КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Т Е Х Н О Л О Г І Ї 3 страница
|
|
|
|
Код програми 23.1. Демонстрація механізму використання "функціональних" макровизначень
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define MIN(а, b) (((a)<(b))? а: b)
int main ()
{
int x, y;
x = 10; y = 20;
cout << "Мінімум дорівнює: " << MIN(x, y);
getch (); return 0;
}
У процесі компілювання цієї програми вираз, визначено ідентифікатором MIN(а, b), буде замінено, але х і у розглядатимуться як операнди. Це означає, що з out -настанова після компілювання виглядатиме так:
cout << "Мінімум дорівнює: " << (((х)<(у))? х: у);
По суті, таке макровизначення є способом визначити функцію, яка замість виклику дає змогу розкрити свій код у рядку.
Макровизначення, що діють як функції, – це макровизначення, які приймають аргументи. Круглі дужки, що здаються надмірними, в які поміщено макровизначення MIN, необхідні, щоб гарантувати правильне сприйняття компілятором замінюваного виразу. Насправді додаткові круглі дужки повинні застосовуватися практично до всіх макровизначень, що діють подібно до функцій. Потрібно завжди дуже уважно відноситися до визначення таких макросів; інакше можливо отримання несподіваних результатів. Розглянемо, наприклад, цю коротку програму, яка використовує макрос для визначення парності значення.
Код програми 23.2. Демонстрація неправильної роботи програми
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define EVEN(a) a%2==0? 1: 0
int main ()
{
if (EVEN(9 + 1)) cout << "парне число";
else cout << "непарне число ";
getch (); return 0;
}
Ця програма не працюватиме коректно, оскільки не забезпечена правильна підстановка значень. У процесі компілювання вираз EVEN(9 + 1) буде замінений таким чином.
|
|
|
9+1 %2==0? 1: 0
Нагадаю, що оператор "%" має вищий пріоритет, ніж оператор додавання "+". Це означає, що спочатку виконається операція ділення за модулем (%) для числа 1, а потім її результат буде складний з числом 9, що (звичайно ж) не рівно 0. Щоб виправити помилку, достатньо помістити у круглі дужки аргумент, а в макровизначенні EVEN, як це показано в наступній (виправленій) версії тієї ж самої програми.
Код програми 23.3. Демонстрація коректної роботи програми
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define EVEN(a) (a)%2==0? 1: 0
int main ()
{
if (EVEN(9 + 1)) cout << "парне число";
else cout << "непарне число";
getch (); return 0;
}
Тепер сума 9+1 обчислюється до виконання операції ділення за модулем. У загальному випадку краще завжди брати параметри макровизначення у круглі дужки, щоб уникнути непередбачених результатів, подібних описаному вище.
Використання макровизначень замість справжніх функцій має одну істотну перевага: оскільки програмний код макровизначення розширюється в рядку, і немає ніяких витрат системних ресурсів на виклик функції, швидкість роботи Вашої програми буде вища порівняно із застосуванням звичайної функції. Але підвищення швидкості є платнею за збільшення розміру програми (через дублювання коду функції).
Необхідно пам'ятати! Незважаючи на те, що макровизначення все ще трапляється у С++-коді програми, макросах, що діють подібно до функцій, можна замінити специфікатором inline, який справляється з тією ж роллю краще і безпечніше. (Пригадайте: специфікатор inline забезпечує замість виклику функції розширення її тіла в рядку). Окрім того, inline -функції не вимагають додаткових круглих дужок, без яких не можуть обійтися макровизначення. Проте макроси, що діють подібно до функцій, все ще залишаються частиною С++-програм, оскільки багато С/С++-програмісти продовжують використовувати їх за звичкою.
|
|
|
23.1.2. Директива #error
Директива #error відображає повідомлення про помилку.
Директива #error дає вказівку компіляторові зупинити компіляцію. Вона використовується в основному для відлагодження. Загальний формат її запису є таким:
terror повідомлення
Звернемо Вашу увагу на те, що елемент повідомлення не поміщений у подвійні лапки. При зустрічі з директивою terror відображається задане повідомлення і інша інформація (вона залежить від конкретної реалізації робочого середовища), після чого компілювання припиняється. Щоб дізнатися, яку інформацію відображає у цьому випадку компілятор, достатньо провести експеримент.
