КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Постановка задачи проектирования естественно-языкового диалогового интерфейса
 |
ЕСТЕСТВЕННО-ЯЗЫКОВЫЙ ИНТЕРФЕЙС – это совокупность программных и аппаратных средств, обеспечивающих общение интеллектуальной системы с пользователем на ограниченном рамками проблемной области естественном языке.
Система естественно-языкового интерфейса.
В настоящее время проблема общения с компьютером на естественном языке весьма далека от своего решения. Современные средства естественно-языкового интерфейса далеки от универсальных возможностей человеческой коммуникации.
В состав Е.Я. И. входят словари, отражающие словарный состав и лексику языка, а также лингвистический процессор, осуществляющий анализ текстов (морфологический, синтаксический, семантический и прагматический) и синтез ответов пользователю.
В идеале СЕЯИ должно удовлетворять следующим требованиям:
· обеспечивать вход и выход системы в виде естественного языка;
· обеспечивать обработку входных данных и генерацию выходных, основываясь на знании относительно синтаксических, семантических и прагматических аспектов естественного языка.
Задача создания естественно-языкового интерфейса может быть рассмотрена как две взаимодействующие подзадачи.
Первая часть - это взаимодействие интерфейса с пользователем. Здесь непосредственно должен быть реализован алгоритм понимания смысла того, что сообщает пользователь. То есть должно быть реализовано множество выражений, которые пользователь может сказать, а система таким образом должна понять.
Вторая основная подзадача - интерфейс должен конвертировать смысл сказанной фразы в какое-либо внутреннее представление. Это может быть уже существующий язык, например, Пролог, VBScript. Это может быть какое-либо свое внутреннее представление. Представление во внутренних кодах нужно для понимания смысла запроса пользователя и трансляции этого смысла в запросы SQL. После формирования запроса во внутреннем представлении необходимо представить информацию на языке, понятном для базы данных. Таким образом, происходит трансляция в SQL.
|
|
|
Выше изложен только механизм обращения к базе данных. Возврат информации осуществляется в обратном порядке. База данных на запрос отвечает множеством записей из базы данных. Результат транслируется во внутреннее представление, затем во фразы естественного языка и выдается пользователю как ответ. Затем пользователь снова обращается и так далее.
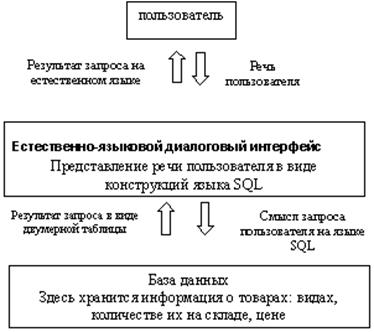
Рис. 1. Порядок работы естественно-языково интерфейса.
Необходимо отметить, что в задачи естественно-языкового диалогового интерфейса входит лишь осуществление связи между пользователем и базой данных. Результаты запросов формирует сама база данных, а интерфейс лишь преобразовывает их в естественный язык.
Итак, концептуальное решение задачи заключается в создании такой системы. Конечно же, это лишь первое приближение к подобному вопросу. Очень важен выбор метода представления естественного языка, способы отражения смысла задачи, классификация задач и многое другое. Все это будет обсуждаться ниже. На данном этапе важно разработать алгоритм взаимодействия естественно-языкового диалогового интерфейса с пользователем и базой данных, и понять, что он должен обеспечивать корректную работу с каждой стороной.
В настоящее время на рынке программного обеспечения представлено много программ распознавания и синтеза речи. Над этой проблемой работают многие ведущие мировые компании, такие как L&H, Dragon, IBM и др. Успехи в данном направлении являются отправной точкой для более высокого уровня общения человека с компьютером, а именно, диалога человека с компьютером на естественном языке.
|
|
|
Таким образом, перед разработчиками голосовых интерфейсов ставится задача понимания естественной речи. Более точно, понимание смысла сказанного. Именно понимание смысла фраз пользователя позволяет строить диалоги и с помощью диалогов решать задачу более высокого уровня, задачу понимания цели, которой хочет достигнуть пользователь.
Построение диалогов определено многими причинами. Пользователь не всегда может четко сформулировать цель, или не предоставить необходимые данные для решения поставленной задачи (цели пользователя), или предоставить неверные данные, и т.д.
Для определения цели, которой хочет достигнуть пользователь, или другими словами, какую задачу он ставит системе, разрабатываются различные интерфейсы. Самым распространенным на сегодняшний день, является всем хорошо знакомый – графический пользовательский интерфейс, или GUI. Этот интерфейс обеспечивает ввод данных в компьютер, вызов нужных приложений, предоставление информации пользователю и многое другое. Но как бы он не выглядел привычно, он не является удобным с точки зрения естественного человеческого общения, когда одним из самых важных каналов предоставления и получения информации является голос.
