КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Приклад
|
|
|
|
В якості такого прикладу використано результати тренажерної підготовки операторського персоналу систем опрацювання аерокосмічних зображень, задіяних в задачах виявлення на них об’єктів заданого класу. В результаті опрацювання одного і того ж сценарію, який полягав у поданні на монітор послідовності тестових зображень, для кожного оператора отримані дані про час опрацювання кожного тесту, тобто пошуку і виявлення та ідентифікації об’єкта на тестовому даного сценарію. Значення цього часу є випадковими величинами з асиметричним одномодальним розподілом і поданими у вигляді індивідуальних часових рядів.
Формування таблиці «об’єкт- властивість». В результаті первинної обробки даних в сенсі описової статистики в межах показників визначених для цього в Ms Excel 2003 побудована таблиця, яку називають таблицею «об’єкт - властивість». В даному випадку, більш коректно, це є таблиця «оператор-індивідуальні показники» розміром 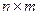 , де
, де 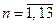 – кількість операторів, а
– кількість операторів, а 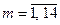 – кількість використаних показників описової статистики. Отже, для кластерного аналізу подається множина
– кількість використаних показників описової статистики. Отже, для кластерного аналізу подається множина 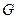 , яка включає
, яка включає 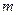 об’єктів, кожен з яких характеризується
об’єктів, кожен з яких характеризується 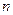 ознаками. Дані представлені нижче в табл. 1
ознаками. Дані представлені нижче в табл. 1
Таблиця 1.
Таблиця «оператор - показник» – значень показників об’єктів за описовою статистикою
| Показники | ||||||||||||||
| Об’єк ти | Середнє | Стнд.пом. | Медіана | Мода | Стнд. відх. | Диспер сія | Екс цес | Асимет рія | Роз мах | Міні мум | Макси мум | Сума | К-сть | Надій ність |
| Bur | 1886,2 | 26,68 | 1839,5 | 322,4 | 3,837 | 1,257 | 52,7 | |||||||
| Cub | 678,9 | 17,57 | 636,0 | 187,6 | 0,790 | 0,995 | 34,8 | |||||||
| Cup | 1506,5 | 22,74 | 1484,0 | 245,9 | -0,267 | 0,516 | 45,0 | |||||||
| Hav | 753,7 | 16,74 | 726,5 | 169,1 | 1,714 | 1,208 | 33,2 | |||||||
| Hod | 709,5 | 16,62 | 674,0 | 171,1 | 1,742 | 1,261 | 32,9 | |||||||
| Kol | 430,2 | 8,96 | 415,0 | 105,3 | 6,887 | 2,169 | 17,7 | |||||||
| Lob | 665,0 | 18,36 | 622,5 | 179,9 | 0,828 | 1,037 | 36,4 | |||||||
| Lot | 608,2 | 15,81 | 593,0 | 178,2 | 2,029 | 1,163 | 31,3 | |||||||
| Oli | 655,3 | 16,69 | 619,0 | 166,0 | 3,005 | 1,503 | 33,1 | |||||||
| Per | 728,3 | 8,19 | 717,0 | 96,5 | 7,528 | 1,662 | 16,2 | |||||||
| Pon | 675,9 | 14,43 | 651,5 | 165,8 | 0,451 | 0,754 | 28,5 | |||||||
| Sol | 1633,1 | 28,83 | 1588,0 | 311,9 | 0,590 | 0,771 | 57,1 | |||||||
| Syr | 704,4 | 19,03 | 645,5 | 215,3 | 1,952 | 1,325 | 37,7 |
|
|
|
Наведені в табл. 1 показники за величиною і розмірністю є дуже неоднорідними, а це означає неможливість обґрунтованої інтерпретації отриманого результату кластерного аналізу. Це приводить до того, що величина, отриманих в результаті кластеризації відстаней між точками, що відбивають положення об'єктів у просторі їхніх властивостей, визначатиметься довільно обраним масштабом. Щоб усунути неоднорідність виміру вихідних даних, всі їхні значення попередньо нормуються, тобто виражаються через відношення цих значень до деякої величини, що відбиває певні властивості даного показника. Важливо, щоб усі змінні змінювалися в порівнянних шкалах.крім того, за наявності значного розкиду величин значень необхідно привести їх до інтервалу 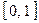 , тобто здійснити їх нормування.
, тобто здійснити їх нормування.
