КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Однофакторный дисперсионный анализ. Рассмотрим действие на выходной параметр системы Y только одного входного фактора Х, который принимает m различных значений (постоянных уровней)
|
|
|
|
Рассмотрим действие на выходной параметр системы Y только одного входного фактора Х, который принимает m различных значений (постоянных уровней). Так как, в общем случае генеральная дисперсия наблюдений 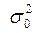 нам не известна, то для вычисления оценки нужно обязательно иметь дублирующие (параллельные) наблюдения. Здесь можно поступить по-разному: можно на первом же уровне x1, привести достаточно много наблюдений, вычислить оценку дисперсии и использовать ее для изучения других уровней. Лучше, однако, повторять наблюдения на всех уровнях, так как при этом появляется дополнительная возможность контроля за неизменностью дисперсии
нам не известна, то для вычисления оценки нужно обязательно иметь дублирующие (параллельные) наблюдения. Здесь можно поступить по-разному: можно на первом же уровне x1, привести достаточно много наблюдений, вычислить оценку дисперсии и использовать ее для изучения других уровней. Лучше, однако, повторять наблюдения на всех уровнях, так как при этом появляется дополнительная возможность контроля за неизменностью дисперсии 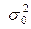 . Наиболее простые расчеты получаются в случае, когда на каждом уровне фактора xi производится одинаковое число наблюдений n1=n2=…=ni=…=nm=n. Результаты наблюдений обычно оформляют в виде следующей таблицы.
. Наиболее простые расчеты получаются в случае, когда на каждом уровне фактора xi производится одинаковое число наблюдений n1=n2=…=ni=…=nm=n. Результаты наблюдений обычно оформляют в виде следующей таблицы.
Таблица 4.1 – Исходные данные для ДА с равным числом повторений опытов
| Номер опыта | Уровни фактора Х | |||||
| x 1 | x 2 | … | x i | … | x m | |
| … j … n | y 11 y 21 … y j1 … y n1 | y 12 y 22 … y j2 … y n2 | … … … … … … | y 1i y 2i … y ji … y ni | … … … … … … | y 1m y 2m … y jm … y nm |
| Групповые средние | 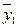
| 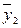
| … | 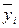
| … | 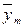
|
В таблице 4.1 обозначено:
j= 1 ,n – число опытов на каждом уровне фактора х;
i= 1 ,m – число уровней фактора х.
В последней строке таблице 4.1 записаны средние арифметические значения полученных наблюдений выходного параметра Y для каждого из уровней фактора Х:
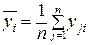 , (4.6)
, (4.6)
где уji – j -е значение выходного параметра у на i – м уровне.
Пусть результаты измерений выходного параметра у ji распределены по нормальному закону, имеют одинаковую, хотя и неизвестную дисперсию
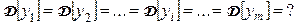
Требуется при заданном уровне значимости 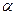 по выборочным средним (оценкам математического ожидания) проверить нулевую гипотезу о равенстве всех математических ожиданий:
по выборочным средним (оценкам математического ожидания) проверить нулевую гипотезу о равенстве всех математических ожиданий:
|
|
|
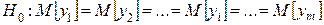 .
.
Будем полагать, что для i-го уровня n наблюдений имеют среднюю 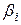 , которая равна сумме общей средней
, которая равна сумме общей средней 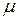 и вариации ее, обусловленной i -м уровнем фактора х, то есть
и вариации ее, обусловленной i -м уровнем фактора х, то есть
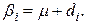 (4.7)
(4.7)
В рассматриваемых условиях любое наблюдение из таблицы 4.1 может быть представлено в виде следующей модели:
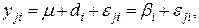 (4.8)
(4.8)
где – средняя для i-го уровня фактора х;
– генеральное среднее результатов наблюдений или общая средняя (математическое ожидание для среднего во всей таблица 4.1);
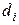 – эффект фактора х на i-м уровне (отклонение математического ожидания выходного параметра при i-м уровне фактора от общего математического ожидания );
– эффект фактора х на i-м уровне (отклонение математического ожидания выходного параметра при i-м уровне фактора от общего математического ожидания );
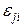 – вариация результатов внутри отдельного уровня (случайный остаток, характеризующий влияние на
– вариация результатов внутри отдельного уровня (случайный остаток, характеризующий влияние на 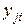 всех неучтенных моделью (4.8) факторов).
всех неучтенных моделью (4.8) факторов).
