КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Конвейерное выполнение команд
Алгоритм обратной записи
Алгоритм сквозной записи
Каждый раз при появлении запроса на запись по некоторому адресу обновляется содержимое области по этому адресу как в быстрой, так и в основной памяти. Такое постоянное обновление содержимого основной памяти, как и буфера, при каждом запросе на запись позволяет постоянно поддерживать информацию, находящуюся в основной памяти, в обновленном состоянии.
Эта схема записи повышает производительность системы памяти, так как в ней обращения к основной памяти не происходят при каждом запросе на запись, что имеет место при использовании алгоритма сквозной записи. Однако в связи с тем, что содержимое основной памяти не поддерживается в постоянно обновленном состоянии, если необходимого слова в быстром буфере не обнаруживается, из буфера в основную память надо возвратить какое-либо устаревшее слово, чтобы освободить место для нового необходимого слова. Поэтому из буфера в основную память сначала пересылается какое-то слово, место которого занимает в буфере нужное слово. Таким образом, происходят две пересылки между быстрым буфером и основной памятью.
Конвейерный принцип состоит в разделении выполнения команд на этапы и в параллельном выполнении разных этапов разных команд.
Пример. Выборка, декодирование, исполнение:
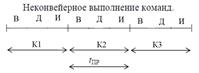
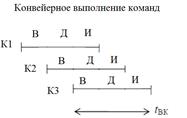
tBK – время выполнения команды, tПР – интервал между проявлением результатов.
Время выполнения команды при конвейере остается таким же, как и без использования конвейеризации, существенно сократится время м/у появлением результирующих команд в идеале до такта. Это позволяет при одинаковом технологическом процессе увеличить быстродействие.
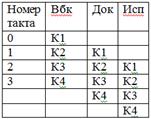
Условия максимальной эффективности работы конвейера.
Одинакова длина команд согласования по разрядности с выборкой.
В современных процессорах это условие является необязательным и с его отрицательными последствиями борются введением дополнительных ступеней, называемых предвыборкой.
В программе должно быть как можно меньше условных переходов. Проблема в том, что адрес, следующий за командой условного перехода команды, становится точно известен только на этапе ее исполнения, к этому времени уже нужно произвести выборку следующих команд.
Для борьбы с этим недостатком используют предсказание переходов. Для предсказания используется статистика. Простейший вариант предсказаний циклов при первом проходе делается запись в спец. буфере, что с этого адреса был переход на другой адрес. При следующих выборках этой команды переход предполагает, что переход будет по тому же адресу.
В современ. процессорах используется сложная методика, учитывается вероятность перехода. Эффективность предсказания достигает 95% и более.
Иногда при работе конвейера возникают конфликты, если несколько ступеней пытаются одновременно использовать один ресурс. Доступ к внешней памяти конфликт. с выборкой следующей команды. Если в процессоре нет механизма внеочередного исполнения.
21. Архитектура цифровых сигнальных процессоров (ЦСП): CISC и RISC процессоры, основные особенности; отличия ЦСП с фиксированной и плавающей точкой. Классификация ЦСП (краткое перечисление типов).
CISC и RISC процессоры, основные особенности
RISC = Reduced Instruction Set Computer
CISC = Complex Instruction Set Computer
Первые RISC-процессоры имели один тип RISC-команд.
Современные CISC-процессоры часто имеют декодеры, транслирующие их родные команды в RISC-подобные.
Особенности:
1.регистр общего назначения (РОН) >16;
2.ограниченное число типов команд (р. – регистр, п. – память)
а) р.р. → р.;
б) р. → п.;
в) п. → р.
3.ограниченное число вариантов длин команд;
Отличия ЦСП с фиксированной точкой (ФТ) и плавающей точкой (ПТ)
Достоинства ЦСП с ПТ:
1.больше динамический диапазон;
2.нет необходимости в масштабировании => проще алгоритмы;
3.больше поддерживаемых типов данных.
Процессоры с ФТ выпускаются, т.к. они проще (=> дешевле) и потребляют меньше энергии.
Процессоры с ФТ эффективнее для производства; с плавающей точкой – для программистов.
Основные типы ЦСП
Классификация по историко-функциональному признаку.
1.стандартные (conventional);
2.улучшенные стандартные (enhanced conventional);
3.суперскалярные (superscalar);
4.с очень длинным командным словом (VLIW).
22. Классификация ЦСП: стандартные ЦСП, улучшенные стандартные ЦСП.
Стандартные
1. TI (TMS 3202х12хх/24х/5х)
Texas Instrument – первые ЦСП 1982 г. Два варианта выполнения команды умножения с накоплением.
1)Оба сомножителя в памяти данных, 2 такта (умножения с накоплением)
2)1 сомножитель в ПП, 2 сомножителя в ПД, 1 такт (умножения с накоплением)
Команда выбирается один раз в самом начале и хранится в регистре. Традиционно для проверки окончания цикла используется отдельная команда. В ЦСП можно задать перед выполнением цикла его граничные адреса и число повторений. Проверка условий окончания цикла будет вестись параллельно с выполнением команд в цикле и не потребует дополнительных пакетов.
2. ADSP – 21хх Analog Devices
Реализация умножения с накоплением аналогична 2му варианту TI.
3. DSP56000 Motorola (Freescale)
Память данных поделена на 2 банка X и Y с определенными шинами данных, что позволяет выбирать каждый такт по 2 сложения из ПД.
Улучшенные
В рамках поколения стандартных процессоров, увеличение производительности достигалось в основном увеличением тактовой частоты. Дальнейшее увеличение производительности достигалось за счет одного из 2х факторов: 1) увеличение числа операций выполняемых одновременно; 2) увеличение числа команд выполняемых одновременно.
В улучшенных стандартных ЦСП используется 1ый порядок. В них увеличение числа операций выполняемых одновременно достигается за счет: а) увеличения числа функциональных модулей, умножителей, сумматоров и т. д.; б) добавления специализированных проблемно-ориентированных блоков (модулей), декодеры, циклических ходов, сопроцессоры для обработки видеоинформации; в) увеличение разрядности; г) усложненная система команд.
Перечисленные меры традиционны для ЦСП поэтому не всегда можно провести четкую границу м/у стандартными и улучшенными.
Пример TI(TMS5320C55x) 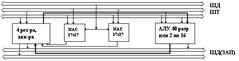
2 блока умножения с накоплением (MAC 17х17) могут получать операнды по всем 3м шинам, но при параллельной работе 1 операнд будет общим
Пример
Использование общего сомножителя можно свести многие задачи ЦОС: 1) фильтр с симметричным коэффициентом КИХ в качестве общего сомножителя выступают коэффициенты, такие фильтры имеют линейную ФЧХ, не искажают форму сигнала. В итоге время вычисления фильтра сокращается в 2 раза по сравнению со стандартными ЦСП;
2) Многоканальная обработка сигнала с частотными разделениями. Если нужно выделить из группового сигнала, сигналы отдельных каналов, то общим сомножителем будет групповой сигнал, разными коэффициентами фильтров. ADSP-2116Х
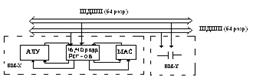
23. Классификация ЦСП: суперскалярные процессоры, процессоры VLIW.
|
|
Дата добавления: 2015-07-02; Просмотров: 2936; Нарушение авторских прав?; Мы поможем в написании вашей работы!