Нормування таблиці «об’єкт-властивість». Основні труднощі полягають у виборі способу нормування, оскільки, необхідно максимально врахувати якісну специфіку показників. Нормування використовують в тому випадку коли ознаки представлені різними шкалами і мають різний фізичний зміст (розмірність). Нормування – це перехід до деякого однакового опису для всіх ознак і введення нової умовної одиниці вимірювання, яка допускає формальне зіставлення об'єктів чи їх ознак. Нормування приводить до безрозмірних величин, зберігаючи за ними відповідність ознакам.
|
|
|
Найбільш розповсюджувані способи нормування показників, тобто перехід від початкових значень 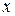 до нормованих
до нормованих 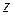 , здійснюють за формулами [Мандель стор. 27]:
, здійснюють за формулами [Мандель стор. 27]:
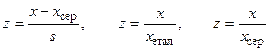 ,
,
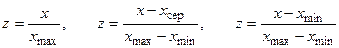 , (2)
, (2)
де 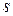 – середньоквадратичне відхилення.
– середньоквадратичне відхилення.
Найбільш поширеним нормування є лінійне перетворення, яке проводять за модифікованою останньою формулою.
Визнання рівноцінності різних показників є виправданим аж ніяк не завжди. Очевидно, що великі значення дисперсії та суми та їх варіації будуть суттєво впливати на результат кластерного аналізу.
В результаті нормування за цією формулою всі дані табл. 1 є приведені до одиничного інтервалу, тобто ця таблиця прийме вигляд табл. 2. Нормування здійснюється по кожному стовпчику окремо, тобто нормуються ознаки одного типу.
Таблиця 2.
Таблиця «оператор - показник» – після нормування
| Показники | ||||||||||||||
| Опера тори | Середнє | Стнд. пом. | Медіа на | Мода | Стнд. Відх. | Диспер сія | Екс цес | Асимет рія | Роз мах | Міні мум | Макси мум | Сумма | К-сть | Надій ність |
| Bur | 1,000 | 0,896 | 1,000 | 1,000 | 1,000 | 1,000 | 0,527 | 0,447 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 0,893 |
| Cub | 0,171 | 0,454 | 0,155 | 0,220 | 0,403 | 0,274 | 0,136 | 0,288 | 0,162 | 0,141 | 0,154 | 0,083 | 0,360 | 0,455 |
| Cup | 0,739 | 0,705 | 0,750 | 0,973 | 0,662 | 0,541 | 0,000 | -0,002 | 0,260 | 0,847 | 0,482 | 0,541 | 0,420 | 0,705 |
| Hav | 0,222 | 0,414 | 0,219 | 0,282 | 0,321 | 0,204 | 0,254 | 0,417 | 0,108 | 0,253 | 0,163 | 0,081 | 0,120 | 0,416 |
| Hod | 0,192 | 0,408 | 0,182 | 0,225 | 0,330 | 0,211 | 0,258 | 0,449 | 0,114 | 0,231 | 0,158 | 0,073 | 0,200 | 0,410 |
| Kol | 0,000 | 0,038 | 0,000 | 0,000 | 0,039 | 0,019 | 0,918 | 1,000 | 0,000 | 0,000 | 0,000 | 0,000 | 0,840 | 0,038 |
| Lob | 0,161 | 0,493 | 0,146 | 0,136 | 0,369 | 0,244 | 0,141 | 0,313 | 0,078 | 0,119 | 0,094 | 0,021 | 0,000 | 0,495 |
| Lot | 0,122 | 0,369 | 0,125 | 0,153 | 0,362 | 0,237 | 0,295 | 0,390 | 0,165 | 0,111 | 0,145 | 0,083 | 0,620 | 0,369 |
| Oli | 0,155 | 0,412 | 0,143 | 0,142 | 0,308 | 0,193 | 0,420 | 0,596 | 0,107 | 0,162 | 0,128 | 0,025 | 0,060 | 0,414 |
| Per | 0,205 | 0,000 | 0,212 | 0,218 | 0,000 | 0,000 | 1,000 | 0,692 | 0,030 | 0,275 | 0,123 | 0,194 | 0,860 | 0,000 |
| Pon | 0,169 | 0,302 | 0,166 | 0,070 | 0,307 | 0,192 | 0,092 | 0,142 | 0,071 | 0,161 | 0,105 | 0,138 | 0,720 | 0,302 |
| Sol | 0,826 | 1,000 | 0,823 | 0,802 | 0,954 | 0,930 | 0,110 | 0,152 | 0,511 | 0,917 | 0,665 | 0,610 | 0,420 | 1,000 |
| Syr | 0,188 | 0,525 | 0,162 | 0,140 | 0,526 | 0,392 | 0,285 | 0,488 | 0,290 | 0,081 | 0,210 | 0,143 | 0,640 | 0,525 |
Зауважимо, що нормування означає, що всі ознаки є рівноцінними з погляду з'ясування подібності розглянутих об'єктів. Інколи, поряд з нормуванням надають кожному з показників вагу і тим самим вказують на його значущість в ході встановлення подібностей і відмінностей між об'єктами.
|
|
|
Вибір метрики для побудови матриці близькостей. Якщо відстань між об’єктами природно трактувати як міру відмінності об’єктів, то обернену величину 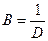 можна розглядати як міру подібності (близькості) об’єктів.