23.1.3. Директива #include
Директива #include містить заголовок або інший початковий файл.
Директива препроцесора #include зобов'язує компілятор включити або стандартний заголовок, або інший початковий файл, ім'я якого вказане у директиві #include. Ім'я стандартних заголовків береться у кутові дужки, як це показано у прикладах, наведених у цьому навчальному посібнику. Наприклад, ця директива
#include <vector> // Для роботи контейнерним класом "Вектор"
містить стандартний заголовок для векторів.
При включенні іншого початкового файлу його ім'я може бути вказано у подвійних лапках або кутових дужках. Наприклад, наступні дві директиви зобов'язують C++ прочитати і скомпілювати файл з іменем strClass.h:
#include <strClass.h>
#include "strClass.h"
Якщо ім'я файлу поміщене у кутові дужки, то пошук файлу здійснюватиметься в одному або декількох спеціальних каталогах, визначених конкретною реалізацією.
Якщо ж ім'я файлу поміщене в лапки, пошук файлу виконується, як правило, у поточному каталозі (що також визначено конкретною реалізацією). У багатьох випадках це означає пошук поточного робітника каталога. Якщо заданий файл не знайдений, пошук повторюється з використанням першого способу (неначебто ім'я файлу було поміщено у кутові дужки). Щоб ознайомитися з подробицями, пов'язаними з різною обробкою директиви #include у разі використання кутових дужок і подвійних лапок, зверніться до керівництва користувача, що додається до Вашого компілятора. Настанови #include можуть бути вкладеними в інші файли, що містяться.
|
|
|
23.2. Директиви умовного компілювання
Існують директиви, які дають змогу вибірково компілювати частини початкового коду програми. Цей процес, що іменується умовною компіляцією, широко використовується комерційними фірмами по розробленню програмного забезпечення, які створюють і підтримують багато різних версій однієї програми.
23.2.1. Директиви #if, #else, #elif і #endif
Директиви # if, #ifdef, #ifndef, # else, #elif і #endif – це директиви умовного компілювання.
Головна ідея полягає у тому, що коли вираз, що знаходиться після директиви # if виявляється істинним, то буде скомпільований програмний код, розташований між нею і директивою #endif; інакше даний програмний код буде опущений. Директива #endif використовують для позначення кінця блоку # if.
Загальна форма запису директиви # if має такий вигляд:
# if константний_вираз
послідовність настанов
Якщо константний_вираз є істинним, програмний код, розташований безпосередньо за цією директивою, буде скомпільований. Розглянемо такий приклад.
Код програми 23.4. Демонстрація простого прикладу використання директиви #if
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define MAX 100
int main ()
{
# if MAX>10
cout << "Потрібний додаткова память\n";
//...
getch (); return 0;
}
У процесі виконання ця програма відобразить повідомлення Потрібна додаткова пам'ять на екрані, оскільки, як визначено у програмі, значення константи МАХ більше 10. Цей приклад ілюструє важливий момент: Вираз, який знаходиться після директиви # if, обчислюється під час компілювання. Отже, воно повинно містити тільки ідентифікатори, які були заздалегідь визначені, або константи. Використання ж змінних тут виключене.
Поведінка директиви #else багато в чому подібно до поведінки настанови else, яка є частиною мови програмування C++: вона визначає альтернативу на випадок невиконання директиви # if. Щоб показати, як працює директива #else, скористаємося попереднім прикладом, небагато його розширивши.
Код програми 23.5. Демонстрація механізму використання директив #if і #else
|
|
|
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define MAX 6
int main ()
{
# if MAX>10
cout << "Потрібна додаткова пам'ять.\n");
# else
cout << "Достатньо набезпосередньої пам'яті.\n";
//...
getch (); return 0;
}
У цій програмі для імені МАХ визначено значення, яке 10, тому #if -гілка коду програми не скомпілюється, та зате скомпілюється альтернативна # else -гілка. В результаті відобразиться повідомлення Достатньо набезпосередньої пам'яті.
