КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Идеология организации без упорядоченного выполнения 3 страница
|
|
|
|

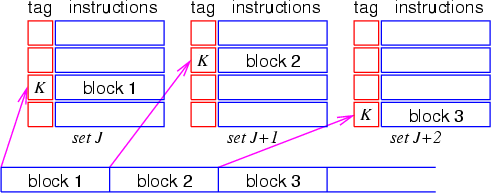
Рис. Пример отображения последовательных блоков инструкций на наборы
классического I-кэша (все блоки имеют одинаковые старшие разряды адреса
и, как следствие, соответствующие им наборы кэша имеют одинаковые тэги)
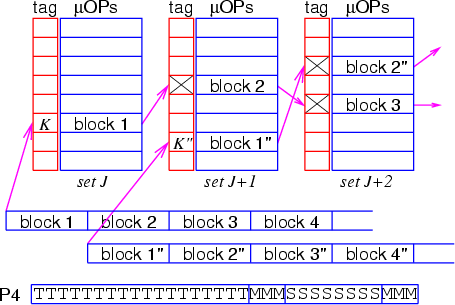
Рис. Организация хранения трасс в Т-кэше
Краткая характеристика Power 4.
Начало направления RISC архитектуры IBM было положено с RISC System 6000 в 1990
Являющейся приемственником серии e Server p Series.
Начальная модель процессора функционировала в области частот от 20Мгц до 30Мгц. В 1993 году pow2 был разработан, работающ. В области частот от 55Мгц до 71,5Мгц и выполняет до 6 инструкций за цикл (такт).
Параллельно был анонсирован в этом же году pow601, явившийся как результат совместной разработки IBM, APL b Motorola, Texas.
Все вышеуказанные микропрограммы были 32х разр. Архитектуры. Начиная с RS64 анонсированного в 1997 году и pow3. В 1998 начинается эпоха 64х разрядных архитектур.
Микропроцессоры класса RS64, RS64=2,3,4 през. Запись для коммерческих приложений.
RS64 вначале работали на частоте 125Мгц. Более поздние разработки RS64 - 4 функционирующий на частоте 750Мгц.
Power - 3 был презентован (оптимизирован) для технологических приложений, работающих изначально на частоте 200Мгц. В дальнейшем модифицирован до 450Мгц.
Power - 4 был разработан для использования как в коммерческих так и в технологических приложениях. Power – 4 был сконструирован в манере Power PC архитектуры.Изначально заложили для работы на частоте 1,1Ггц и 1,3Ггц.
Стадии конвейера Power 4.
IF, IC, BP – циклы предназначенные для выборки инструкций и анализа предсказания перехода.
БЛОК ВЫБОРКИ КОМАНД POWER4.
Прежде чем рассматривать архитектуру блока выборки команд POWER 4 необходимо отметь следующее:
POWER4 является суперскалярным процессором с конвейерной организацией обработки команд. Как мы увидим далее, при рассмотрении технологии конвейерной обработки команд в процессоре возникают конфликты по управлению, связанные с выполнением команд переходов.
|
|
|
Для уменьшения времени простоя конвейера используется технология предсказания переходов то есть вероятностный метод продвижения команд по конвейеру.Не вдаваясь в подробности функционирования механизма логики предсказания переходов, который мы рассмотрим позже, отметим только то, что загрузка очередной порции команд в кэш инструкций из вышестоящего уровня иерархии памяти происходит по адресу, сформированному этой логикой (блоком предсказания переходов)
Так как адреса обращения за командами являются логическими при использовании виртуальной памяти и требуется их преобразование в физические, то для сокращения числа обращений к блоку преобразования адресов, используются буфера быстрой переадресации (TLB), в которых хранятся значения адресов логических страниц и соответствующих им физические адреса, вычисленные ранее при первом обращении в память по выше упомянутым логическим адресам этих страниц.
Но в отличии от кэш данных механизм обнаружения команд в кэш инструкций и использование буферов быстрой переадресации намного сложнее и это в первую очередь связано с использованием вероятностного метода выбора инструкций из кэш.
Если при загрузке строки данных в кэш промах в дальнейшем при обращении к данным этой строки может возникнуть при изменении их самим процессором или другим агентом системы (многопроцессорные системы), то при загрузке строки команд в кэш инструкций нет ни какой гарантии, что все команды в этой строке будут выполнены полностью, прежде чем будет загружена другая порция команд в кэш инструкций (из за команд переходов).