можна розглядати як міру подібності (близькості) об’єктів.
1. Найчастіше відстань 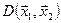 між об’єктами вимірюють в евклідовій матриці, яка найбільш узгоджена з нашими інтуїтивними представленнями про близькість об’єктів і визначається за формулою
між об’єктами вимірюють в евклідовій матриці, яка найбільш узгоджена з нашими інтуїтивними представленнями про близькість об’єктів і визначається за формулою

 , (4)
, (4)
де 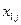 та
та 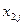 – значення
– значення 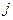 -ї компоненти в описах 1-го та 2-го об’єктів,
-ї компоненти в описах 1-го та 2-го об’єктів, 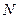 – розмірність простору ознак, а в даному випадку
– розмірність простору ознак, а в даному випадку 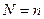 .
.
2. Широко використовується лінійна метрика (метрика міських кварталів або манхетенська метрика) яка задає відстань
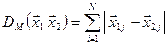 , (5)
, (5)
а також sup- норма, яка визначає чебишевську відстань
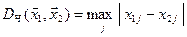 . (6)
. (6)
|
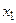
 |
Рис.1. Ілюстрація змісту відстаней 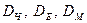 .
.
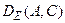 - довжина відрізка АС;
- довжина відрізка АС; 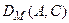 - сума довжин відрізків АВ і ВС;
- сума довжин відрізків АВ і ВС;
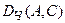 - довжина більшого з відрізків АВ і ВС, тобто АВ.
- довжина більшого з відрізків АВ і ВС, тобто АВ.
Очевидно, що 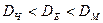 з ростом розмірності манхетенська відстань
з ростом розмірності манхетенська відстань 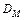 підкреслює, а чебишовська злагоджує відмінності між об’єктами. Відстані
підкреслює, а чебишовська злагоджує відмінності між об’єктами. Відстані 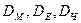 визначаються для тих описів, в яких ознаки виражені кількісними шкалами і є по-суті частинними випадками узагальнення відстані Мінковського
визначаються для тих описів, в яких ознаки виражені кількісними шкалами і є по-суті частинними випадками узагальнення відстані Мінковського 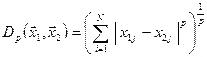 , тобто відстані визначаються значенням степеня
, тобто відстані визначаються значенням степеня 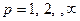 . Існує досить велика різноманітність мір, але на практиці ці міри є найуживанішими.
. Існує досить велика різноманітність мір, але на практиці ці міри є найуживанішими.
Евклідова відстань ефективна при дослідженні слабо кореляційних сукупностей об’єктів (кулеподібні класи), а манхетенська тоді, коли об’єкти утворюють плоскі витягнені класи, ортогональні будь-яким координатним осям простору ознак. Тому обробка однієї і тієї ж сукупності даних одним і тим же методом або алгоритмом, але з використанням різних метрик може дати різні, інколи кардинально протилежні, результати.
Отже, до вибору метрики слід підходити дуже продумано і обережно зіставляючи результати використання різних метрик між собою і з цілями здійснюваної обробки даних.
|
|
|
Якщо ознаки представляються в якісних шкалах, зокрема в шкалах найменувань та порядку, використовують відстань Геммінга
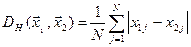
для якої відмінності виражаються числом неспівпадінь властивостей порівнюваних об’єктів. У випадку якісних шкал ознаки розглядаються як бінарні, тобто такі, що можуть приймати лише два значення “ 0 “ та “ 1 “. Відстань Геммінга 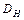 є максимальною і рівна 1 для об’єктів з протилежними за значеннями описами, тобто елементи одного опису є протилежними до відповідних елементів опису другого об’єкту. Для об’єктів, всі ознаки яких (з числа включених в опис) співпадають,
є максимальною і рівна 1 для об’єктів з протилежними за значеннями описами, тобто елементи одного опису є протилежними до відповідних елементів опису другого об’єкту. Для об’єктів, всі ознаки яких (з числа включених в опис) співпадають,  .
.
При виборі виду міри близькості необхідно врахувати їх формальні властивості і зіставити їх із змістовними особливостями задачі.
В результаті застосування будь-якої з цих метрик до даних отримують матрицю близькостей, розмірність якої  , а за своєю специфікою вона є симетричною відносно головної діагоналі.