Сейчас многие компании занимаются созданием так называемых голосовых пользовательских интерфейсов (sound user interface) или SUI, в основе которых лежит решение проблемы понимания смысла пользовательской фразы.
Мы не будем говорить о проблемах распознавания речи, о достоинствах и недостатках этих систем. К сожалению, ошибки распознавания есть и всегда будут. Но для нашей работы, отправной точкой будет считаться тот факт, что фраза распознана, то есть речевой поток трансформирован в строку символов. И на самом деле, для нас не важно, как появилась эта строка символов, в результате работы программы распознавания, или пользователь ее ввел с клавиатуры. Для нас важно одно, как понять смысл фразы, которая содержится в строке.
Термин “понимание смысла“ мы будем интерпретировать как процесс трансляции фразы пользователя в некоторое адекватное действие, совершаемое системой.
Если говорить о системах понимания естественной речи или NLU-ситемах, то можно выделить два типа таких систем:
|
|
|
а) командные системы (command control). Этот тип NLU-системы интерпретирует единичную фразу пользователя в набор конечных команд, которые выполняются компьютером. С помощью таких систем строится голосовое управление компьютерными приложениями, например, Microsoft Word. Эти системы полностью содержат в себе команды управления конкретным приложением и транслируют голосовые команды пользователя в команды управления приложением. Следующий пример показывает работу системы command control.
Пример:
ПОЛЬЗОВАТЕЛЬ: Открыть Microsoft Word.
КОМПЬЮТЕР: Запускает приложение Microsoft Word.
ПОЛЬЗОВАТЕЛЬ: Открыть File.
КОМПЬЮТЕР: Открывает диалоговое окно открытия файла.
ПОЛЬЗОВАТЕЛЬ: Изменить путь.
КОМПЬЮТЕР: Изображает дерево изменения директорий.
И т.д.
ПОЛЬЗОВАТЕЛЬ: Выйти.
КОМПЬЮТЕР: Закрывает приложение Microsoft Word.
б) диалоговые системы (dialog system). Эти системы более широко интерпретируют понятие естественного языкового общения и в своей основе содержат диалог пользователя с компьютером для выяснения конечной цели, которую хочет достичь пользователь и получения от него необходимых данных для решения поставленной задачи.
Пример:
ПОЛЬЗОВАТЕЛЬ: Я хотел бы поехать в Киев.
DS: Каким транспортом вы бы хотели воспользоваться?
ПОЛЬЗОВАТЕЛЬ: Конечно, лучше поездом.
DS: Каким транспортом вы бы хотели воспользоваться?
ПОЛЬЗОВАТЕЛЬ: Конечно, лучше поездом.
DS: Когда вы хотите быть в Киеве?
ПОЛЬЗОВАТЕЛЬ: 25 декабря.
DS: Перечисляет возможные рейсы и просит выбрать нужный
ПОЛЬЗОВАТЕЛЬ: Сообщает нужный рейс.
…
DS: После того как получена полная информация, бронирует билет.
Как видно из данного примера, что в течение диалога, DS может работать не с одним, но несколькими приложениями, как базой данных движения поездов, наличием мест, бронированием билетов и т.д.
Система command control понимает фразы естественного языка только лишь как набор команд. Поэтому в ее задачи не входит понимание смысла фразы пользователя. Система такого типа должна лишь сопоставить фразу пользователя с тем множеством фраз, которые заложены внутри нее, и при совпадении выполнить требуемое действие. Конечно, в этом случае можно говорить лишь об управлении с использованием ограниченного числа команд, представленных на естественном языке.
|
|
|
При работе с системы. DS используется абсолютно иной подход. Здесь система нацелена на понимание смысла сказанного. Это возможно благодаря использованию некоторой логической структуры, на которую отображается речь пользователя.
Совершенно очевидно, что любой тип NLU системы оперирует со смыслом пользовательских фраз. Существует несколько теорий определения смысла языковых фраз. Это и попытки отображения пользовательской фразы на семантическую модель представления мира, и попытки определения смысла путем разложения фразы на части речи и анализа структуры фразы (так называемая tag/chunk технология, которая определяет части речи фразы –tags, а затем смысловые куски -chunks, но не определяет смысл фразы в нашем понимании и хороша для разработки компьютерных переводчиков) и др.
Для представления естественного языка при разработке данного интерфейса использовалась теория грамматик. Предпосылки для использования именно этого способа представления естественного языка следующие:
В случае построения command control системы, пользователь произносит ограниченное множество фраз, определенное свойствами того приложения, которым он в данный момент управляет. Другими словами, это только те фразы, которые содержат в себе команды управления текущим приложением.
