КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Билет № 21. Определить используемую палитру для графического файла исходя из его информационного объема и размера в пикселях
 |
Определить используемую палитру для графического файла исходя из его информационного объема и размера в пикселях. (Вычисляется количество цветов в палитре и объем информации об одном пикселе.) Определить, как изменится информационный объем файла при изменении палитры.
Пример. Определить количество цветов в палитре и объем информации об одном пикселе, если в формате bmp рисунок размером 640 х 480 точек занимает на диске 900 килобайт. Как изменится размер файла, если этот рисунок преобразовать в черно-белый без изменения размеров рисунка?
Решение. 640 х 480 точек = 307 200 точек содержится в рисунке.
900 Кб: 307 200 = 900 х 1024 байт: 307 200 = 3 байта = 24 бит — используется для кодирования информации об одной точке.
Таким образом, всего кодовых комбинаций существует 224 = 16 777 216, т.е. количество цветов в палитре составляет 16 777 216.
Рассмотрим, как изменится объем файла, если используются только два цвета: черный и белый (без градаций). Для кодирования информации об одной точке достаточно одного бита. Таким образом, получаем 307 200 бит =38 400 байт = 37,5 Кб.
1. Кодирование текстовой информации. Основные приемы преобразования текстов: редактирование и форматирование. Использование систем распознавания текстов. Понятие о настольных издательских системах. Гипертекстовое представление информации. Использование готовых и создание собственных шаблонов. Использование систем проверки орфографии и грамматики. Тезаурусы. Использование систем двуязычного перевода и электронных словарей.
Примечание для учителей. По нашему мнению, вопрос составлен весьма неудачно. Во-первых, собрано вместе слишком много достаточно разнородных, “мелких” и (на уровне познаний ученика) тривиальных вопросов. Скажите честно, что может ученик прочесть в типовом учебнике о программах распознавания текстов или издательских системах? Почти ничего, кроме факта их существования и весьма очевидного предназначения. А что ему рассказали о проблемах и методах машинного перевода? Даже об алгоритме простой табличной замены одного слова другим мне в учебниках не удалось ничего найти1. И еще не забывайте, что вопрос теоретический, т.е. ученик должен что-то рассказать, а не демонстрировать владение пакетом. Тогда что мы хотим от него, бедного, услышать? (Неужели имелось в виду, что в ходе ответа ученик будет словами рассказывать, как пользоваться программами FineReader, PageMaker и Lingvo?) Во-вторых, логика расстановки отдельных вопросов непонятна. В частности, гипертекст явно относится к представлению информации, а не к прикладному ПО, “посреди” которого он оказался. Почему особо выделены шаблоны текстов, а не, например, гораздо более полезные для развития мышления пользователя стили? Наконец, почему вообще не упоминается о структурных элементах текста: символ — слово — предложение — абзац и т.д.? (В хороших книгах это всегда делается!) Мы предлагаем при составлении билетов в конкретной школе обдумать как минимум следующие возможности модификации вопроса:
|
|
|
· программы распознавания и т.п. объединить в один вопрос: “Программное обеспечение для обработки текстов: текстовые редакторы, издательские системы, системы распознавания текстов, электронные словари и системы машинного перевода: назначение, возможности и общие принципы работы”; последняя фраза о принципах нам кажется по смыслу важной, но, разумеется, если она не соответствует применяемой в школе программе, мы не настаиваем;
· аналогичным образом собрать шаблоны и проверку орфографии: “Возможности современных текстовых редакторов: стили, шаблоны, проверка орфографии и грамматики, организация структуры страниц (колонтитулы, сноски, нумерация страниц) и документов (разделы, главы, пункты, заголовки, оглавление)”; конкретный перечень выберите по своему усмотрению; при подготовке ответа советуем обратиться к книгам Ю.А. Шафрина;
|
|
|
· вопрос о гипертексте либо поставить на второе место, либо перенести в билет № 25, где обсуждается адресация в Интернет — чаты и форумы там вполне можно потеснить;
· как вариант, возможно, стоит добавить отдельное предложение о структуре текста (от отдельного символа до полного документа);
· соображения по поводу тезаурусов см. ниже в тексте статьи.
Перейдем теперь к непосредственному ответу на билет. Будем при этом строго следовать формулировке вопроса, как она опубликована в документе; особой логики в изложении при этом не получится, но “каков вопрос — таков ответ”.