, а за своєю специфікою вона є симетричною відносно головної діагоналі.
Побудова таблиці близькостей. Для побудови матриці близькостей за допомогою табличного процесора Ms Excel 2003 використовують дані табл. 2 в такий спосіб.
1. На робочому листі поміщають табл. 2 та її копію, так щоб номери стрічок в них були однакові, наприклад, якщо перший елемент табл. 2 – таблиці-оригіналу розміщений в комірці В3, то перший елемент таблиці-копії цієї таблиці є розміщений в комірці R3.
2. Далі будують матрицю близькостей. При цьому неминуче виникає задача вибору міри близькості. Найчастіше відстань між об’єктами вимірюють в евклідовій метриці, її ще називають евклідовою відстанню і розраховують за такою формулою
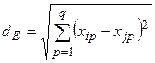 (5)
(5)
Евклідова метрика, є найбільш узгодженою з нашими інтуїтивними представленнями про близькість об’єктів.
3. В результаті застосування до матриці даних цієї метрики отримують матрицю близькостей, розмірність якої , де 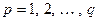 – номер ознаки,
– номер ознаки, 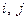 – індекси пари об’єктів, між якими визначають відстань. Матриця відстаней за своєю специфікою є симетричною відносно головної діагоналі.
– індекси пари об’єктів, між якими визначають відстань. Матриця відстаней за своєю специфікою є симетричною відносно головної діагоналі.
В Екселі матрицю близькостей будують так. Визначають комірку для розміщення першого елемента матриці близькостей, наприклад, В18, тобто нижче на кілька стрічок під таблицею, в якій розміщують (для даного випадку) таку формулу
=КОРЕНЬ(СУММ(($B$3-$R3)^2+($C$3-$S3)^2+($D$3-$T3)^2+($E$3-$U3)^2+($F$3-$V3)^2+($G$3-$W3)^2+($H$3-$X3)^2+($I$3-$Y3)^2+($J$3-$Z3)^2+($K$3-$AA3)^2+($L$3-$AB3)^2+($M$3-$AC3)^2+($N$3-$AD3)^2+($O$3-$AE3)^2))
і далі, шляхом автозаповнення в 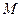 клітинок стовпчика В будуть записанівідповідні значення першого стовпчика матриці близькостей. В результаті в комірці В19 формула буде мати вигляд
клітинок стовпчика В будуть записанівідповідні значення першого стовпчика матриці близькостей. В результаті в комірці В19 формула буде мати вигляд
=КОРЕНЬ(СУММ(($B$3-$R4)^2+($C$3-$S4)^2+($D$3-$T4)^2+($E$3-$U4)^2+($F$3-$V4)^2+($G$3-$W4)^2+($H$3-$X4)^2+($I$3-$Y4)^2+($J$3-$Z4)^2+($K$3-$AA4)^2+($L$3-$AB4)^2+($M$3-$AC4)^2+($N$3-$AD4)^2+($O$3-$AE4)^2)),
тобто, номер і значення стрічок таблиці-оригіналу залишаться без зміни, а зміняться лише номери стрічок таблиці-копії. В результаті, буде визначено відстань між першим об’єктом, визначеним першою стрічкою таблиці-оригіналу, і кожним об’єктом, визначеним стрічкою таблиці-копії.
4. Для визначення відстані між другим об’єктом таблиці –оригіналу і всіма іншими об’єктами таблиці копії копіюють формулу з комірки В18 в комірку С18. Після активізації формули в цій комірці, змінюють адрес першої стрічки таблиці-оригіналу шляхом переміщення всіх кольорових рамок на одну комірку вниз. В результаті цього формула буде мати такий вигляд
=КОРЕНЬ(СУММ(($B$4-$R3)^2+($C$4-$S3)^2+($D$4-$T3)^2+($E$4-$U3)^2+($F$4-$V3)^2+($G$4-$W3)^2+($H$4-$X3)^2+($I$4-$Y3)^2+($J$4-$Z3)^2+($K$4-$AA3)^2+($L$4-$AB3)^2+($M$4-$AC3)^2+($N$4-$AD3)^2+($O$4-$AE3)^2)).
Реалізуємо цю формулу і шляхом автозаповнення формуємо другий стовпчик матриці близькостей. Аналогічно поступають при визначенні решти стовпчиків.