Уменьшить вероятность промаха можно уменьшением размера строки,загружаемой в кэш инструкций, но при этом возрастает размер буфера переадресации.
|
|
|
Большой же размер строки приводит к увеличению числа команд переходов и усложняет логику предсказаний и снижает вероятность правильности предсказания,поэтому был выбран компромиссный вариант –выбирать строку большого размера,а анализ предсказания переходов осуществлять по секторам строки,на которые она делиться. При чем РАЗМЕР СЕКТОРА выбрать равным буферу, в который читаются команды из кэш инструкций для выполнения в процессоре. Но для этого пришлось вводить не один буфер TLB а два, потому что первый хранит физические адреса строк находящихся в кэш в соответствии с логическими адресами обращения за командами.а второй буфер осуществляет контроль за продвижением команд внутри строки каждый раз при загрузке очередного сектора из кэш инструкций в буферные регистры путем сравнения физических адресов из обоих буферов
Инструкция выбирается из КЭШ инструкций по значению адреса IFAR- Instr.fetch address reg.
Обычно IFAR загружается согласно логике предсказания перехода.
В случае ошибочного предсказания,необходимо будет произвести корректировку значения IFAR, чтобы продолжить выполнение потока инструкций в нужном направлении. Кроме этого изменение потока инструкций может быть вызвано прерыванием от внешних событий, в любом случае, как только в IFAR будет загружен адрес команды, то до восьми инструкций поступает на конвейер в каждом цикле.
Каждая строка в КЭШ инструкция составляет 128 байт, которая разделена на 4 эквивалентных сектора по 32 байта, которые определяют ширину данных записи/ считывания в цикле работы кэш памяти команд.
В архитектуре Power взят буфер Т LB(translate looksid buffer) и SLB – (Segment looksid buffer) для преобразования эффективного адреса в реальный. Power4 содержит 4 буфера трансляции (по два на каждый процессор в двух ядерной архитектуре то есть на каждый процессор приходится кэш команд и кэш данных).
Когда конвейер инструкций готов получать инструкцию, содержимое IFAR посылается в полностью ассоциативный буфер IDIR(Instr. Directory), который адресуется частью эффективного адреса, другая часть которого используется как тег. Кроме этого теговая строка содержит 42 бита реального адреса, содержащие два полных физических адреса строк, переписанных из кэш L2 в кэш инструкций и находящихся в ней на данный момент. Так как размер кэш L2 составляет 1,5 МГБ, то для фиксации адресов двух строк из кэшL2 в кэш инструкций нужны эти 42 разряда. В блоке выборки команд имеется еще таблица переадресации IERAT, которая имеет такую же архитектуру как и выше упомянутый буфер с той лишь разницей, что в теговой строке содержится физический адрес-результат преобразования логического адреса. Содержимое этих двух буферных таблиц и является исходной информацией для определения наличия команд в кэш инструкций.
|
|
|
И так содержимое регистра адреса выборки инструкций,обновляется принимая значение адреса первой инструкции в следующем секторе, после того как он будет передан в кэш инструкций, выше упомянутые таблицы и в блок предсказания где сформируется адрес команды, по которому возможно пой дет выполнение программы, если по данному адресу логика обнаружения команд перехода зафиксирует таковую или по другим адресам в считанном секторе в случае его нахождения в кэш инструкций. Если в считанном секторе не будет обнаружен факт перехода и все команды в секторе будут выполняться последовательно, то в буфер инструкций будет загружен следующий сектор. А сейчас вернемся к началу цикла выборки инструкций из кэш и рассмотрим подробнее механизм обнаружения их в памяти.
И так по значению в IFAR считывается значение реального адреса из “IDIR” эффективный и реальный адреса из таблицы IERAT.
