КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Представление исходных данных для GPU
|
|
|
|
В предыдущем примере представление складываемых матриц в виде двухмерных массивов было естественным. Здесь же частицы пронумерованы индексом i от 0 до N -1, так что образуют линейный массив. Для обработки на GPU 4-векторы с координатами и типами частиц необходимо хранить в ячейках двухмерного массива, как это показано на примере -.
| 1/128 | Ion[0] | Ion[64] | ¼ | Ion[1984] | ¼ | Ion[4096] | Ion[4160] | ¼ | Ion[6080] |
| 3/128 | Ion[1] | Ion[65] | ¼ | Ion[1985] | Ion[4097] | Ion[4161] | ¼ | Ion[6081] | |
| ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | |
| 63/128 | Ion[31] | Ion[95] | ¼ | Ion[2015] | Ion[4127] | Ion[4162] | ¼ | Ion[6111] | |
| 65/128 | Ion[32] | Ion[96] | ¼ | Ion[2016] | ¼ | Ion[4128] | Ion[4163] | ¼ | Ion[6112] |
| 67/128 | Ion[33] | Ion[97] | ¼ | Ion[2017] | Ion[4129] | Ion[4164] | ¼ | Ion[6113] | |
| ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | ¼ | |
| 127/128 | Ion[63] | Ion[127] | ¼ | Ion[2047] | Ion[4159] | Ion[4223] | ¼ | Ion[6143] | |
| 1/192 | 3/192 | ¼ | 63/192 | ¼ | 129/192 | 131/192 | 191/192 |
Рис 6.2. Массив исходных данных для графического процессора. Слева и внизу указаны текстурные координаты, по которым GPU будет обращаться к ячейкам массива
Размеры создаваемого массива по каждой из размерностей, вообще говоря, могут быть любыми, однако для оптимальной работы GPU лучше выбирать их кратными 32. Такой массив будет до конца заполнен частицами, если N кратно 322. Но даже если это не так, лучше оставить в массиве пустые ячейки, чем подгонять его размеры к реальному количеству частиц. Тип данных в массиве – 4-векторы. В качестве примера, на рис. 6.2. показана структура массива 64´96.
В идеальном стехиометрическом ионном кристалле присутствуют частицы двух типов – катионы и анионы. Соответственно, возможны 4 комбинации типов взаимодействующих частиц: анион-анион, анион-катион, катион-анион, катион-катион. Текстура, в которой параметры потенциалов взаимодействия передаются графическому процессору, показана на рис. 6.3. В парах индекс 0 относится к анионам, а индекс 1 – к катионам.
|
|
|
Комбинации анион-катион и катион-анион фактически эквивалентны, так как представляют одну и ту же пару частиц с одним и тем же потенциалом. Однако, при программировании GPU удобнее разместить пары анион-катион и катион-анион в различных ячейках массива входных данных, с одинаковыми параметрами потенциала (рис. 6.3).
| 1/4 | Пара (0;0): [ A 00, B 00, C 6, 00, C 8, 00] | Пара (1;0): [ A 10, B 10, C 6, 10, C 8, 10] |
| 3/4 | Пара (0;1): [ A 01, B 01, C 6, 01, C 8, 01] | Пара (1;1): [ A 10, B 10, C 6, 10, C 8, 10] |
| 1/4 | 3/4 |
Рис. 6.3. Массив параметров потенциалов взаимодействия для графического процессора. Как и на рис. 6.2., слева и внизу указаны текстурные координаты, по которым GPU будет обращаться к ячейкам массива; [ A 10, B 10, C 6, 10, C 8, 10] = [ A 01, B 01, C 6, 01, C 8, 01]
6.2.3. Алгоритм расчёта результирующих сил с использованием графического процессора
При программировании обычного процессора существовали бы два различных варианта организации циклов для вычисления результирующих сил, показанные на рис. 6.4.

а) б)
Рис. 6.4. Алгоритмы расчёта результирующих сил. Вариант б) лучше реализует принцип поточно-параллельных вычислений
Из двух приведённых схем для графического процессора лучше подходит алгоритм б), так как операции

для всех значений j могут быть осуществлены в поточно-параллельном режиме независимо друг от друга. В случае реализации алгоритма а) на графическом процессоре в параллельном режиме могли бы быть рассчитаны только векторы
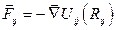 ,
,
после чего суммирование
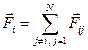
нужно было бы проводить на CPU, так как графический процессор не может согласовать параллельное суммирование многих величин с записью результата в одну и ту же общую ячейку памяти.
В настоящем примере для расчёта сил на GPU будет применяться алгоритм б). Далее мы проанализируем алгоритм шейдера, решающего эту задачу.
|
|
|
6.2.4. Шейдер для расчёта результирующей силы
Шейдер для расчёта результирующей силы имеет ту же структуру, что и в предыдущем примере сложения матриц. Эта структура показана на рис. 6.5.