Звернемо Вашу увагу на те, що директива # else використовують для індикації одночасно як кінця # if -блока, так і початку #еlse-блоку. У цьому є логічна необхідність, оскільки тільки одна директива #endif може бути пов'язана з директивою # if.
Директива #elif еквівалентна зв'язці настанов else - if і використовують для формування багатоланкової схеми if - else - if, представляючої декілька варіантів компілювання. Після директиви #elif повинен знаходитися константний вираз. Якщо цей вираз істинний, наступний блок коду програми скомпілюється, і ніякі інші ttelif-вирази не тестуватимуться або не компілюватимуться. Інакше буде перевірено наступне по черзі
#elif -вираз. Ось як виглядає загальний формат використання директиви
#elif.
# if вираз
послідовність настанов
#elif вираз 1
послідовність настанов
#elif вираз 2
послідовність настанов
#elif вираз 3
послідовність настанов
//...
#elif вираз N
послідовність настанов
Наприклад, цей фрагмент коду програми використовується ідентифікатор COMPILED_BY, який дає змогу визначити, ким компілюється програма.
#define JOHN Про #define B_OBJ 1 #define ТОМУ 2
#define COMPILED_BY JOHN
# if COMPILED_BY == JOHN
char who[] = "John"; ttelif COMPILED_BY == B_OBJ
char who[] = "B_ob";
# else
char who[] = "Tom";
Директиви # if і #elif можуть бути вкладеними. У цьому випадку директива #endif, # else або #elif зв'язується з найближчою директивою #if або #elif. Наприклад, такий фрагмент коду програми є абсолютно допустимим.
# if COMPILED_BY == B_OBJ # if DEBUG == FULL int port = 198;
#elif DEBUG == PARTIAL
int port = 200;
# else
cout << "Боб повинен скомпілювати код"
<< "для відлагодження виведення даних.\n";
23.2.2. Директиви #ifdef і #ifndef
Директиви #ifdef і #ifndef пропонують ще два варіанти умовного компілювання, які можна виразити як "якщо визначено" і "якщо не визначено" відповідно. Загальний формат використання директиви #ifdef такий.
#ifdef макроім'я
послідовність настанов
Якщо макроім'я попереднє визначено за допомогою якої-небудь директиви #define, то послідовність настанов, розташована між директивами #ifdef і #endif, буде скомпільована.
Загальний формат використання директиви #ifndef такий.
#ifndef макроім'я
послідовність настанов
Якщо макроім'я не визначене за допомогою якої-небудь директиви #define, то послідовність настанов, розташована між директивами #ifdef і #endif, буде скомпільована.
Як директива #ifdef, так і директива #ifndef може мати директиву # else або #elif. Розглянемо такий приклад.
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define TOM
int main ()
{
#ifdef TOM
cout << "Програміст Том.\n";
# else
cout << "Програміст невідомий.\n";
#ifndef RALPH
cout << "Ім'я RALPH не визначене.\n";
getch (); return 0;
}
У процесі виконання ця програма відображає наступне.
Програміст Тому.
Ім'я RALPH не визначене.
Але якби ідентифікатор ТОМУ був не визначено, то результат виконання цієї програми виглядав би так.
Програміст невідомий. Ім'я RALPH не визначене.
Необхідно пам'ятати! Директиви #ifdef і #ifndef можна вкладати так само, як і директиви # if.
23.2.3. Директива #undef
Директива #undef використовують для видалення попереднього визначення деякого макроімені. Її загальний формат такий.
#undef макроім'я
Розглянемо такий приклад:
#define TIMEOUT 100 Sdefine WAIT 0
//...
#undef TIMEOUT
#undef WAIT
У цих записах імена TIMEOUT і WAIT визначені доти, доки не виконається директива #undef.
Основне призначення директиви #undef дати змогу локалізацію макроімен для тих частин коду програми, в яких вони потрібні.
23.2.4. Використання оператора defined
Крім директиви #ifdef існує ще один спосіб з'ясувати, чи визначене у програмі деяке макроім'я. Для цього можна використовувати директиву # if у поєднанні з оператором часу компілювання defined. Наприклад, щоб дізнатися, чи визначено макроім'я MYFILE, можна використовувати одну з наступних команд препроцесорного оброблення.