В случае построения DS системы, пользователь может произнести также ограниченное множество фраз, определенное предметом диалога и текущим состоянием диалога. Т.е., трудно себе представить, что, когда речь идет о бронировании билетов на самолет (предмет диалога) и система ожидает ответа о количестве билетов (текущее состояние диалога), пользователь может задать вопрос о здоровье лидера какого-нибудь политического движения. Хотя и такое возможно, но система будет считать это ошибкой и попытается вернуть пользователя в нужное русло диалога.
Всякое множество фраз можно описать с помощью грамматики, которая определяет набор слов, из которых строятся фразы и способы построения возможных фраз. Можно, конечно, иметь полный список возможных фраз, но такая система будет громоздкой и не эффективной, а также довольно трудно модифицируемой. Например, в случае разработки диалога, связанного с продажей напитков, трудно себе представить как можно дополнять такой список фраз в случае поступления новых типов и наименований напитков. Это не только добавление новых слов, но и генерация всех возможных фраз, в которых может встречаться новое слово. С этой задачей успешно справляется грамматика, поскольку оперирует с понятием правил построения фраз, а не только со значениями слов. Далее, при описании грамматики, это станет понятней.
С помощью грамматики можно выделять подмножество фраз, которые ожидаются от пользователя в текущий момент. Так называемые правила грамматики, которые содержат подмножества фраз и активизируются в нужный момент, в зависимости от текущего состояния диалога или активизации того или иного приложения.
С помощью грамматики, можно построить соответствие между каждой фразой пользователя и выходной грамматикой. Выходная грамматика – это фраза, содержащая набор команд (или одну команду), которая будет передана в соответствующее приложение для выполнения. Если в результате парсирования (анализа) входной фразы (фразы пользователя) была получена выходная фраза (тот самый набор команд), мы считаем, что смысл пользовательской фразы понят. Здесь следует отметить, что выходная грамматика может содержать не только команды управления конкретным приложением (что хорошо для систем command control), но и командные строки, которые могут передаваться в некую диалоговую систему для отображения текущего состояния диалога и передачи данных в диалоговую систему. Другими словами, фраза пользователя транслируется в некоторую строку, которая в свою очередь передается в нужное приложение (с точки зрения грамматики, DS является тоже приложением) и является для него понятным.
Для лучшего понимания закономерностей построения грамматики необходимо привести некоторые определения теории построения грамматик. Прежде всего, необходимо ввести понятие алфавита.
Алфавит – любое множество символов. Алфавит не обязан быть конечным и даже счетным, но во всех практических приложениях он будет конечным. Например, латинский алфавит – множество, состоящее из 26 строчных и прописных букв. Термины “буква” и “знак” будут использоваться как синонимы термина “символ” для обозначения элемента алфавита. При расположении символов одного за другим, получаем последовательность – цепочку символов или “лексему”. Термины “предложение”, “слово”, “строка” – синонимы термина цепочка. При этом следует учесть существование пустой цепочки (мы будем обозначать ее символом е*).
Формально цепочки в алфавите Е* можно определить таким образом: е* - цепочка в Е*; если х – цепочка в Е* и а принадлежит Е*, то ха – цепочка в Е*; у – цепочка в Е* тогда и только тогда, когда она является такой в силу предыдущих двух пунктов. Возможны такие операции над цепочками, как конкатенация (сцепление) цепочек, обращение (запись последовательности в обратном порядке), выделение префиксов и суффиксов.
Итак, мы вплотную подошли к определению языка.
Язык в алфавите Е* - множество цепочек в алфавите Е*. Под это определение подходит почти любое определение языка. При этом необходимо учесть, что пустое множество – язык; множество {e*}, содержащее только пустую цепочку, - тоже является языком. При этом пустое множество и множество {e*}являются различными языками. Так как языки, по сути, есть множества, то к ним применимы все операции, применимые к множествам.
Проблемой естественных языков является то, что все они – контекстно-зависимы. То есть для эффективного ведения диалога, системе недостаточно просто знать ответ пользователя, а нужно также хранить информацию о предыдущих ответах и получать информацию от внешнего мира.
Информация от внешнего мира должна учитываться в связи с тем, что многие слова многозначны и смысл их зависит в значительной степени от окружающего мира. То есть, чтобы определить смысл и структуру предложения, необходимо исследовать все окружение: окружающие отношения, свойства предмета и даже информацию о говорящем.
Идея подхода к ведению естественно-языкового диалога с машиной заключается в выборе узкоспециализированной области, что позволяет информацию, которую можно извлечь из предложений естественного языка, представить в виде древовидной структуры. Этот подход охватывается понятием контекстно-свободных грамматик. А уже расширение возможностей диалогового интерфейса возможно при подключении различных грамматик.
Грамматика – математическая система, определяющая язык. В грамматике, определяющей язык L, используют два конечных непересекающихся множества символов – множества нетерминальных символов (множество N’) и множество терминальных символов – Е*. Терминальные символы определяют цепочки языка (слова). Множество же N’ служит для определения синтаксических переменных.