Учитывая принятую в нашей публикации традицию давать материал подробнее, чем нужно рассказать на экзамене (чтобы учитель мог организовать полноценную подготовку, особенно в случаях, когда учебники освещают вопрос недостаточно), по программам распознавания текста и машинному переводу изложение несколько расширено.
Использование программ обработки текстовой информации является в настоящее время одним из наиболее распространенных применений компьютера. Возможности данного вида ПО становятся все шире, что позволяет получать высококачественные печатные документы со все более сложным устройством. Кроме того, текст в электронной форме гораздо удобнее обрабатывать: редактировать, хранить, пересылать и осуществлять поиск.
Главная идея кодирования текстовой информации в компьютере заключается в следующем. Текст состоит из отдельных символов, поэтому необходимо установить правила кодирования именно для символов. Общепринятый подход заключается в том, что определяется стандартная последовательность символов, и они нумеруются. Попутно заметим, что нумерация тех или иных объектов служит фундаментальным приемом кодирования информации в компьютере. В результате описанного подхода любой текстовый символ сохраняется в виде числа, которое является не чем иным, как его номером в общем стандартном списке символов (своеобразном алфавите). Например, для заглавной латинской буквы “A” принят десятичный номер 65, а для цифры “0” — 48. Считывая из памяти порядковый номер, компьютер изображает символ с этим номером либо извлекая из таблицы его “битовый образ” (комбинацию светлых и темных точек) при растровом способе изображения, либо запуская процедуру рисования с нужным номером при векторном способе2. Первый названный метод сейчас в основном представляет исторический интерес.
|
|
|
Примечание. Не следует путать символы и буквы. Символ — более широкое понятие, он включает в себя не только все буквы, причем часто из разных языков, но и знаки препинания, цифры, всевозможные служебные знаки и т.п. Пробел также является символом, хотя на экране ему и соответствует пустое место.
Кодирование символов с помощью номера в стандартной последовательности или, как часто говорят, в кодовой таблице очень компактно и удобно для компьютерной реализации. В то же время, при существовании нескольких кодовых таблиц и при неудачном выборе нужной возможно неверное отображение текста. С этим явлением многие, вероятно, сталкивались, читая электронную почту или, несколько реже, посещая некоторые web-страницы.
Из описанного выше способа кодирования текстов становится понятно, что символы хранятся в памяти и обрабатываются процессором как обычные числа. Более того, не существует принципиальных признаков, которые позволили бы отличить в памяти код числа от кода символа; например, число 32 и пробел имеют абсолютно идентичный двоичный код. То же самое можно сказать и об остальных видах данных, включая даже программу их обработки: все виды информации в компьютере сводятся к числам. Между прочим, в свете сформулированного вывода попытки утверждений, что современный компьютер чем-то качественно превосходит ЭВМ (вычислительную машину), выглядят весьма неубедительно.
Итак, мы выяснили, каким образом кодируются символы. Нетрудно понять, что описанный способ не позволяет указать размер символа, шрифт и прочие особенности его начертания — для этого требуется дополнительная информация. Правила кодирования приемов оформления текста существенным образом зависят от выбранного формата файла. Покажем это на примере некоторых наиболее распространенных типов файлов (см. также рис. 1).
|
|
|
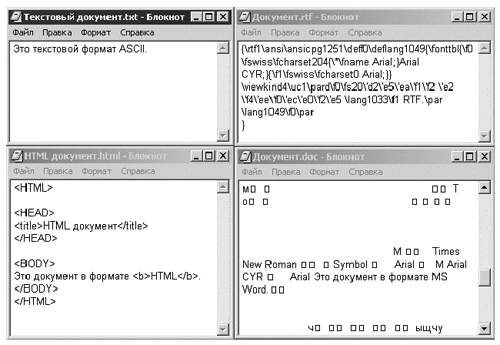
Рис. 1
1. Простейшие текстовые документы в формате ASCII. В них сохраняется только текст, поэтому никакие элементы оформления невозможны. Достоинством является компактность и универсальность, благодаря которым формат по-прежнему продолжает использоваться (техническая информация, электронная почта).