#ifdefined MYFILE АБО
#ifdef MYFILE
У разі потреби, щоб реверсувати умову перевірки, можна передувати оператору defined символом "!". Наприклад, такий фрагмент коду програми скомпілюється тільки у тому випадку, якщо макроім'я DEBUG не визначене:
# if!defined DEBUG
cout << "Остаточна версія!\n";
23.2.5. Про значення препроцесора
Препроцесор C++ прямий нащадок препроцесора мови C, до того ж без жодних удосконалень. Проте його значення у мові програмування C++ набагато менше від ролі, яку відіграє препроцесор в C. Йдеться про те, що багато завдань, що виконуються препроцесором в C, реалізовані C++ у вигляді елементів мови. Страуструп тим самим виразив свій намір зробити функції препроцесора непотрібними, щоб врешті-решт від нього можна було б зовсім звільнити мову.
На даному етапі препроцесор вже частково надмірний. Наприклад, дві найбільш споживані властивості директиви #define були замінені настановами C++. Зокрема, її здатність створювати константне значення і визначати макровизначення, що діє подібно до функцій, зараз абсолютно надмірна. У мові програмування C++ є ефективніші засоби для виконання цих завдань. Для створення константи достатньо визначити const -змінну. А із створенням вбудовуваної (що підставляється) функції цілком справляється специфікатор inline. Обидва ці засоби краще працюють, ніж відповідні механізми директиви #define.
Наведемо ще один приклад заміни елементів препроцесора елементами мови. Він пов'язаний з використанням однорядкового коментарю. Одна з причин його створення дати змогу "перетворення" коду програми у коментар. Як уже зазначалося вище, коментар, що використовує /*.*/-стиль, не може бути вкладеним. Це означає, що фрагменти коду програми, що містять /*.*/-коментарі, одним махом "перетворити на коментар" не можна. Але це можна зробити з //-коментарями, оточивши їх /*.*/-символами коментарю. Можливість "перетворення" коду програми у коментар робить використання таких директив умовного компілювання, як #ifdef, частково надмірним.
23.2.6. Директива #line
Директива #line змінює вміст псевдозмінн __LINE__ і __FILE__.
Директива #line використовують для зміни вмісту псевдозмінних __LINE__ і __FILE__, які є зарезервованими ідентифікаторами (макроіменами). Псевдозмінна __LINE__містить номер скомпільованого рядка, а псевдозмінна __FILE__ – ім'я компільованого файлу. Базова форма запису цієї команди має такий вигляд:
#line номер "ім'я_файлу"
У цьому записі номер – це будь-яке позитивне ціле число, а ім'я_файлу будь-який допустимий ідентифікатор файлу. Значення елемента номер стає номером поточного початкового рядка, а значення елемента ім'я_файлу ім'ям початкового файлу. Ім'я файлу – елемент необов'язковий. Директива #line використовується, в основному, з метою відлагодження і у спеціальних додатках.
Наприклад, наведений нижче код програми зобов'язує починати рахунок рядків з числа 200. Настанова cout відображає номер 202, оскільки це третій рядок у програмі після директивної настанови #line 200.
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#line 200 // Встановлюємо лічильник рядків, що дорівнює 200.
int main () // Цей рядок зараз має номер 200.
{ // Номер цього рядка дорівнює 201.
cout << __LINE__ _; // Тут виводиться номер 202.
getch (); return 0;
}
23.2.7. Директива #pragma
Директива #pragma залежить від конкретної реалізації компілятора.
Робота директиви #pragma залежить від конкретної реалізації компілятора. Вона дає змогу видавати компіляторові різні настанови, передбачені творцем компілятора. Загальний формат його використання такий.
#pragma ім'я
У цьому записі елемент ім'я представляє ім'я бажаної #pragma-настанови. Якщо вказане ім'я не розпізнається компілятором, директива #pragma просто ігнорується без повідомлення про помилку.
Необхідно пам'ятати! Для отримання докладної інформації про можливі варіанти використання директиви #pragma варто звернутися до системної документації з використовуваного Вами компіляторові. Ви можете знайти для себе дуже корисну інформацію. Звичайно #pragma-настанови дають змогу визначити, які застережливі повідомлення видає компілятор, як генерується програмний код і які бібліотеки компонуються з вашими програмами.