IERAT (содержит эффективный и соответствующий ему реальные адреса) проверяется с тем чтобы проверить достоверность входа и чтобы реальный адрес сравнить со значением IDIR.Сравнение необходимо ввиду того, что с момента загрузки строки из кэшL2 в кэш инструкций к моменту выбора очередного сектора из нее в буферные регистры блока выборки, строка может перейти в состояние INVALID или на ее место будет к этому моменту загружена другая строка из системной памяти. Если в таблице IERAT установлен флаг INVALID, то
|
|
|
EA должен быть транслирован из TLB и SLB. Выбранная инструкция «пузырится». Если IERAT VALID, RAIPIR=RAIER устанавливая Icahehit i=1, разрешает продвижение конвейера и работу блока предсказаний и IFAR вновь устанавливается в соответствии с индикатором ВТВ. Активизируются декодеры, начинается формирование групп, логика разрешает выбранным инструкциям продвигаться по конвейеру.
ЕСЛИ обнаружен промах, возможны несколько сценариев:
1) буфер предвыборки проверяется есть ли в нем затребованная инструкция, и если да, логика продвигает эти инструкции к конвейеру: как если бы они были выбраны из КЭШа и записывает также критический сектор в КЭШ.
2) Если инструкции нет в буфере, формируются два последовательных запроса к КЭШ уровня L2. L2 обрабатываются, в результате чего будет произведена запись в кэш инструкций и в буфер предвыборки.
В случае присутствия затребованной инструкции в буфере предвыборки, организуется запрос в кэш L2 за очередной строкой.
В дополнение к механизму выборки инструкции по затребованным запросам БВК осуществляет выборку инструкций, которые в скором времени будет затребована для выполнения.
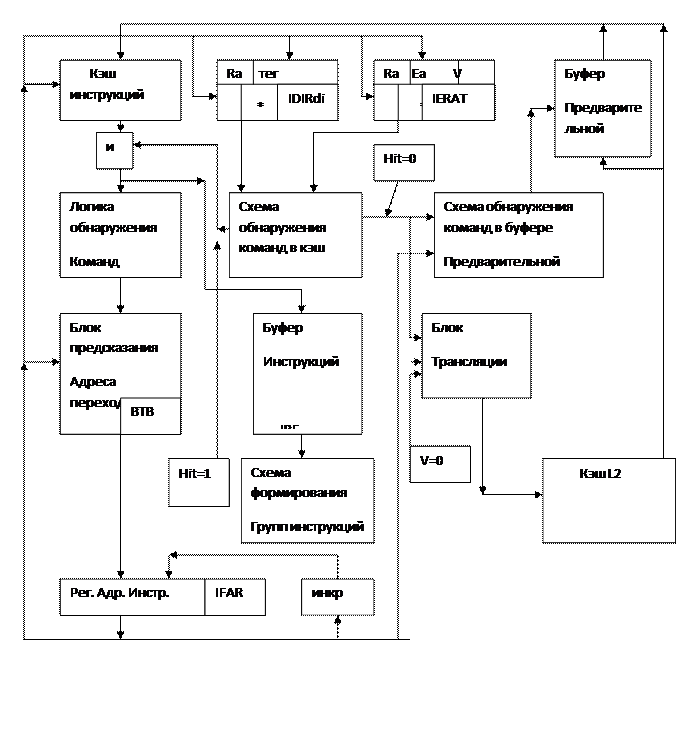
Блок-схема блока выборки команд Power4
D0, D1, D2, D3 Xfer, GD – циклы, в течении которых инструкция декодируется и формируется в группы.
MP – цикл, в течении которого выявляются все зависимости, ресурсы, и группа диспетчеризуется в соответствующую очередь.
ISS – данный цикл предназначен для постановки в очередь для выполнения в функциональном устройстве, чтения соответствующего адреса регистра для выбора данных из регистрового файла и формирования адреса для записи результата.
EX – цикл выполнения.
WB – цикл записи в регистр результатов. В этом цикле инструкция заканчивает выполнение, но не завершенной она не моет завершиться по крайней мере еще 2 цикла.
Xfer, CP – циклы предназначенные для завершения всех старших Групп или инструкций в той же группе.
Следует отметить, что инструкции, выбранные из кэш инструкций ждут D1 цикл, если они выбираются раньше, чем попадут в группу. Подобные инструкции могут ждать MP цикла, если ресурсы недоступны или ISS цикла или СР цикла для завершения.