2. Документы в формате Unicode. По сравнению с предыдущим, формат позволяет одновременно использовать не два, а произвольное количество языков. Объем файла удваивается. На рис. 1 не приведен, поскольку при отображении по виду не отличается от документа ASCII.
3. HTML-документы, или, как их часто не совсем точно называют в обиходе, web-страницы. Для организации редактирования содержат специальную управляющую разметку, заключенную в угловые скобки (проще говоря, знаки “<” и “>”) и записанную в текстовом виде. Благодаря разметке программное обеспечение получает возможность отобразить текст в соответствующем оформлении (например, слово “HTML” из текста на рис. 1 будет напечатано жирным шрифтом).
4. Документы в формате RTF (R ich T ext F ormat). По принципу хранения во многом схожи с предыдущим форматом, только для выделения разметки используются другие знаки. Обратите внимание на интересную деталь: русские буквы сохраняются в виде шестнадцатеричных кодов (приведенная на рис. 2 последовательность d2 e5 ea f1 f2 образует русское слово “Текст”; полная исходная строка — “Текст в формате RTF”, причем пробелы и латинское ее окончание не преобразуются).
5. Документы MS Word. Фактически не являются в полном смысле слова текстовыми файлами, поскольку сведения о разметке и прочую служебную информацию хранят не в текстовом, а в бинарном виде. На рис. 1 отчетливо видно, что, помимо собственно текста “Это документ в формате MS Word”, имеются нетекстовые фрагменты (пустое место, “квадратики”, отображающие неспособность ПО преобразовывать коды в символы текста и, наконец, бессмысленные сочетания букв типа “ыщчу”). Внимательное рассмотрение вертикальной полосы прокрутки показывает, что файл самый большой из всех и собственно текст его единственного предложения является очень незначительной частью информации.
Таким образом, оказывается, что существует два аспекта представления текстовой информации — кодирование собственно символов и информации об оформлении текста; первая задача имеет более универсальное решение, вторая же, напротив, сильно зависит от программного обеспечения, которое работает с текстом.
В полном соответствии с выделенными выше направлениями кодирования, работа с любыми текстами имеет два типа деятельности пользователя. Первый связан с тем или иным изменением содержания текста, и именно это есть в полном смысле слова редактирование. Второй вид обработки текста связан с улучшением его оформления — размещение на странице, выравнивание по строкам, рамки, шрифты и многие другие средства; решение подобных проблем называется форматированием текста.
Возможности различных программ обработки текстов, разумеется, различны, но все они имеют некоторые стандартные функции. Для редактирования это набор текстов практически неограниченной сложности (включая символы, отсутствующие на клавиатуре, например, греческие или математические); возможность свободного перемещения по редактируемому тексту; удаление и вставка произвольных фрагментов, их перенос по тексту или “размножение”; поиск текста по образцу и, если необходимо, его замена; сохранение на внешний носитель и печать; возможность отмены ошибочно выполненных действий — вот далеко не полный перечень базовых возможностей редактирования любого современного ПО для обработки текстов. Что касается форматирования, то подавляющее большинство ПО данной категории способно устанавливать размер и шрифт символов, регулировать отдельные характеристики абзацев текста (таких, как отступ, межстрочный интервал, выравнивание в строке и т.п.), вставлять иллюстрации и таблицы, разбивать текст на страницы, при этом автоматически нумеруя их.
Не сомневаемся, что читатели смогут дополнить еще не одну функцию к этим представительным спискам.
Примечание. Перечни возможностей редактирования и форматирования, сформулированные выше, есть краткий конспект того, что должен раскрыть ученик в своем ответе. Разумеется, приведенные списки носят примерный характер, они сознательно составлены так, чтобы охватить как можно более широкий спектр возможностей, встречающихся в различных программных продуктах. На практике, по мнению авторов, целесообразно ориентироваться на конкретное используемое в школе ПО и отобрать те наиболее важные его функции, которые разбирались на уроках. Естественно, ученик должен не просто перечислять основные приемы преобразования текстов, но и уметь раскрыть каждый из них. Например, объяснить, какие способы форматирования абзаца могут быть установлены и чем они отличаются друг от друга. Учитель, в свою очередь, также должен при необходимости помочь вспомнить пропущенные возможности наводящими вопросами и оценивать не столько полноту перечня и скорость его воспроизведения по памяти, сколько понимание каждой возможности и ее роли в обработке текстов.