23.3. Оператори препроцесора "#" і "##"
У мові програмування C++ передбачена підтримка двох операторів препроцесора: "#" і "##". Ці оператори використовують спільно з директивою #define. Оператор "#" перетворить наступний за ним аргумент у рядок, поміщений у лапки. Розглянемо, наприклад, таку програму:
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define mkstr(s) # s
int main ()
{
cout << mkstr(Я у захопленні від C++);
getch (); return 0;
}
Препроцесор C++ перетворить рядок
cout << mkstr(I like C++);
у рядок
cout << " Я у захопленні від C++";
Оператор "##" використовують для конкатенації двох лексем. Розглянемо такий приклад:
#include <iostream> // Для потокового введення-виведення
using namespace std; // Використання стандартного простору імен
#define concat(а, b) а ## b
int main ()
{
int xy = 10;
cout << concat(x, y);
getch (); return 0;
}
Препроцесор перетворить рядок
cout << concat(x, y);
у рядок
cout << xy;
Якщо ці оператори Вам здаються дивними, потрібно пам'ятати, що вони не є операторами "повсякденного попиту" і рідко використовуються у програмах. Їх основне призначення дати змогу препроцесору обробляти деякі спеціальні ситуації.
23.4. Зарезервовані макроімена
У мові C++ визначено шість вбудованих макроімен.
__ _LINE__ _
__ _ FILE __ _
__ _DATE__ _
__ _TIME__ _
__ _STDC__ _
__cplusplus
Розглянемо кожне з них окремо.
Макроси __LINE__ і __FILE__ описані під час розгляду директиви #line вище у цьому розділі. Вони містять номер поточного рядка і ім'я файлу компільованої програми.
Макрос __DATE__представляє собою рядок у форматі місяць/день/рік, який означає дату трансляції початкового файлу в об'єктний код.
Час трансляції початкового файлу в об'єктний код міститься у вигляді рядка в макросі __TIME__. Формат цього рядка наступний: години.хвилини.секунди.
Точне призначення макросу __STDC__залежить від конкретної реалізації компілятора. Як правило, якщо макрос__STDC__визначено, то компілятор прикмет тільки стандартний С/С++-код, який не містить ніяких нестандартних розширень.
Компілятор, що відповідає ANSI/ISO-стандарту мови програмування C++, визначає макрос __cplusplus як значення, що містить принаймні шість цифр. "Нестандартні" компілятори повинні використовувати значення, що містить п'ять (або навіть менше) цифр.
23.5. Деякі поради студентам
Ми подолали чималий шлях: завдовжки в цілу книгу. Якщо Ви уважно вивчили всі наведені тут приклади, то можете сміливо назвати себе програмістом мовою C++. Подібно до багатьох інших наук, процес програмування краще за все освоювати на практиці, тому тепер Вам потрібно писати більше програм. Корисно також розібратися у С++-програмах, написаних іншими (причому різними) професійними програмістами. При цьому важливо звертати увагу на те, як програма оформлена і реалізована. Постарайтеся знайти в них як переваги, так і недоліки. Це розширить діапазон Ваших уявлень про програмування. Подумайте також над тим, як можна поліпшити наявний код будь-якої програми, застосувавши контейнери і алгоритми бібліотеки STL. Ці засоби, як правило, дають змогу поліпшити читабельність і підтримку великих програм. Нарешті, просто більше експериментуйте! Дайте волю своїй фантазії і незабаром Ви відчуєте себе сьогоденням С++-програмістом!
Для продовження теоретичного засвоєння C++ пропоную звернутися до книги Герберта Шілдта " Полный справочник по C++" [27]. Вона містить детальний опис елементів мови програмування C++ і бібліотек.

Розділ 24. Формалізація процесу розроблення об'єктно-орієнтованого програмного забезпечення|
Приклади кодів програм, які було наведено в цьому навчальному посібнику, настільки малі за об'ємом, що не вимагають якої-небудь формалізації процесу їх розроблення. Проте ситуація різко міняється, коли ми маємо справу із справжньою, масштабною програмою, над створенням якої трудяться десятки або сотні програмістів і в якій містяться мільйони рядків початкового коду програми. У таких випадках дуже важливо чітко слідувати певній концепції розроблення ПЗ. У цьому розділі ми достатньо стисло розглянемо приклад процесу розроблення програми, а потім продемонструємо, як цю технологію застосовують до справжніх програм.