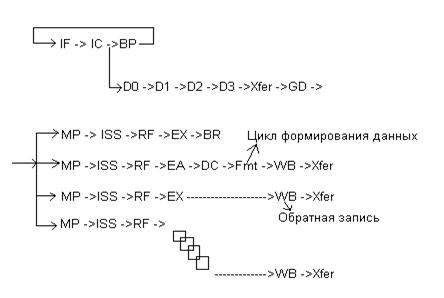
Особенностью архитектуры Power 4 является объединение инструкций в группы по 5 инструкций в каждой, которые поступают после формирования на этап диспетчеризации для дальнейшего исполнения в соответствующих исполнительных устройствах. Это делается с целью упрощения механизма отслеживания за выполнением инструкций при безупорядочном выполнении в исполнительных устройствах. Если в INTEL отслеживается каждая инструкция и удаляется с конвейера при завершении всех предыдущих, то в Power 4 удаляется группа целиком, т.е. 5 инструкций при условии, что все инструкции в группе завершены, и все предыдущие группы удаляются с конвейера.
Power 4 имеет так называемую Глобальную таблицу завершения групп. Для увеличения числа инструкций находящихся на исполнении в устройствах Power 4 имеет Глобальную таблицу завершения инструкций на 20 входов. Т.е. одновременно отслеживаются 20 групп. Т.е. 20*5=100 инструкций, а при 2х ядерном до 200. Для каждой группы находящейся на этапе выполнения в таблице отводится строка, в которую заложен адрес
1 ой инструкции в группе. Таким образом, частью механизма завершения инструкций в программном порядке.
Индивидуальные группы следуют через систему то есть состояние процессора отслеживается на границе группы,а не на границе инструкции внутри группы.Любая исключительная ситуация вызывает сохранение старшей группы, предшествующей возникновению причины прерывания.
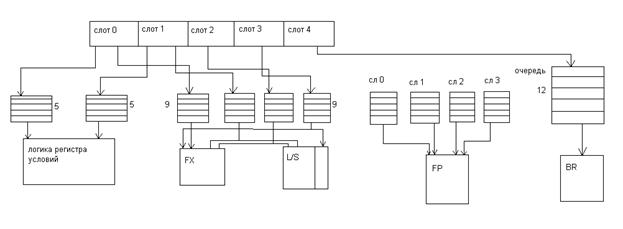
Группа содержит до пяти внутренних инструкций. На стадии формирования группы инструкции в группе размещаются последовательно. Старшая инструкция в слот 0,следующая за ней в слот 1 и т.д. Слот 4 зарезервирован для инструкций перехода. Только одна группа инструкций распределяется за цикл и все инструкции в группе распределяются одновременно.
Индивидуальные инструкции из очередей в функциональных устройствах поступают на выполнение беcпорядочно. Результат фиксируется,когда группа завершает выполнение условием которого является ситуация,когда все старшие группы завершены и завершены все инструкции в группе.
Для осуществления корректного выполнения некоторым инструкциям запрещены спекулятивные операции то есть обгонять впереди идущие в программном коде. Примером таких инструкций являются инструкции чтения и записи в защищенные области памяти или такие как запись в регистры,фиксирующие состояние процессора.
Для организации безупоряочного выполнения большинство логических (архитектурных) регистров подвергаются преобразованию, но не все. Инструкции, в которых запрещено переименование, размещаются в конце группы
Внутренние инструкции в группе в большинстве своем являются системными командами,однако, иногда системные команды разбиваются на несколько внутренних при формировании группы. Если системная команда разбивается на две внутренние, то обе они должны быть в одной группе. Если обе инструкции не могут быть размещены в одной группе, то группа заканчивается и новая группа формируется.Инструкция следуемая за разбиваемой может быть размещена в группе при наличии в ней места.
Следует отметить, что при формировании групп учитываются возможности инструкций из слотов в исполнительном устройстве. Так например, в слоте 4 могут располагаться инструкции перехода, если к моменту формирования группы таковой не окажется, то их место 4 ый слота формир. Инструкц. Н.О.П.
Так устройство, обрабатывающее содержимое регистра условий может принимать инструкции только из слота 0 или 1.
В Power 4 до 8 инструкций выбираются в каждом цикле из кэш инструкций в буфер инструкций. Логика предсказания переходов сканирует выбранные инструкции, просматривая до 2х переходов в каждом цикле. В зависимости от типа найденного перехода, различные механизмы предсказания помогают предсказывать направление и адрес перехода. Безусловные переходы не предсказываются. Power 4 использует для предсказания переходов 3 таблицы историй переходов. Первая таблица, называемая локальным предсказанием подобна традиционной таблице В.T.Т. Это 16.384 входов табл (2 в 14 ой степени) индексируемая адресом инструкций перехода с 1 бит предсказания.
