КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Представление данных для графического процессора
Используемый графический процессор
Здесь мы рассматриваем программирование графических процессоров, поддерживающих шейдеры модели 3.0. Эти процессоры имеют по два набора параллельных конвейеров, предназначенных для проведения двух расчётов (обработки двух наборов данных). Такая архитектура обусловлена тем, что графические процессоры предназначены для использования на видеокартах и, соответственно, для вывода сложных изображений на экран. При формировании изображения первая группа процессоров – вершинные конвейеры - рассчитывает координаты вершин примитивов (обычно – треугольников), из которых состоит изображение, а вторая группа – пиксельные конвейеры – наносит на эти примитивы текстуру (определяет цвета).
Для проведения физических расчётов достаточно использования процессоров только одного типа. В физическом моделировании мы использовали пиксельные конвейеры, поскольку их больше, чем вершинных.
Характеристики некоторых конкретных графических процессоров приведёны в табл. 4.2. Бóльшая часть расчётов проведена нами на процессоре Radeon X1900 XT, который имеет 48 суперскалярных (4-векторных) пиксельных конвейеров. Наш опыт показал, что при МД-расчётах этот графический процессор обгоняет одноядерный (но тоже суперскалярный) CPU (AMD Athlon64 2100 МГц) более чем в 100 раз, несмотря на более низкую частоту. Настолько большое приращение обусловлено не только большим количеством конвейеров, но и тем, что в GPU оптимизировано взаимодействие с памятью при проведении поточных вычислений.
Центральные процессоры персональных компьютеров в большинстве случаев обрабатывают данные последовательно. Поэтому естественно то, что данные в оперативной памяти компьютера представлены в форме одномерных массивов: адрес каждой ячейки памяти представляется одним шестнадцатеричным числом, а последовательным ячейкам памяти соответствуют последовательные адреса. Даже если объектами моделирования являются многомерные структуры данных, такие как матрицы:
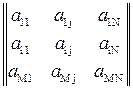 ,
,
фактически их элементы всё равно хранятся и обрабатываются как одномерные последовательности:
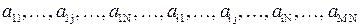 .
.
В отличие от CPU, графические процессоры изначально предназначены для параллельной обработки данных, поэтому для них естественно обращаться к памяти, где данные хранятся в форме двумерных массивов и адресуются двумя координатами. Именно так устроена видеопамять, размещаемая на видеокартах (рис. 5.2). Данные в видеопамять записывает центральный процессор, с помощью драйвера видеокарты, который копирует эти данные из оперативной памяти компьютера. Для представления данных в необходимой для копирования форме можно применять стандартные процедуры библиотек DirectX и OpenGL.
Ещё одно отличие графических процессоров от CPU состоит в том, что при их программировании для адресации элементов массивов (т.е., в качестве номеров элементов) используются не целые числа, а числа с плавающей точкой, которые при обработке графики напрямую задавали бы координаты закрашиваемых областей на экране (рис. 5.2).
Перед началом исполнения шейдера в ячейки видеопамяти (рис. 5.2) должны быть записаны исходные данные (здесь – элементы матриц). Затем с помощью драйвера видеокарты центральный процессор запускает расчёт. В ходе расчёта графический процессор последовательно извлекает эти данные из видеопамяти и применяет ко всем элементам один и тот же набор операций, заданный программой (например, рассчитывает сумму c ij = a ij+ b ij). Результаты расчёта (в примере - значения c ij) GPU записывает в область видеопамяти, называемую рендер-целью.
Как уже отмечено выше, исходные данные хранятся в виде двумерных массивов, и рендер-цель тоже представляет собой двумерный массив тех же размеров. В рассматриваемом примере с матрицами содержимым ячеек этих массивов являются скалярные числа. Существует также возможность хранить в этих ячейках 4-векторы, которые могут содержать, например, координаты частиц. Последняя возможность была реализована нами в молекулярной динамике (см. следующий пример).
Ячейки массивов с исходными данными и рендер-цели адресуются не целыми числами, а парами чисел с плавающей точкой, задающими координаты центров ячеек (как если бы ячейки являлись участками изображения на экране, а записанные в них данные – характеристиками этих участков). Координаты левых нижних углов ячеек лежат в диапазоне от 0 до 1, а координаты центров таковы, как это показано на рис. 5.2.
Применительно к графическим процессорам используется следующая терминология. Двумерные массивы, в которых хранятся входные данные, называют текстурами, а элементы этих массивов – текселями. Координаты текселей, указывающие на центры ячеек, называют текстурными координатами. Количество текселей равно количеству элементов во входных массивах. Рендер-цель также представляет собой текстуру, количество текселей в которой равно количеству элементов в выходном массиве.
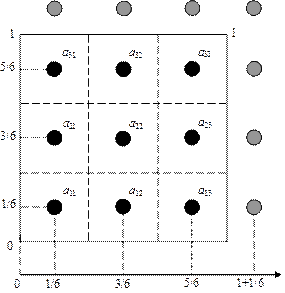
Рис. 5.2. Области координат, которыми адресуются числа, обрабатываемые графическим процессором
Результаты своей работы графический процессор по умолчанию выводит на экран, а точнее - в область памяти, называемую буфером кадра (framebuffer). Тем не менее, вычисления, не отображаемые на экране, также возможны, поскольку существует возможность сохранять результаты в заранее выделенную область памяти, которая как раз и называется рендер-целью (Render Target). Все современные GPU способны выводить данные сразу в несколько рендер-целей (Multiple Render Targets).
|
|
Дата добавления: 2014-12-07; Просмотров: 783; Нарушение авторских прав?; Мы поможем в написании вашей работы!