Сердцевину грамматики определяет конечное множество Р правил образования, которые описывают процесс порождения цепочек языка. Неформально, нетерминал можно рассматривать как переменную, которая может принимать значения цепочек терминалов. Язык, определяемый грамматикой, - это множество цепочек языка, состоящих только из терминальных символов.
Итак, грамматика есть четверка G=(N, E, P, S) где: N – конечное множество нетерминалов; E – непересекающееся с N множество терминалов; Р – конечное множество правил (элемент (а,b) множества Р есть правило и записывается в виде а->b); S – выделенный символ из N, называемый начальным символом. Необходимо отметить, что грамматика определяет язык рекурсивным образом.
Грамматика состоит из:
· слов (это так называемый алфавит);
· опций (еще одно свойство этой грамматики - опциональность), т.е. выражения, заключенные в квадратные скобки являются опцией и могут произноситься пользователем, а могут и нет. Например, из нашей грамматики: [Can I talk with] <person>, может быть произнесено полностью фраза, а может быть названо только имя персоны;
· правил (rules). Это выражения, заключенные в угловые скобки <> и написанные маленькими буквами, но вне фигурных скобок {}. Правила содержат в себе те фразы, которые могут быть произнесены в текущий момент диалога, то есть имеется возможность делать активными те или иные правила, что бы таким образом ограничить множество входных фраз и таким образом улучшить понимание фразы;
· выходных грамматик. Т.е. выражений, которые являются результатом парсирования (трансляции, понимания) фразы. В нашем случае – эти выходные грамматики написаны на языке диалогового enginу’a и содержат команды управления диалогом. В принципе здесь может быть все, что угодно, главное, чтобы принимающая выходные грамматики программа это понимала;
· переменных выходных грамматик. Выражения, заключенные в <>, написанные большими буквами и находящимися внутри выходных грамматик (внутри {}). Они с точки зрения грамматики бесполезны, но нужны для парсирования.
Другими словами, разработчик должен представить себе все возможные диалоги, затем представить все возможные фразы пользователя в рамках решаемой задачи, сгруппировать эти фразы по группам, которые будут представлены на каждом этапе диалога, попытаться определить правила построения фраз и таким образом построить грамматику “естественного языка”, но только для совершенно конкретной предметной области (в нашем случае торговля напитками). Можно, конечно иметь и много грамматик, разбивая на подмножества решаемую задачу, и в нужный момент их переключать.
Важно уяснить себе, что в нашей технологии грамматика строится для конкретного диалога и определяет набор слов, которые могут употребляться, и правила построения фраз из этого набора слов. Это совсем не перечисление всех возможных фраз (хотя может быть и такой подход), но перечисление правил построения фраз. Это очень важно. Эти правила определяет разработчик, и от того, насколько он хорошо их построил, будет зависеть качество диалога. Задача не простая, но вполне решаемая. Нужно определить какую-то очень узкую предметную область, чтобы можно было построить эффективное приложение, не нагружая себя разработкой очень сложных диалогов и грамматик.
База знаний для СЕЯИ должна интегрировать следующие виды знаний.
Лингвистические знани я — касаются широкого круга аспектов, начиная от обработки эллипсиса до понимания речевого акта для кооперативного дискурса.
Концептуальное знание означает, что существует фрагмент реальности, релевантный диалогу. Одна из причин, почему СЯЕИ для доступа к базе данных были сравнительно успешными, заключается в том, что концептуальные знания предметной области базы данных являются ясными и хорошо определенным.
Инференциальное знание — относится к правилам базы знаний, подобным экспертной системе, основанной на правилах, которая работает на  фактуальных и концептуальных знаниях, чтобы вывести имплицитные факты или правила из хранимых данных.
фактуальных и концептуальных знаниях, чтобы вывести имплицитные факты или правила из хранимых данных.
Модель пользователя описывает знание системы относительно стереотипов различных категорий пользователей, которые могут использовать СЕЯИ, включая аспекты образования, опыта, истории диалога или целей. Структура программного комплекса СЕЯИ очень сложная; она представлена на рис. 3.7.
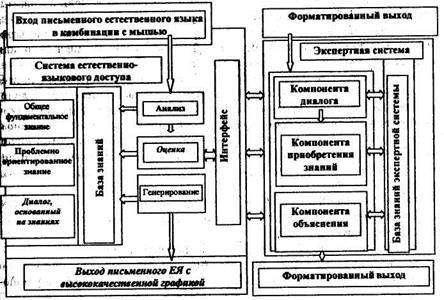
Рис. 3.7. Место СЕЯИ в интеллектуальной информационной системе
|
|
|
Дата добавления: 2015-05-26; Просмотров: 979; Нарушение авторских прав?; Мы поможем в написании вашей работы!