Зауваження. Якщо, виходячи з розмірності власних задач, побудувати матрицю близькостей для максимально можливих кількостей об’єктів і ознак, то використовуючи її як шаблон, можна знайти значення матриць близькостей для будь-якої кількості об’єктів і ознак, замінюючи в таблиці-оригінал і в таблиці-копії їхні значення і відкидаючи порожні комірки шаблону, отримуємо безпосередньо потрібну матрицю близькості. Іншими словами, маючи лист Ексель з один раз зробленою процедурою побудови матриці близькості можна в таблиці ввести інші дані і, відкидаючи лишні або дораховуючи нові стовпчики і стрічки безпосередньо отримати матрицю близькості, але для конкретної метрики.
Після формування останнього стовпчика отримуємо матрицю близькості зображену у вигляді табл. 3.
Таблиця 3.
Матриця близькостей
| Bur | Cub | Cup | Hav | Hod | Kol | Lob | Lot | Oli | Per | Pon | Sol | Syr | |
| Bur | 0,000 | 2,620 | 1,547 | 2,651 | 2,669 | 3,292 | 2,836 | 2,656 | 2,812 | 2,942 | 2,749 | 1,112 | 2,422 |
| Cub | 2,620 | 0,000 | 1,562 | 0,359 | 0,303 | 1,440 | 0,397 | 0,360 | 0,547 | 1,365 | 0,502 | 1,956 | 0,461 |
| Cup | 1,547 | 1,562 | 0,000 | 1,563 | 1,619 | 2,634 | 1,716 | 1,734 | 1,835 | 2,275 | 1,728 | 0,771 | 1,625 |
| Hav | 2,651 | 0,359 | 1,563 | 0,000 | 0,118 | 1,408 | 0,335 | 0,565 | 0,326 | 1,302 | 0,745 | 1,981 | 0,686 |
| Hod | 2,669 | 0,303 | 1,619 | 0,118 | 0,000 | 1,328 | 0,346 | 0,466 | 0,293 | 1,249 | 0,674 | 2,021 | 0,602 |
| Kol | 3,292 | 1,440 | 2,634 | 1,408 | 1,328 | 0,000 | 1,566 | 1,141 | 1,234 | 0,608 | 1,340 | 2,998 | 1,338 |
| Lob | 2,836 | 0,397 | 1,716 | 0,335 | 0,346 | 1,566 | 0,000 | 0,679 | 0,430 | 1,541 | 0,807 | 2,091 | 0,765 |
| Lot | 2,656 | 0,360 | 1,734 | 0,565 | 0,466 | 1,141 | 0,679 | 0,000 | 0,626 | 1,087 | 0,391 | 2,116 | 0,374 |
| Oli | 2,812 | 0,547 | 1,835 | 0,326 | 0,293 | 1,234 | 0,430 | 0,626 | 0,000 | 1,232 | 0,891 | 2,188 | 0,735 |
| Per | 2,942 | 1,365 | 2,275 | 1,302 | 1,249 | 0,608 | 1,541 | 1,087 | 1,232 | 0,000 | 1,226 | 2,695 | 1,307 |
| Pon | 2,749 | 0,502 | 1,728 | 0,745 | 0,674 | 1,340 | 0,807 | 0,391 | 0,891 | 1,226 | 0,000 | 2,174 | 0,649 |
| Sol | 1,112 | 1,956 | 0,771 | 1,981 | 2,021 | 2,998 | 2,091 | 2,116 | 2,188 | 2,695 | 2,174 | 0,000 | 1,890 |
| Syr | 2,422 | 0,461 | 1,625 | 0,686 | 0,602 | 1,338 | 0,765 | 0,374 | 0,735 | 1,307 | 0,649 | 1,890 | 0,000 |
Вибір стратегій об’єднання. Процедура кластерного аналізу основується на перерахунку значень матриці близькостей і, в результаті, кожного такого кроку обчислень об’єднуються об’єкти, об’єкт з групою або дві групи. Після кожного такого об’єднання розмірність матриці зменшується на одиницю, а кількість кластерів або кількість об’єктів в конкретному кластері збільшується на одиницю. Проте такі об’єднання відбуваються не будь як довільно, а в рамках конкретно вибраної стратегії, яка діє протягом усієї процедури. Зміст такої стратегії полягає в тому, що кожен новий кластер визначався значеннями ознак, отриманими в результаті перерахунку відповідних значень ознак об’єктів і кластерів, які об’єднуються в цей новий кластер. Іншими словами, процедуру об’єднання об’єктів в кластери можна подати так.