Особо хочется подчеркнуть, что в современных средствах обработки текстов — редакторах и браузерах применяется так называемое логическое форматирование текста. Оно заключается в том, что программное обеспечение снимает с пользователя заботу о деталях оформления и автоматически форматирует текст в имеющей место ситуации. Рассмотрим в качестве примера разбиение текста на строки. Как известно, в редакторе при вводе переход на следующую строку выполняется автоматически, а пользователь указывает только конец абзаца. Смысл такой организации ввода существенно глубже, чем экономия нажатий клавиши  . Гораздо важнее то, что в случае изменения размера шрифта, установки уплотненного его формата, включения механизма переносов или изменения размеров полей на листе прежнее разбиение на строки скорее всего окажется недействительным и его придется произвести заново. Аналогичным образом браузер при распределении текста по строкам учитывает текущий размер окна и выбранный серфером размер шрифта; в результате текст web-странички, который видит пользователь, может оказаться весьма далеким от того, каким его видел на своем мониторе web-мастер. Описанный логический подход является важным базовым принципом современных программ обработки текстов.
. Гораздо важнее то, что в случае изменения размера шрифта, установки уплотненного его формата, включения механизма переносов или изменения размеров полей на листе прежнее разбиение на строки скорее всего окажется недействительным и его придется произвести заново. Аналогичным образом браузер при распределении текста по строкам учитывает текущий размер окна и выбранный серфером размер шрифта; в результате текст web-странички, который видит пользователь, может оказаться весьма далеким от того, каким его видел на своем мониторе web-мастер. Описанный логический подход является важным базовым принципом современных программ обработки текстов.
Помимо ввода с клавиатуры, текст может быть введен в компьютер с листа бумаги при помощи сканера. Поскольку в результате работы сканера получается картинка, обязательно требуется специализированное программное обеспечение, способное найти на ней отдельные буквы, распознать их и сохранить в требуемой кодировке. В результате получается полноценный текстовый документ, такой же самый, что и при наборе с клавиатуры.
Задача нахождения в графическом изображении отдельных символов и их распознавание весьма нетривиальна. Несмотря на очевидные успехи в данной области, это тот вид деятельности, который человек до сих пор делает лучше компьютера. Интересно обсудить, как именно машина способна “читать текст”.
Распознавание символов по их графическому изображению — одна из старых и традиционных задач искусственного интеллекта: работы по ее решению начались еще в 60–70-е годы прошлого века. Однако только с развитием компьютерной техники распознавание символов получило полноценное практическое применение.
Согласно сведениям из интересной книги Л.Н. Ясницкого (см. список литературы), все существующие в настоящее время методы распознавания символов относятся к одной из трех категорий:
· Шаблонный метод
Заключается в сопоставлении распознаваемого изображения с эталонными символами, шаблоны которых компьютеру известны; в качестве меры “похожести” символов может быть взята доля совпадающей площади изображений при их наложении друг на друга; задача эта не такая тривиальная, как кажется в первый момент, из-за возможных дефектов печати, помарок на бумаге, поворота листка при сканировании и прочих осложняющих факторов.
· Структурный метод
Распознаваемый объект представляется в виде графа, узлами которого являются элементы изображения, например, отрезки прямых или части окружности, а дугами графа описываются пространственные отношения между элементами; для сравнения графов применяются методы теории графов.
· Признаковый метод
Согласно этому методу изображение распознаваемого символа представляется как объект в n -мерном пространстве признаков; в качестве признаков может, например, служить скругленный левый верхний угол символа (а, б, е, з, о, с, ф, э, я) или наличие двух вертикальных отрезков во всю высоту буквы (и, й, л, м, н, п, ц, ш, щ, ы); полученный n -мерный вектор сравнивается с эталонными и подбирается наиболее близкий из них.