Согласно общей идее ДА разложим оценку дисперсии выходного параметра  на составляющие, которые характеризовали бы вклад фактора х и фактора случайности:
на составляющие, которые характеризовали бы вклад фактора х и фактора случайности:
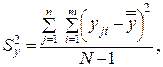 (4.9)
(4.9)
где N – общее число опытов;
N=n1=n2=…=ni=…=nm=mn;
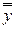 – общая средняя для всей выборки;
– общая средняя для всей выборки;
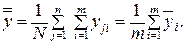
При расположении наблюдений так, как показано в таблице 4.1, их рассеяние между строками обуславливается ошибкой воспроизводимости эксперимента, а рассеяние между столбцами – дополнительным действием исследуемого фактора х. Рассеяние отдельных наблюдений относительно общего среднего обусловлено действием, как случайных причин, так и влиянием фактора х. Действие фактора случайности проявляется в рассеянии (с дисперсией 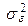 ) наблюдений серий параллельных опытов на каждом уровне xi вокруг среднего арифметического
) наблюдений серий параллельных опытов на каждом уровне xi вокруг среднего арифметического 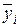 своей серии. Влияние же фактора х (с дисперсией
своей серии. Влияние же фактора х (с дисперсией 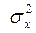 ) вызывает повышенное рассеяние средних арифметических серий относительно общего среднего . Каждое их этих трех рассеяний можно охарактеризовать соответствующей суммой квадратов отклонений.
) вызывает повышенное рассеяние средних арифметических серий относительно общего среднего . Каждое их этих трех рассеяний можно охарактеризовать соответствующей суммой квадратов отклонений.
|
|
|
С этой целью преобразуем общую сумму квадратов отклонений наблюдений от общего среднего (числитель (4.9)) к следующему виду:
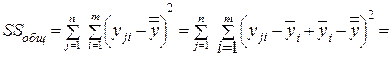
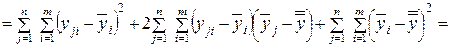 (4.10)
(4.10)
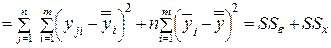 .
.
Вследствие того, что
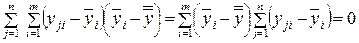 ,
,
поскольку
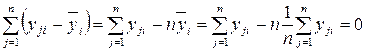 .
.
Суммы 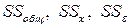 , входящие в выражение (4.10), означают следующее:
, входящие в выражение (4.10), означают следующее:
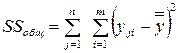 ; (4.11)
; (4.11)
– это общая сумма квадратов отклонений отдельных наблюдений 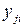 от общего среднего
от общего среднего 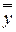 . Она характеризует рассеяние наблюдений в результате действия, как фактора случайности
. Она характеризует рассеяние наблюдений в результате действия, как фактора случайности 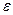 , так и исследуемого входного фактора х;
, так и исследуемого входного фактора х;
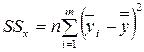 ; (4.12)
; (4.12)
– это сумма квадратов отклонений между средними по уровням  и общей средней . Сумма SS x/n рассеяние средних
и общей средней . Сумма SS x/n рассеяние средних 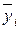 уровней за счет случайных причин (с дисперсией
уровней за счет случайных причин (с дисперсией 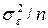 для средних уровней) и исследуемого входного фактора х (с дисперсией
для средних уровней) и исследуемого входного фактора х (с дисперсией 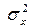 );
);
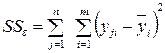 ; (4.13)
; (4.13)
– это сумма квадратов отклонений внутри уровней, то есть сумма квадратов разностей между отдельными наблюдениями и средним соответствующего уровня. Она характеризует остаточное рассеяние случайных погрешностей опытов, то есть их воспроизводимость.
Таким образом, общую сумму квадратов отклонений наблюдаемых значений выходного параметра от общей средней мы разложили на две составляющие: 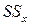 – факторную сумму квадратов отклонений и
– факторную сумму квадратов отклонений и 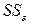 – остаточную сумму квадратов отклонений.
– остаточную сумму квадратов отклонений.
Зная суммы квадратов 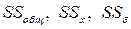 , можно определить соответствующие оценки дисперсий: общую, межуровневую и внутриуровневую
, можно определить соответствующие оценки дисперсий: общую, межуровневую и внутриуровневую 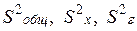 :
:
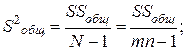 (4.14)
(4.14)
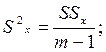 (4.15)
(4.15)
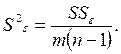 (4.16)
(4.16)
Оценки  в литературе достаточно часто называют факторной и остаточной дисперсиями.
в литературе достаточно часто называют факторной и остаточной дисперсиями.