Рис. 6.5. Обобщённая блок-схема шейдера
Ниже приведено конкретное содержание шейдера, с пояснениями.
· Блок описания входных данных.
/* Переменные, хранящие текстурные координаты иона j. Будут рассчитываться силы, действующие со стороны этого иона на все остальные */
float u_j, v_j;
/* Текстуры, в которых будут храниться данные:
in_pos – координаты и типы частиц, в форме 4-вектора;
in_coefs – коэффициенты потенциалов взаимодействия для каждой пары типов частиц. Для каждой пары – 4 коэффициента внутри одного 4-вектора;
out_force – компоненты результирующей силы, действующей на каждый из ионов */
texture in_pos, in_coefs, out_force;
· Блок описания «избирателей». Отметим ещё раз, что «избиратели» (samplers) - это автоматически исполняемые процедуры, которые передают данные из видеопамяти графическому процессору.
sampler pos = sampler_state { Texture = <in_pos>;},
coefs = sampler_state { Texture = <in_coefs>;},
force = sampler_state { Texture = <out_force>;};
· Пиксельный шейдер. В параллельном режиме вычисляет силу, действующую на каждый из ионов (индекс i) со стороны фиксированного j -го иона, после чего проводит суммирование.
/* Функция возвращает значение типа float4 – 4-х-вектор, три первые элемента которого содержат компоненты силы. Эта функция будет выполнена в параллельном режиме для всех возможных значений своего аргумента uv_i – координат i-х ионов во входной текстуре in_pos.
Аргумент uv_i имеет тип float2, то есть – является 2-компонентным вектором; этот вектор и содержит координаты ячейки в текстуре in_pos (см. рис. 5.2) */
float4 force_ij(float2 uv_i: TEXCOORD0): COLOR
{
/* ion_j – переменная типа float4. В эту переменную копируется 4-вектор, который хранится в ячейке текстуры in_pos с координатами (u_j, v_j) и содержит координаты и тип j-ого иона. В аналогичную переменную ion_i из ячейки текстуры in_pos с координатами uv_i копируется 4-вектор, характеризующий i-ый ион */
float4 ion_j = tex2D(pos, float2(u_j, v_j));
float4 ion_j = tex2D(pos, uv_j)
/* c – 4-вектор, расположенный в ячейке текстуры in_coefs с координатами (ion_i.w, ion_j.w), представляющими собой значения типов i-ого и j-ого ионов. Содержит параметры потенциала взаимодействия этой пары ионов */
|
|
|
float4 c = tex2D(coefs, float2(ion_i.w, ion_j.w));
/* R – 3-компонентный вектор, представляет собой радиус-вектор, направленный от j-ого иона к i-му иону */
float3 R = ion_i.xyz - ion_j.xyz;
/* r – скаляр одинарной точности, равный обратному расстоянию между i-м и j-м ионами, либо нулю (1e-8) в случае i = j */
float r = rsqrt(max(dot(R, R), 1e-8));
float r3 = r * r * r; //скаляр, равный r3
/* Далее, рассчитывается сила, действующая на i-й ион со стороны j-го иона, по формуле
 .
.
Здесь c.x = K E×| q i|×| q j| - множитель закона Кулона; c.y и c.z – константы экспоненциального отталкивания с потенциалом U = A ×exp{- B × R }, причём с.y = - A × B, с.z = - B; c.w – константа Ван-дер-Ваальсовского притяжения U = - C 6× R -6, равная 6× С 6.
Наконец, сила добавляется к текущему вектору результирующей силы, который уже был записан в ячейку uv_i рендер-цели в ходе предыдущих вызовов шейдера при меньших значениях j (см. алгоритм на рис. 6.4 б):
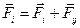 ,
,
Этот результат снова записывается в рендер-цель, в ячейку с координатами uv_i */
return float4(R * ((c.x - c.w * r3 * r * r) * r3 - c.y * r * exp(c.z / r)), 0) + tex2D(force, uv_j);
} // конец процедуры
· Вершинный шейдер. В нашем случае фактически не используется
void transform(in float4 xy_in: POSITION, in float2 uv_in: TEXCOORD0, out float4 xy_out: POSITION, out float2 uv_out: TEXCOORD0)
{
uv_out = uv_in;
xy_out = xy_in;
}
· «Техника», т.е., процедура, которая будет исполняться при обращении к графическому процессору из программы на C#. В свою очередь, исполняет функцию force_ij в качестве пиксельного шейдера и процедуру transform в качестве вершинного шейдера.
technique Force { pass force_i {
PixelShader = compile ps_3_0 force_ij();
VertexShader = compile vs_3_0 transform();
}} // Завершение программы
6.3. Исполнение шейдера из программы МД-моделирования на C#
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 446; Нарушение авторских прав?; Мы поможем в написании вашей работы!