Вторая таблица, называемая глобальным предсказанием. Предсказывает направление перехода в соответствии со значением перехода на действительную траекторию при выполнении каждой команды перехода. Траектория прохождения фиксируется в 11 бит регистре по одному биту на каждую группу инструкций, из одиннадцати предыдущих выбранных из кэш. Этот вектор называется вектором глобальной истории. Каждый бит в глобальной истории отражает была ли выбрана следующая группа из последовательного сектора кэш. Вектор глобальной истории собирает информацию о выполнении этих секторов.
В.Т.В. содержит 3 таблицы:
1) таблица локальных переходов.
2) глобальная таблица
3) Селекторная таблица, осуществляющая фиксацию предсказаний в каждой таблице и действительный результат по каждому предсказанию.
Локальная таблица Глобальная таблица Селекторная таблица
Power 5
1) Организация многопоточного режима.
Для этого на стадии до – после выборки инструкций из кэш они распределяются по 2м потокам отдельные буфера по 24 инструкции каждая. Таким образом, комплектуются группы инструкций из одного потока.
2) Регистровый фаил разделяется между двумя потоками. Т.е. все регистры файла доступны каждому из потоков.
3) Для реализации многопоточности размер и структура очередей были модифицированы.
Таблица GCT для каждого входа (группы) сигнала содержит дополнительный бит, фиксирующий принадлежность группы к потоку.
Помимо этого каждый логический регистр при замене на физический стал содержать бит
(индекс) принадлежности к потоку. А количество физических регистров было увеличено.
4) Модернизация подверглась очередь для инструкции L/S. Дело в том, что области памяти для потоков разнесены в адресном пространстве. Поэтому очереди эти разделились поровну между потоками. А для того, чтобы исключить «пузыри» для этих инструкций организовали виртуальные очереди, в которых фиксируется инструкция при диспетчеризации, но без указания адресов памяти. Как только в реальной очереди освобождается место, инструкция переходит из виртуальной очереди в реальную, и для нее формируется адрес обращения к памяти.
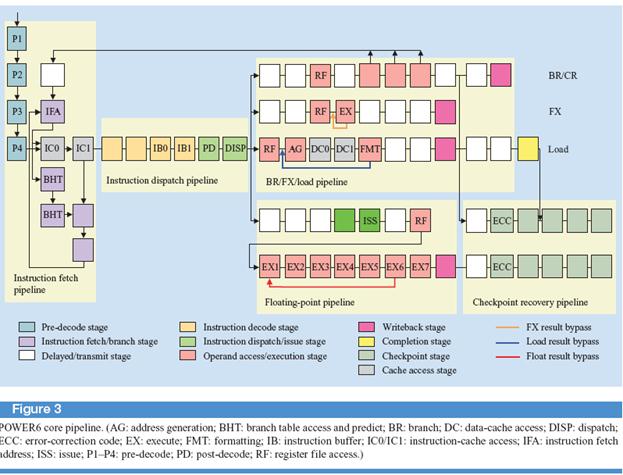
Архитектурные особенности POWER 6
Главной особенностью архитектуры Power 6 от предыдущих Р4 и Р5 является вынос за пределы конвейера стадий формирования групп, поступающих на диспетчеризацию. Формирование групп в Power 6 осуществляется при переходе инструкций из кэш L2 в
кэш инструкции. Таким образом, в кэш L1 поступают формированные группы. Кроме этого, если в Р4 и Р5 сохраняются зависимости внутри группы, то в Р6 инструкции в группе друг от друга независимы кроме инструкции с плавающей точкой.