Математически строго можно показать, что если влияние входного исследуемого фактора х на выходной параметр Y несущественно, то полученные нами дисперсии (4.14)-(4.16) являются несмещенными оценками генеральной дисперсии наблюдений , то есть:
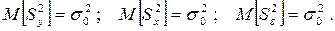 (4.17)
(4.17)
Следовательно, для выяснения влияния фактора Х на выходной параметр Y необходимо сравнить дисперсии . Для того, чтобы влияние фактора было признано значимым, необходимо и достаточно, чтобы оценка дисперсии 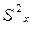 значимо отличалась от
значимо отличалась от 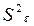 . Проверку нуль-гипотезы об однородности этих оценок можно осуществить по критерию Фишера:
. Проверку нуль-гипотезы об однородности этих оценок можно осуществить по критерию Фишера:
|
|
|
 . (4.18)
. (4.18)
Если вычисленное по результатам наблюдений дисперсионное отношение Fрасч превосходит критическое табличное 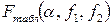 , найденное по распределению Фишера для выбранного уровня значимости
, найденное по распределению Фишера для выбранного уровня значимости  и степеней свободы
и степеней свободы 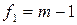 числителя и
числителя и 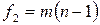 знаменателя (2.18),
знаменателя (2.18),
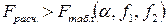 , (4.19)
, (4.19)
то влияние фактора Х следует признать значимым. Если условие (4.19) не выполняется, то есть
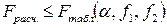 , (4.20)
, (4.20)
то влияние фактора Х следует признать незначимым. Так как в рассматриваемых условиях проверяется нулевая гипотеза
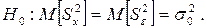
при конкурирующей гипотезе вида
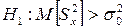 ,
,
то при расчетах следует пользоваться односторонним F -критерием (приложение Б).
Таким образом, если выполняется условие (4.19), то дисперсии значимо отличаются друг от друга, нулевая гипотеза равенства средних
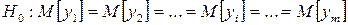
должна быть отвергнута и влияние фактора Х признано значимым. В этих условиях по результатам наблюдений (смотреть таблицу 4.1) можно оценить:
– дисперсию воспроизводимости 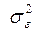 - выборочной остаточной дисперсией
- выборочной остаточной дисперсией
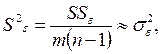
то есть
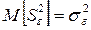 (4.21)
(4.21)
и определить доверительный интервал для по х2 -распределению с m(n- 1 ) степенями свободы;
– дисперсию исследуемого фактора Х по формуле
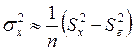 , (4.22)
, (4.22)
– расхождение 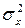 генеральных центров серий, обусловленное влиянием фактора Х. Так как
генеральных центров серий, обусловленное влиянием фактора Х. Так как
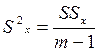 ,
,
то можно показать, что
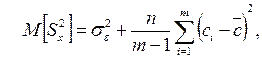
где 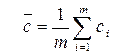 – среднее значение из генеральных центров распределения сi,
– среднее значение из генеральных центров распределения сi,
или
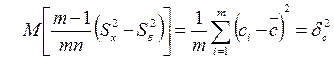 .
.
Оценкой величины 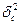 служит выборочная характеристика
служит выборочная характеристика
 (4.23)
(4.23)
– расхождение 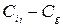 между генеральными центрами любых двух серий.
между генеральными центрами любых двух серий.
Так как статистика
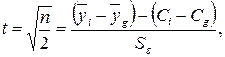 (4.24)
(4.24)
следует распределению Стьюдента с числом степеней свободы 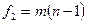 , то интервал
, то интервал
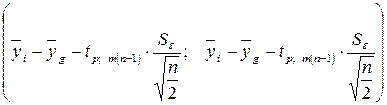 (4.25)
(4.25)
служит доверительным (1 -р)100 % интервалом для 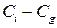 ;
;
– сравнение всех средних при помощи множественного рангового критерия Дункана, попарное сравнение по t -критерию и другие.
При интерпретации результатов ДА необходимо иметь в виду, что очень низкое значение дисперсионного отношения может быть связано с тем, что влияние какого-то важного неконтролируемого в ходе эксперимента не было рандомизировано.
|
|
|
Это может увеличить дисперсию внутри уровней, а дисперсию между уровнями оставить неизменной, что уменьшает дисперсионное отношение. В данном случае результаты проведенных экспериментов уже не будут подчиняться модели (4.8).
При интерпретации результатов ДА для математической модели со случайными уровнями факторов обычно интересуются не проверкой гипотез относительно средних, а оценкой компонент дисперсий. В отличие от модели с фиксированными уровнями выводы по случайной модели распространяются на генеральную совокупность уровней.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 919; Нарушение авторских прав?; Мы поможем в написании вашей работы!