КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Код Хаффмана
|
|
|
|
Алгоритм кодирования Хаффмана заключается в следующем.
Все сообщения располагаются в порядке убывания вероятности их появления. В случае равной вероятности сообщений на первое место в списке ставится сообщение с меньшим порядковым номером.
В полученном упорядоченном ансамбле сообщений выбираются два сообщения с наименьшими вероятностями их появления. Одному из них (с большей вероятностью) в качестве элемента кодовой комбинации приписывается «1», а другому (с меньшей вероятностью) в качестве элемента кодовой комбинации приписывается «0». Выбранные сообщения объединяют в “промежуточное” сообщения, вероятность которого равна сумме вероятностей объединяемых. Это “промежуточное” сообщение помещают в списке сообщений на место, соответствующее его вероятности. При равенстве вероятностей, как правило, в списке сначала помещают отдельное сообщение, а “промежуточное” после. Потом снова выбирают два сообщения с наименьшими вероятностями и выполняют вышеописанную процедуру. Такой процесс объединения и присвоения значений элементам кода продолжается до тех пор, пока не будет получено одно объединенное сообщение, вероятность которого равна 1. Если получилось больше или меньше единицы, то это означает, что либо была допущена ошибка при суммировании, либо исходные данные некорректны.
Графическое отображение описанного процесса называется графом кода или деревом кода. Кодовая комбинация, соответствующая какому-либо сообщению строится путем обхода по линиям графа кода слева направо и записи элементов кода слева направо, начиная от сообщения для которого эта комбинация строится.
Рассмотрим пример.
Дискретный источник выдает сообщения из ансамбля {Xj}, где j = 1, 2, …, 10 с вероятностями, приведенными в таблице
|
|
|
| Xj | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 |
| P(xj) | 0,25 | 0,12 | 0,10 | 0,06 | 0,03 | 0,02 | 0,05 | 0,12 | 0,17 | 0,08 |
Закодировать данные сообщения кодом Хаффмана. Определить среднюю длину кодовой комбинации, количество информации, содержащееся в одном элементе кода, минимальную длину кодовой комбинации и избыточность кода. При определении минимальной длины кодовой комбинации следует воспользоваться приближенной формулой.
Решение.
Построение графа кода
| код | 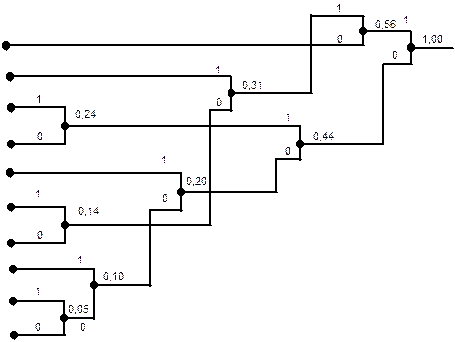
| |
| X1 | 0,25 | |
| X9 | 0,17 | |
| X2 | 0,12 | |
| X8 | 0,12 | |
| X3 | 0,10 | |
| X10 | 0,08 | |
| X4 | 0,06 | |
| X7 | 0,05 | |
| X5 | 0,03 | |
| X6 | 0,02 |
Определение энтропии источника
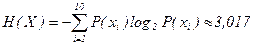 бит
бит
Определение средней длины кодовой комбинации
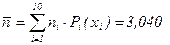 элемента
элемента
Определение среднего количества информации, приходящейся на один элемент кода
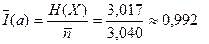 бит/элемент
бит/элемент
Определение минимальной средней длины кодовой комбинации
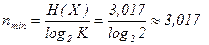 элемента
элемента
Определение избыточности кода
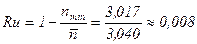
Алгоритм создания кода Хаффмана называется методом “снизу-вверх”, а Шеннона-Фано – методом “сверху-вниз”. Анализ результатов приведенных примеров позволяет сделать вывод, что эффективность полученных кодов одинакова. Однако, это частный случай. В общем случае метод Хаффмана является более эффективным. И при определенном распределении вероятностей в ансамбле сообщения может давать лучший результат, чем метод Шеннона-Фано.
Преимуществами данных методов кодирования являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования и декодирования.
Статистическим кодам свойственны недостатки оптимальных кодов, т.е. наличие ошибки в кодовой комбинации не может быть определено на приемной стороне. Поэтому при использовании таких кодов необходимы качественные каналы передачи информации.
Не следует думать, что квазиоптимальные коды представляет число теоретический интерес. Метод Хаффмана и его модификация – метод адаптивного кодирования (динамическое кодирование Хаффмана) – нашли широчайшее применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.
|
|
|
|
|
|
|
|
Дата добавления: 2015-07-01; Просмотров: 1518; Нарушение авторских прав?; Мы поможем в написании вашей работы!