Каждый метод имеет свои достоинства и недостатки. Так, шаблонные методы устойчивы к дефектам изображения и быстро работают, но применимы только к известным шрифтам. Поэтому хорошее программное обеспечение для повышения надежности распознавания всегда использует сочетание нескольких методов. Наиболее известная в России программа FineReader совмещает в себе шаблонный и структурный подходы. Другая, считающаяся более интеллектуальной, система CuneiForm также использует несколько методов. Ее дополнительной особенностью является возможность самообучения, которая применяется при распознавании “нечетких” текстов. Система, произведя первичную обработку изображения, выделяет наиболее надежно распознанные буквы и формирует для них шаблоны, с помощью которых производится повторное распознавание текста. Авторы утверждают, что подобный подход позволяет повысить точность распознавания текста в несколько раз. Программа CuneiForm имеет также ряд других интересных особенностей. В частности, она умеет, используя интеллектуальный алгоритм, автоматически подбирать оптимальный уровень яркости сканера и использует систему орфографического и синтаксического контроля (в том числе словарь) для проверки правильности распознавания символов.
Следующий вид программного обеспечения, о котором надо кратко рассказать, отвечая на вопрос, — это издательские системы. Строго говоря, обычный текстовый редактор и издательская система являются родственными программными продуктами и отличаются лишь полнотой своих возможностей. Обычно под текстовыми редакторами принято понимать программы, выполняющие наиболее простые операции над текстами (типа Блокнота в Windows). Если редактор имеет расширенные возможности, это обстоятельство часто подчеркивают, называя его текстовым процессором. Наиболее популярны у пользователей такие мощные текстовые процессоры, как MS Word, Open Office Writer и Word Perfect; среди авторов научных статей большим уважением пользуется система TEX, разработанная, между прочим, известным ученым Д.Кнутом. Наконец, ПО для профессионального издания газет, журналов и книг вполне естественно именуется издательскими системами (Aldus PageMaker, Adobe PageMaker, Corel Ventura Publisher). Отметим, что четкой границы между названными видами программных продуктов нет. Добавим, что программисты сейчас пользуются специализированными редакторами, которые способны учитывать особенности программного текста (прекрасным образцом служит редактор, который используется в современной системе программирования DOT NET).
Профессиональные издательские системы позволяют осуществлять подготовку к массовому тиражированию любых печатных материалов, легко изменяя их взаимное расположение и оформление (специалисты используют термины “верстка” и “макетирование”). Чтобы некоторым образом представить специфику профессиональной работы с текстами, приведем пример: печатники предъявляют повышенные требования к размещению текста в пределах строк, что корректируется незначительным изменением плотности символов в отдельных словах, и строк на странице (в частности, ни в коем случае недопустим отрыв одной строки от абзаца). Издательские системы — это весьма дорогие коммерческие профессиональные продукты, так что их отсутствие в компьютерном классе школы не должно вас смущать. Кроме того, еще раз подчеркнем, что развитый текстовый процессор в принципе способен выполнить большую часть подобных операций, так что знакомства с этой категорией программного обеспечения для непрофессионала вполне достаточно.
Перейдем к гипертекстовому представлению информации. Вопрос несложный и многократно описанный, поэтому рассмотрим его кратко.
Исторически первые системы гиперссылок использовались еще в книгах, особенно энциклопедиях и справочниках: понятия, пояснения к которым можно найти в данной книге, выделялись, например, курсивом. В компьютерных текстах наличие гиперсвязей позволяет непосредственно переходить на экране от одного документа к другому или, в частном случае, от одной части документа к другой. Строго говоря, гиперсвязи возможны не только между текстами: в современных мультимедийных документах можно, например, дать ссылку на графику, звуковые файлы и даже программы.
Механизм реализации гиперссылки поясняется на рис. 2.
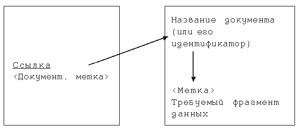
Рис. 2
В исходном документе место ссылки как-то выделяется: цветом, подчеркиванием, рисунком, рамкой и т.п. Внутри электронного документа в некотором внутреннем формате хранятся связанные с этой ссылкой данные о расположении той информации, на которую надо по этой ссылке перейти, т.е. ссылка на другой (в частности, может быть, и тот же самый) документ и некоторую внутреннюю “невидимую” на странице метку, определяющую положение необходимого фрагмента данных. В web-страницах в качестве ссылок используется универсальный идентификатор ресурса (адрес) в Сети, который принято называть URL; он может при необходимости дополняться меткой. Важно сказать, что URL имеют не только текстовые, но и графические, звуковые, мультимедийные и прочие ресурсы, что и позволяет ссылаться не только на тексты. Особо подчеркнем, что хотя гиперссылки получили свое активнейшее применение именно в документах Всемирной паутины, Интернет — не единственное место их использования. В частности, уже начиная с MS-DOS, существовали так называемые “файлы электронных справок”, где также применялся механизм гиперссылок. Позднее в самых первых версиях Windows была разработана универсальная система гипертекстовой помощи, которая была весьма мощной3 и удобной. По нашему мнению, данная единая для всех программ гипертекстовая система помощи была весьма удачной, так что ее вытеснение документами стиля HTML, скорее, уступка неквалифицированным пользователям, чем свидетельство их превосходства.