Суть стратегії групування полягає в наступному. У випадку 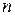 об'єктів обчислюються всі
об'єктів обчислюються всі 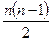 мір відмінностей і пара об'єктів з найменшою мірою об'єднується в одну групу. На наступному кроці визначають відповідну міру відмінності (нове значення близькості) між цією групою і рештою
мір відмінностей і пара об'єктів з найменшою мірою об'єднується в одну групу. На наступному кроці визначають відповідну міру відмінності (нове значення близькості) між цією групою і рештою 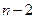 об'єктами, а на більш пізніх стадіях треба буде визначати цю міру між об'єктом і групою будь-якого об'єму, а також між будь-якими двома групами. На кожному кроці класифікації виконується те об'єднання (між двома об'єктами, між об'єктом і групою або між двома групами), для яких міра відмінності мінімальна серед всіх існуючих на даному кроці. Міра повинна бути такою, щоб об'єкт можна було розглядати як групу з одного елемента, Стратегія об'єднання визначається саме мірою відмінності між групами.
об'єктами, а на більш пізніх стадіях треба буде визначати цю міру між об'єктом і групою будь-якого об'єму, а також між будь-якими двома групами. На кожному кроці класифікації виконується те об'єднання (між двома об'єктами, між об'єктом і групою або між двома групами), для яких міра відмінності мінімальна серед всіх існуючих на даному кроці. Міра повинна бути такою, щоб об'єкт можна було розглядати як групу з одного елемента, Стратегія об'єднання визначається саме мірою відмінності між групами.
Нехай є дві групи  та з
та з 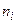 і
і 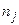 елементами відповідно; міру відмінності між цими групами позначимо
елементами відповідно; міру відмінності між цими групами позначимо  . Припустимо, що – найменша міра з усіх, що залишились, так що та об'єднуються і утворюють нову групу
. Припустимо, що – найменша міра з усіх, що залишились, так що та об'єднуються і утворюють нову групу 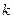 з
з 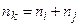 елементами. Розглянемо деяку іншу групу
елементами. Розглянемо деяку іншу групу 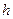 з
з  елементами. Перед об'єднанням відомі значення мір
елементами. Перед об'єднанням відомі значення мір 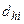 ,
, 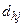 , та об'ємів , , . В роботі [6] значення розглянутих мір вираховують за формулою
, та об'ємів , , . В роботі [6] значення розглянутих мір вираховують за формулою
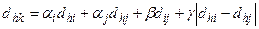 (6)
(6)
де параметри 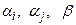 і
і 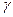 визначають суть стратегії.
визначають суть стратегії.
Найчастіше використовують наступні стратегії.
1. Стратегія найближчого сусіда. Відстань між двома групами визначається як відстань між двома найближчими елементами з цих груп. Ця стратегія монотонна і сильно стискає простір ознак, а її параметрами є 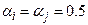 ,
, 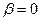 ,
, 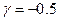 .
.
2. Стратегія найдальшого сусіда. Тут відстань між двома групами визначається як відстань між двома найбільш віддаленими представниками (елементами) цих груп. Вона монотонна і сильно розтягує простір. Її параметри мають значення , , 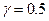 .
.
3. Стратегія групового середнього (середнього зв'язку). Якщо одна група складається з 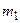 , а друга з
, а друга з 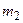 елементів, то відстань між цими групами в даній стратегії визначається як середнє арифметичне відстаней між елементами з цих груп. Ця стратегія монотонною і зберігає метрику простору. Параметри стратегії рівні:
елементів, то відстань між цими групами в даній стратегії визначається як середнє арифметичне відстаней між елементами з цих груп. Ця стратегія монотонною і зберігає метрику простору. Параметри стратегії рівні: 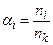 ,
, 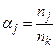 ,
,  .
.
4. Гнучка стратегія. Може бути застосована для будь-якої міри близькості і визначається наступними обмеженнями 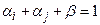 ,
, 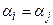 ,
, 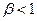 ,
, 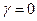 . Стратегія монотонна, а її властивості повністю залежать від
. Стратегія монотонна, а її властивості повністю залежать від 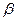 . Якщо , то стратегія зберігає метрику простору. Якщо
. Якщо , то стратегія зберігає метрику простору. Якщо 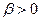 то стратегія стискає простір, а якщо
то стратегія стискає простір, а якщо 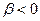 , то розтягує. Для практичного використання для параметрів приймають наступні значення
, то розтягує. Для практичного використання для параметрів приймають наступні значення 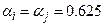 ,
, 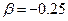 .
.
Об'єктами класифікації можуть бути практично будь-які об'єкти. Причому стратегії класифікації, тобто чисельні методи не залежать від природи об'єктів, що класифікуються, але різні стратегії, як правило, приводять до різних результатів. Тому вибір стратегії є досить складною задачею і вимагає високої кваліфікації від спеціаліста.
