алгоритму:
1. Рассчитывается новое значение yi¢ по формуле:
yi¢=qa ×sy +`y (1.3)
2. В исходном ряду уровень yi заменяется на yi¢ и вычисляются новые характеристики ряда ` yi¢ и sy¢ и величину yi¢¢ по формуле (1.3):
3. Вычисляется очередное новое значение данного уровня:
yi¢¢=qa ×sy¢¢ +`y¢ (1.4)
4.Производится сравнение
½ yi¢ - yi¢¢½£ e (1.5).
|
|
|
ε – заданный уровень точности определения 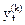 .
.
Если данное условие выполняется, то значение 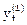 является скорректированным, не аномальным значением, занимает место
является скорректированным, не аномальным значением, занимает место 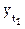 в ряду и анализу подвергается
в ряду и анализу подвергается 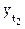 .
.
Если условие не выполняется, то рекомендуется рассчитать 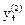 и проверить на аномальность.
и проверить на аномальность.
Процесс корректировки носит итерационный характер.
В анализе временных рядов наибольшее распространение получил метод Ирвина, основанный на определении λ – статистики. При его использовании выявление аномальных наблюдений производится по формуле:
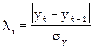 (1.6)
(1.6)
Если расчетное значение превысит уровень критического (с заданным уровнем точности и числом наблюдений) (таблица 1.1), то расчетное значение признается аномальным.
Схема реализации данного метода аналогична предыдущей с той лишь разницей, что 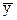 заменяется на yt-1(предыдущее значение уровня ряда).
заменяется на yt-1(предыдущее значение уровня ряда).
Способ, основанный на расчете q – статистики применим для относительно стационарных рядов, так как при использовании для анализа временных рядов, имеющих ярко выраженную тенденцию, он приводит к ошибкам.
Таблица 1.1
Табулированные значения λt
| Число наблюдений | λкр | |
| 0,95 | 0,99 | |
| 2,8 2,2 1,5 1,3 1,3 1,1 1,0 | 3,7 2,9 2,0 1,8 1,7 1,6 1,5 |
Более корректным методом выявления аномальных наблюдений, по мнению авторов ХанГ., Шапиро С., является использование статистики, в которой определяются отклонения от теоретических значений, полученных по уравнению тренда 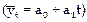 :
:
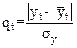 (1.7)
(1.7)
В общем виде, схему градации статистических методов выявления аномальности в исходных данных можно представить следующим образом (рис. 1.1).
Основной задачей статистического исследования на этапе априорного анализа является выделение однородных групп (даже аномальных). В данном случае эффективно применять в анализе комбинационные группировки с развернутым сказуемым.
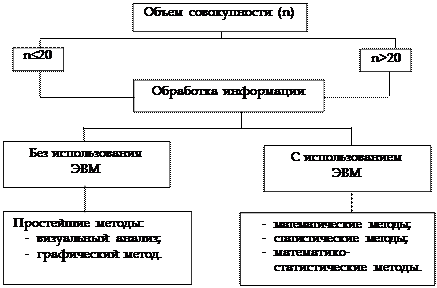
Рис. 1.1. Методы анализа аномальных наблюдений
 Раздел II
Раздел II

|
|
|
|
|
Дата добавления: 2014-12-08; Просмотров: 1072; Нарушение авторских прав?; Мы поможем в написании вашей работы!