Следующий вопрос — шаблоны текстов. Пользователям часто приходится оформлять однотипные текстовые документы (отчеты, деловые письма, календари). Внутри каждого типа документов много общего: содержатся одинаковые характерные фрагменты текста и рисунки, используется сходный стиль оформления, для их подготовки требуется специфическая комплектация панели инструментов. Текстовые процессоры типа MS Word позволяют упростить подготовку такого рода документов путем сохранения специальной заготовки — шаблона. Шаблон — это служебный файл4, который содержит всевозможную информацию о структуре и оформлении документов данного типа. Набор типовых шаблонов подготовлен и включен в состав инсталляции редактора. Для документов общего типа предусмотрен стандартный шаблон (NORMAL.DOT). Разумеется, пользователь может создать и сохранить собственный шаблон.
Примечание. Наличие общего файла шаблонов NORMAL.DOT создает предпосылку для распространения особого вида вирусов — макровирусов. Попадая в шаблон, они распространяются во все набираемые с его помощью тексты.
Важной особенностью автоматизации процесса оформления документа служат стили оформления, которые являются составной частью шаблона. В стилях запоминаются все особенности оформления данного типа фрагментов текста, такие, как название и размер шрифта, выравнивание и т.п. В результате, создав в своем документе стиль, например, для цитат, вы можете легко применять его к любой только что набранной цитате — новая цитата немедленно станет выглядеть, как все предыдущие. Более того, достаточно внести изменения в стиль, и абсолютно все цитаты, где бы они в тексте не располагались, немедленно приобретут скорректированный вид. Большое значение при оформлении документов имеют стили для многоуровневых заголовков, уже имеющиеся в стандартном шаблоне, но допускающие свое изменение. Именно благодаря им редактор способен впоследствии легко сформировать оглавление текста. Следует подчеркнуть, что на практике при оформлении текстов использование стилей позволяет очень существенно облегчить работу по сравнению с “ручным” оформлением каждого фрагмента, особенно если оформление текста по тем или иным причинам может часто изменяться.
Почти все современные редакторы обладают системами проверки орфографии и грамматики. Несмотря на заметную помощь, которую они оказывают, следует понимать, что механизм проверки вовсе не гарантирует стопроцентной фиксации ошибок. Смысл орфографической проверки заключается в том, что каждое введенное слово ищется в стандартном словаре правописания, представляющем собой файл5 с полным списком слов используемого языка. Очевидно, что проверка происходит чисто механическим образом, так что если слово формально имеется в словаре, то считается, что ошибки нет. Поэтому с точки зрения программы фраза “он держал в реке зажженную свечу” (правильно “в руке”), несмотря на явную опечатку, не вызывает ни малейших подозрений. Еще более слаб грамматический контроль, рекомендации которого могут быть откровенно неправильными. Например, в предложении “В общем вагоне билет стоит гораздо дешевле” редактор уверенно предлагает после “в общем” поставить запятую.
Пользователь имеет возможность занести в словарь новые слова. Кроме того, часто предусмотрена еще одна дополнительная возможность — словарь синонимов, т.е. слов с одинаковым значением. В Microsoft Office он называется тезаурус (thesaurus).
Примечание. Здесь имеет место существенная нечеткость в терминологии. Термин тезаурус в информатике имеет несколько близких по смыслу значений: полный словарь языка, словарный запас человека; свод терминов и понятий в какой-либо области со связями между ними, т.е., по сути дела, модель знаний по выбранной тематике. Если вы помните, в билете № 3 мы уже встречались с данным термином в значении совокупности знаний приемника информации по теме принимаемого сообщения. Тезаурус — не просто теоретическое определение, но он активно используется на практике, например, при обработке запросов. Очевидно, что определение в Microsoft Office тезауруса как словаря синонимов весьма неудачно, тем более что тезаурус в общепринятом смысле там тоже есть (тот самый словарь, по которому проверяется правописание). Все это лишний раз свидетельствует о том, что изучение наукиинформатики через посредство офисных технологий напоминает попытку овладеть медицинскими знаниями, читая инструкции к купленным в аптеке лекарствам.