Дані, які підлягають класифікації, утворюють множину елементів, кожний з яких визначається набором ознак, які відповідають узагальненому поняттю змінної. Такі дані або множину даних вважають неоднорідними, тобто множину даних розглядають як сукупність підмножин, таких, що всередині підмножини її елементи між собою є більш подібними ніж з будь-яким іншим елементом будь-якою іншої підмножини. В цьому сенсі виділяють два підходи до аналізу. Перший є виясненням міри впевненості, що при використанні даної чисельної процедури можна вважати, що існують такі підмножини (тобто якщо їх не має, то і не повинно бути їх знайдено); другий – допускає, що істотних відмінностей підмножини не мають, проте для полегшення аналізу дані все таки треба розбити штучно.
В математичному плані задача класифікації даних тобто елементів формулюється як задача побудови розбиття елементів множини даних на деяке наперед задане чи відшукуване в ході аналізу число не порожніх попарно неперетинних підмножин (класів) елементів.
Проведення кластерного аналізу. Процедура, яка складає суть ієрархічної класифікації полягає в тому, що в матриці близькостей з двох об’єктів між якими найменша відстань формують перший кластер значення якого перераховують у відповідності з вибраною стратегією. Другий об’єкт з більшим номером стовпчика і стрічки викидається, а замість першого об’єкта (з меншим номером стовпчика і стрічки) вставляється утворений з цих об’єктів кластер з перерахованими значеннями. В результаті розмірність матриці зменшується на одиницю. На наступному кроці знову відшукують найменшу відстань між її елементами і поступають аналогічно. Коли матриця близькостей матиме розмірність 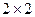 процедура кластеризації припиняється. На основі отриманої на кожному кроці інформації про об’єднання кластерів і знайдені значення мінімальних відстаней будується дендрограма і подається її інтерпретація.
процедура кластеризації припиняється. На основі отриманої на кожному кроці інформації про об’єднання кластерів і знайдені значення мінімальних відстаней будується дендрограма і подається її інтерпретація.
Суть цієї процедури полягає в тому, що: в матриці близькостей, в якій стовпці і стрічки є векторами пронумерованих об’єктів, шукають найменше значення, визначають які об’єкти відповідають цьому значенню і об’єднують їх в одну групу. Далі перераховують значення векторів цих об’єктів і подають цю групу як новий об’єкт зі своїм вектором значень.
Дана процедура реалізується за таким алгоритмом.
1. Знаходять в матриці близькостей найменше значення і об’єднують об’єкти, яким воно відповідає в одну групу.
2. Вилучаємо стовпчики, що належать цим об’єктам і розміщуємо їх, довільно і поряд, під матрицею близькостей. Залишаємо порожнім місце стовпчика першого (лівого) об’єкта і зсуваємо вліво всі стовпчики, що лежали справа від стовпчика другого об’єкта, тобто ліквідуємо порожне місце. Зсувом вгору ліквідуємо вектор стрічку другого об’єкта.
3. Вибираємо стратегію об’єднання об’єктів. Відповідно до вибраної стратегії значення вилучених стовпчиків перераховуємо за відповідною формулою. В даному прикладі використано гнучку стратегію з параметрами 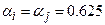 ,
, 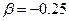 , оскільки ця стратегія за даного значення дещо розтягує простір, а отже і віддаляє між собою кластери, підкреслюючи їхні індивідуальності і однорідність.
, оскільки ця стратегія за даного значення дещо розтягує простір, а отже і віддаляє між собою кластери, підкреслюючи їхні індивідуальності і однорідність.
4. В отриманому в результаті перерахунку стовпчику шукають два найменших значення, які знаходяться в комірках, що відповідають коміркам з нулями перераховуваних стовпчиків і верхнє мінімальне значення замінюємо на нуль, а нижнє ліквідуємо зсувом вгору всіх нижче розташованих комірок в цих стовпчиках.
5. Перерахований стовпчик вставляємо на місце (порожне) першого вилученого стовпчика і перевіряємо чи його нуль лежить на головній діагоналі.
6. Копіюємо всі значення цього стовпчика, транспонуємо їх у стрічку і замінюємо нею стрічку першого вилученого стовпчика.
7. Присвоюємо новому об’єкту, утвореному в результаті об’єднання вилучених об’єктів, наступний за порядком номер. В результаті цієї операції матриця близькості зменшується на один стовпчик і одну стрічку і в ній з’являється новий об’єкт.
8. Дану процедуру повторюють до тих пір поки матриця не зменшиться до розміру . Результати кластерного аналізу наведені в табл. 4.
Таблиця 4.