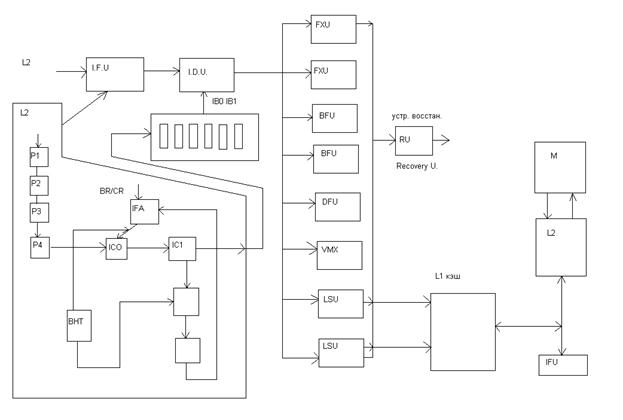
Архитектура микропроцессора Z990
Прежде чем рассматривать архитектуру микропроцессора Z990, необходимо отметить, что данная архитектура явилась результатом эволюции развития серверов предшествующих поколений, родоначальником которых была серия манфреймов IBM360. Особенностью этой серии была CISC архитектура,которая определяла структуру и форматы команд, реализуемых в процессорах этой серии. Кроме того эти процессора достаточно развитую аппаратную систему диагностики и восстановления работоспособности процессоров,поддерживаемую на программном уровне специальными системными командами. Хотя эти процессора не были суперскалярными и выполняли только одну инструкцию за цикл, но имели достаточно высокие показатели и характеристики при выполнении сложных CISC команд за счет наличия дополнительных аппаратных средств(акселераторы, блоки логических операций) и мощную систему памяти,включающую буферные памяти команд и аппаратные средства поддержки преобразования логических адресов в физические.
Внедрение принципов RISC архитектуры при проектировании процессора сопровождалось разработкой и появлением новых языков программирования C, C++, Java, которые использовались для написания программных приложений для пользователей. Для того чтобы сохранить возможность выполнения уже ранее разработанных приложений и новых разработчики архитектуры процессора решили совместить как технологию суперскалярности, так и возможность выполнения сложных команд CISC архитектуры.
При разработке архитектуры микропроцессора были учтены и использованы достижения и наработки в предшествующих моделях процессоров. Это в первую очередь использование милликодов и аппаратные средства восстановления работоспособности системы при возникновении сбоев.
Кроме того в микропроцессореZ990 подобно его предшественникам используется дублирование функционирования основных узлов процессора и содержится несколько механизмов для трансляции его состояния в резервный процессор в случае фатальной ошибки.
В микропроцессоре рассматриваемой архитектуры не используется технология безупорядочного выполнения команд, что является отличительной особенностью от других RISC процессоров. За счет этого была сокращена аппаратная часть микропроцессора поддержки этого режима и ее место заняли схемы дублирования основных узлов и восстановления при возникновении ошибок.
Одним из оригинальных решений при проектировании было решение сохранить использование милликода, который использовался еще в предшествующих моделях.
Для того, чтобы понять, что из себя представляет милликод и как он используется в процессоре, напомним, что существуют два основных метода реализации команд в процессоре. Это микропрограммное управление и жесткая логика.
Большинство команд в микропроцессореZ990 реализуется аппаратными средствами, т. е. использует жесткую логику и только сложные команды используют милликод.
Если рассматривать архитектуру микропроцессоров,например, линейку микропроцессоров PENTIUM фирмы INTEL,то можно отметить, что при реализации сложных команд,когда дешифратор не справляется с декодированием инструкции в микроинструкции там используется, так называемый, микрокод,хранящийся в постоянной памяти микропроцессора, который можно интерпретировать как элемент микропрограммного управления.
С точки зрения методологии подхода к реализации сложных команд нет разницы,,но отличие заключается в том, что INTEL использовала микроинструкции,имеющие свою специфичную структуру и формат, а IBM стандартные команды с вертикальным кодированием, таким образом милликод также как основной набор команд выполняется на тех же аппаратных средствах, это во первых. А во-вторых, функциональные возможности милликода намного шире,чем системные команды, то есть при входе в режим выполнения милликода его рутинам доступны аппаратные средства, которые не доступны даже системным командам.
Размещается милликод,точнее его рутины в системной памяти в определенной области,в которую запрещен доступ системным командам и загружается в эту область во время инициализации системы по включению питания то есть эта область по сути выполняет функцию памяти микропрограмм.
И так, отказавшись от технологии микропрограммного управления, IBM сохранила ее метод управления вычислительным процессом за счет
1 Использования особого режима во время выполнения милликода.
2 Расширения функциональных возможностей, что позволило реализовать не только интерпретацию сложных команд, но и выполнять сервисные функции в процессоре, связанные с диагностическими операциями и реализацией механизмов прерывания.