И еще одно замечание. Видимо, совершенно случайно формулировка билета оказывается аналогом известной фразы “ казнить нельзя помиловать ”, трактовка которой зависит от положения запятой6. В нашем билете трактовка предложения “Тезаурус.” также существенно зависит от того, к какой части вопроса мы его отнесем. Так, если связать его с предыдущей фразой о проверке орфографии, то получится, что надо рассказывать о словаре синонимов; подозреваю, что тот, кто написал билет, так и предполагал. Но, с другой стороны, тезаурус можно отнести к следующему предложению, об электронных словарях. И такое сочетание тоже имеет смысл в информатике, даже гораздо более глубокий, чем предыдущее. Тезаурус — это тоже словарь, “одноязыкий” и, может быть, даже идеографический, т.е. такой, в котором слова упорядочены не по алфавиту, а по смыслу… Выводы делайте сами.
Нам остается рассмотреть электронные словари и системы автоматического перевода.
Приложения первого типа реализуются весьма элементарно, но они получили широкое распространение за то, что поиск в них несравненно удобнее поиска в толстых многостраничных словарях. Имеются даже небольшие специализированные карманные электронные устройства, реализующие многоязыкие словари с возможностью звуковой демонстрации произношения.
С точки зрения информатики организация электронного словаря есть абсолютно стандартная задача. Введенное слово или словосочетание ищется в списке и в случае совпадения по имеющимся ссылкам выводится вся связанная информация. При очень больших словарях возникает дополнительная подзадача оптимизации поиска, но для многих “бытовых” потребностей достаточно лишь простейших приемов сокращения поиска.
Несравненно более сложной задачей оказывается компьютерный перевод с одного языка на другой. В первый момент кажется, что, имея хороший словарь, перевести текст не составит труда. Думаю, большинство читателей понимают, почему это первое впечатление в корне ошибочно. Главной трудностью является многозначность человеческого языка. Так называемая “игра слов”, когда одни и те же слова обозначают абсолютно разные вещи, часто встречается в жизни. Вот, например, цитата из известной сказки Л.Кэрролла “В Зазеркалье”: “Откуда берется хлеб? Отвечай! — Это я знаю, он печется… — Печется? О ком это он печется? — Не о ком, а из чего… Берешь зерно, мелешь его… — Не зерно ты мелешь, а чепуху!” Причем одинаковые слова могут весьма неожиданным образом даже обозначать разные части речи, например, слово “пила” в зависимости от контекста может быть как существительным (инструмент), так и глаголом женского рода прошедшего времени (от слова “пить”). Кстати, понятно теперь, почему во всех машинных языках предъявляются такие жесткие требования к уникальности идентификаторов?
Трудности могут возникать не только из-за многозначности перевода отдельных слов, но и из-за грамматической неоднозначности переводимого текста. Возьмем, например, короткое и простое с виду английское предложение “The time flies like arrow”, т.е. “Время летит, как стрела”. По данным английских лингвистов, данная фраза допускает не менее четырех(!) различных синтаксических интерпретаций. В связи с этим одним из вариантов ее возможного “механического” перевода будет, в частности, “Временн ы м мухам нравятся стрелы”. И не надо смеяться над новым видом насекомых, который возник в результате перевода: не каждый человек знает породы мух7, стоит ли требовать это от машины-“филолога”? Самое поразительное, что с точки зрения всех правил языка данный дословный перевод формально абсолютно правильный. Не вдаваясь в подробности, для примера скажем, что слово flies является как одной из грамматических форм глагола “лететь”, так и множественным числом для существительного “муха”. Аналогичная неоднозначность существует и для других слов, входящих в предложение, в результате чего и порождается информация о необычных мухах со странными вкусами. Человеку подобное просто не приходит в голову благодаря жизненному опыту; к сожалению, компьютер лишен этого необычайно ценного и плохо формализуемого внутреннего критерия. Как говорил Марвин Минский, крупный специалист по машинному представлению знаний, “трудность состоит в том, что здравый смысл основан на знании тысяч вещей о тысячах различных свойств вещей”.