Результати кластерного аналізу операторського персоналу
| Процедура об’єднання кластерів | |||
| Кроки | Об’єднання | Вузол | Метрика |
| 4+5 | d14 | 0,118 | |
| 14+9 | d15 | 0,357 | |
| 2+8 | d16 | 0,36 | |
| 15+7 | d17 | 0,427 | |
| 16+13 | d18 | 0,432 | |
| 18+11 | d19 | 0,59 | |
| 6+10 | d20 | 0,608 | |
| 3+12 | d21 | 0,771 | |
| 19+17 | d22 | 1,038 | |
| 1+21 | d23 | 1,469 | |
| 22+20 | d24 | 2,368 | |
| 23+24 | d25 | 5,059 |
Побудова дендрограми. Візуалізація результатів кластерного аналізу здійснюється з допомогою дендрограми, тобто графічного зображення результатів процесу послідовної кластеризації, яку проводять в термінах матриці близькостей. За допомогою дендрограми можна графічно або геометрично зобразити процедуру кластеризації за умови, що ця процедура оперує тільки з елементами матриці відстаней або подібності. 3 Вид дендрограми залежить від вибору міри подібності або відстані між об'єктом і кластером і методу кластеризації. Найбільш важливим моментом є вибір міри подібності або міри відстані між об'єктом і кластером.
Не дивлячись на те, що на даний час, існує досить велика кількість різноманітних програмних засобів проведення кластерного аналізу, наприклад, ППП «Statistica» та SPSS, а також різних додатків до статистичних пакетів програм обробки даних їх використання часто є дуже складним в сенсі знаходження найбільш відповідного, його придбання, узгодження з використовуваними засобами тощо.
Проте побудова дендрограми кластеризації декількох десятків об’єктів легко може бути здійснена вручну безпосередньо або за дві три ітерації в чорновому варіанті і остаточно сформована в, практично, будь якому графічному середовищі.
Процедура побудови дендрограми вручну є нескладною і потребує лише уважності, використовує результати кластерного аналізу приведені в табл. 4, складається з побудови ескізу, на підставі якого здійснюється її графічне редагування та масштабування відстаней між між об’єктами і вузлами і включає такі кроки.
1. Побудова ескізу дендрограми. Дендрограму будують починаючи з «кореня дерева», тобто з вузла останнього об’єднання, відобразивши його точкою, відміченою його номером.
2. Оскільки кластерний аналіз є дихотомічною процедурою з кореневого вузла проводять дві гілки, які закінчуються точками наступних вузлів. Помічаються номери вузлів.
3. Якщо гілка закінчується на об’єкті то її кінець помічають номером відповідного об’єкта, якщо ж вузлом, то вказують відповідний йому номер.
4. Після того, як визначені всі гілки і помічені усі об’єкти здійснюють графічну корекцію і масштабування. Для цього в декартовій системі координат по осі абсцис відкладають значення відстаней об’єднання об’єктів, об’єктів з групами та груп, а гілки будують прямими лініями, довжини яких відповідають значенням відстаней.
В результаті отримують дендрограми зображені на рис. 1.
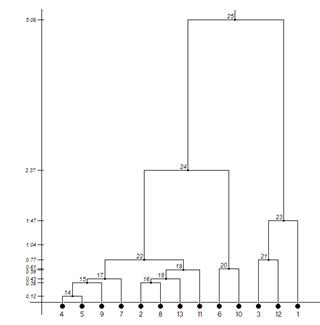
Рис. 1. Дендрограми.
Інтерпретація дендрограми. Проведення горизонтальних ліній в площині дендрограми на заданій висоті, в даному випадку, дозволяє виділити окремі кластери. Вже з першого погляду на наведену дендрограму можна вказати, що на рівні 0.75 маємо в принципі шість досить чітко відображених кластерів, в які входять такі об’єкти.
1 кластер – об’єкти 4, 5, 9, 7;
2 кластер – об’єкти 2, 8, 13, 11;
3 кластер – об’єкти 6, 10;
4 кластер – об’єкт 3;
5 кластер – об’єкт 12;
6 кластер – об’єкт 1;
На рівні 1.0 маємо 4 кластери.
1 кластер – об’єкти 4, 5, 9, 7, 2, 8, 13, 11;
2 кластер – об’єкти 6, 10;
3 кластер – об’єкти 3, 12;
4 кластер – об’єкт 1;
На рівні 1.5 отримуємо три кластери, в які входять такі об’єкти:
1 кластер – об’єкти 4, 5, 9, 7, 2, 8, 13, 11;
2 кластер – об’єкти 6, 10;
3 кластер – об’єкти 3, 12;
|
|
|
|
|
Дата добавления: 2015-05-24; Просмотров: 1411; Нарушение авторских прав?; Мы поможем в написании вашей работы!