У цьому навчальному посібнику трапляється множина прикладів діаграм UML. Проте UML призначено не для створення програми; це всього тільки мова візуального моделювання її структури. Але UML, як ми побачимо далі, може мати ключове значення в процесі роботи над крупним проектом.
24.1. Удосконалення процесу розроблення програмного забезпечення
Ідея формалізації процесу розроблення ПЗ розвивалася протягом десятиліть. У цьому навчальному посібнику спробуємо тільки стисло розглянути основні віхи історії.
24.1.1. Безпосередній процес розроблення ПЗ
Ще на початку удосконалення обчислювальної техніки ніяких формальностей процесу розроблення ПЗ не було. Здебільшого програміст обговорював фізичний зміст технічного завдання з конкретним замовником чи потенційними користувачами і відразу ж брався писати код програми. Це було, втім, цілком прийнятно навіть для великих, як на той час, програм.
24.1.2. Каскадний процес розроблення ПЗ
Коли програмісти стали більш кваліфікованими фахівцями, то вони почали ділити процес розроблення ПЗ на декілька етапів, що мали б виконуватися послідовно. Ця ідея насправді була запозичена з виробничих процесів. Етапи були такі: аналіз, планування, кодування і впровадження. Така послідовність часто називалася каскадною моделлю, оскільки процес завжди йшов у одному напрямку від аналізу до впровадження, як показано на рис. 24.1. Для реалізації кожного з етапів стали залучатися окремі групи програмістів, і кожна з них передавала результати своєї праці наступній.
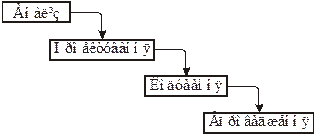
Рис. 24.1. Каскадна модель розроблення ПЗ
Набутий досвід показав, що каскадна модель має множина недоліків. Адже малося на увазі, що кожний з етапів виконується без помилок або з мінімальною їх кількістю. Так, зазвичай, майже не буває в повсякденній роботі програмістів. Кожна етап привносила свої помилки, їх кількість від етапу до етапу наростала, як снігова лавина, роблячи всю програму однією великою помилкою.
До того ж у процесі розроблення ПЗ замовник міг змінити свої вимоги, а після закінчення етапу планування вже складно було знову повернутися до нього. Виявлялося у підсумку, що до моменту завершення написання програма вже просто застарівала.
24.1.3. Використання ООП
Як вже було сказано в розд. 11, саме по собі ООП створювалося для вирішення деяких проблем, що є притаманними процесу удосконалення методики розроблення великих програм. Зрозуміло, процес планування під час використання ООП різко спрощується, оскільки об'єкти програми відповідають об'єктам реального світу.
Але саме по собі ООП не вказує нам, що повинна робити програма; воно придатне тільки після того, як визначено мету і завдання проекту. Початковою, як і завжди, є етап "ініціалізації", коли потрібно з'ясувати вимоги замовника і чітко уявити собі потреби потенційних користувачів. Тільки після цього можна починати планування об'єктно-орієнтованої програми. Але як же нам зробити цей перший крок?
24.1.4. Сучасні підходи до розроблення ПЗ
За останні роки з'явилося множина нових концепцій розроблення ПЗ. Вони визначають певну послідовність дій і способи взаємодії замовників, постановників завдань, розробників і програмістів. На сьогодні жодна мова моделювання не володіє тією універсальністю, яка є властивою UML. Багато експертів дотепер не можуть повірити, що один і той же підхід до розроблення ПЗ може бути застосований до створення проектів будь-яких видів. Навіть коли вже вибраний якийсь процес, то може з часом знадобитися, залежно від застосування програми, достатньо серйозно його змінити. Як приклад сучасної методики розроблення ПЗ розглянемо основні ознаки підходу, якому ми дамо назву уніфікований процес.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 402; Нарушение авторских прав?; Мы поможем в написании вашей работы!