Примечание. Если пример понравился, попробуйте найти несколько вариантов трактовки русской фразы “юноша встретил девушку на поляне с цветами”.
Работы по машинному переводу начались давно, почти сразу после появления первых вычислительных машин. Так, в 1949 году знаменитый американский математик Уоррен Уивер представил документ, предлагавший ни много ни мало “решение мировой проблемы перевода”. Идея была проста и наглядна: он предлагал создать некоторый промежуточный “машинезийский” язык и все тексты, используя словари, сначала переводить на него; затем оставалось взять другой словарь, с его помощью перевести слова и расставить их в соответствии с правилами грамматики выходного языка. Учитывая большие успехи проекта “Колосс”, благодаря которому в Великобритании в годы Второй мировой войны группа математиков успешно расшифровала секретные коды, идея автоматического перевода выглядела тогда вполне правдоподобно — как расшифровка текста, записанного непонятными значками чужого языка.
Идея автоматического перевода очень понравилась Министерству обороны США, которое рассчитывало получить способ легкого и быстрого изучения русских технических изданий. В результате исследования получили весьма щедрое финансирование и интенсивно стартовали. Не менее активно готовили симметричный ответ и советские ученые, мечтавшие обеспечить быстрый и точный перевод американских источников информации.
По мере продвижения работ энтузиазм все больше и больше угасал, и к середине 60-х годов финансирование работ в области машинного перевода в основном прекратилось. Стало ясно, что для перевода с языка на язык недостаточно знать значения отдельных слов и правила грамматики. Чтобы научиться переводить с одного языка на другой, машина должна понимать язык, т.е. как-то оценивать информационный контекст.
Передовые исследования переключились на другую проблему. К сожалению, несмотря на огромные потраченные усилия и значительный рост технических возможностей компьютеров, существенного прорыва в этой области искусственного интеллекта до сих пор не наступило — лингвистические программы пока не приблизились по уровню к среднему ребенку дошкольного возраста. Тем не менее в настоящий момент вопросы компьютерной обработки и машинного структурирования знаний развиваются весьма бурно.
Литература
1. Шафрин Ю.А. Информационные технологии (в 2 ч.). Ч. 2. М.: Лаборатория Базовых Знаний, 2000, 336 с.
2. Кушниренко А.Г., Лебедев Г.В., Зайдельман Я.Н. Информатика. 7–9-е классы: Учебник для общеобразовательных учебных заведений. М.: Дрофа, 2000, 336 с.
3. Угринович Н.Д. Информатика и информационные технологии. Учебное пособие для 10–11-х классов. Углубленный курс. М.: Лаборатория Базовых Знаний, 2000, 440 с.
4. Ясницкий Л.Н. Введение в искусственный интеллект. Пермь: Пермский университет, 2001, 143 с.
5. Компьютер обретает разум. М.: Мир, 1990, 240 с.
6. Перегудов В.М., Халамайзер А.Я. Бок о бок с компьютером. М.: Высшая школа, 1987, 192 с.
1 Еще бы, кто посмеет “юзеру” рассказывать о массиве из двух столбцов, пусть даже применяя слово “таблица”?
2 Об особенностях растровой и векторной графики см. билет № 19.
3 Например, в системе помощи, если ссылка подчеркнута двумя чертами, то новая страница не замещает старую, а открывается в отдельном окне; имеется универсальная встроенная система навигации и поиска, причем последний возможен как по теме и ключевым словам, так и по любому произвольному слову в тексте; возможно объединение нескольких справочных файлов под общим содержанием.
4 В MS Word файлы шаблонов имеют расширение DOT.
5 В MS Word — MSSP3RU.LEX и MSSP3EN.LEX.
6 Любопытно, что синтаксический анализатор MS Word гуманно рекомендует поставить запятую после слова “нельзя”!
7 В частности, по-английски слепни — это horse-flies, т.е. дословно “лошадиные мухи”.
|
|
|
|
|
Дата добавления: 2015-04-23; Просмотров: 1893; Нарушение авторских прав?; Мы поможем в написании вашей работы!