Применение милликода в процессоре позволило разработчикам серверов перенести часть функций при реализации виртуального режима в них с системного уровня на аппаратный и именно этот факт стал при реализации технологии логических партиций LPAR в серверах фирмы IBM, то есть многооперационных систем на одной аппаратной платформе.
И так рассмотрим работу конвейера в процессоре более подробно.
Выборка инструкций и блок предсказания переходов.(циклы выборки из кэш)
Доступ к кэш памяти инструкций по времени занимает 3 цикла конвейера в течении которых формируется запрос в кэш инструкций со стороны устройства выборки инструкций и передача выбранных инструкций в буферные регистры. Обычно эти циклы скрыты и не влияют на производительность процессора так как выборка инструкций из кэш производится с опережением, и была еще использована в свое время в отечественных ЭВМ серии ЕС начиная с ряда2.
В тех случаях когда текст инструкции необходимо декодировать немедленно, то она,минуя буфер, передается на декодер(случай перевыборки, связанный с командой перехода,.когда целевая инструкция отсутствует в буфере команд)
Устройство выборки имеет 16 буферных регистров, каждый с разрядностью в 4 слова.
Логика предсказания переходов содержит буфер целевых адресов, строки которых содержат, бит предсказания, целевой адрес и адрес самой команды перехода. В случае отсутствия информации в буфере для данной команды перехода принимается решение- нет перехода на целевой адрес.
Помимо этого буфер переходов целевого адреса содержит “историю” переходов, указывая, что на данный момент наиболее вероятен “сильный”,”слабый”или отсутствие перехода в зависимости от величины счетчика переходов.
Декодирование и формирование групп.(циклы D1,AA1)
Декодеры инструкций могут декодировать любой тип инструкций. Большинство инструкций декодируется в одном цикле. Однако, наиболее сложные требуют более одного цикла для декодирования, к таким, например, относятся двухадресные инструкции, указывающие на расположение операндов в памяти.
Большинство других инструкций декодируются вместе, объединяясь в группу с одним исключением: инструкция перехода должна быть старшей в группе.До трех инструкций может входить в группу.
Совместно с командой перехода, которая является старшей в группе, могут находиться простые, выполняемые за один такт, к которым относятся логические и арифметические операции.
Идея размещения команды перехода старшей в группе связана с тем, что на первый взгляд является парадоксальной, так как эти команды предназначены для анализа признаков результатов от предыдущих команд. Однако выбранная схема при отсутствии безупорядочного выполнения, то есть в порядке следования программному коду дает возможность получать результат перехода в одном цикле с проверяемой командой, так как она выполняется в предыдущей группе программного кода.
Во время формирования групп могут иметь место факторы,которые ограничивают их эффективное выполнение в процессоре и препятствуют включению инструкций в группу. Так,например,одним из условий является, что генерация адреса обращения к памяти должна быть завершена до того или в том же цикле,в котором группа с инструкцией,использующей этот адрес, поступает в операционное устройство для исполнения. Кроме того,если инструкция имеет зависимость при формировании адреса от инструкции уже распределенной в группу,(старшая инструкция производит операцию над базовым или индексным регистрами, являющихся составной частью адреса операнда) то она не включается в группу.
Такие зависимости как RAWв группе между инструкциями запрещены,с одним исключением.Если такая зависимость существует между инструкциями типа LOUD,выполняющей загрузку данных в регистр из памяти или из другого регистра регистрового файла, а другая использует загружаемый регистр как источник операнда в арифметической или логической операции, то такая комбинация разрешена в группе. Путем простого изменения маршрута на вход исполнительного конвейера продвижение операнда может быть реализовано с минимальными потерями.
Цикл AA1 предназначен не только для формирования групп, но и для формирования адреса операнда при обращении к памяти. Цикл этот по времени совпадает с началом работы конвейера кэш памяти, первым циклом которого является цикл C0. Совмещение по времени этих двух циклов не случайно и вот почему.
Цикл AA1 предназначен для вычисления значения адреса операнда, указанного в команде,который является логическим в режиме виртуальной памяти, поэтому после вычисления логического адреса в этом цикле происходит обращение к таблице, хранящей историю преобразования логических адресов в физические, то есть перечень логических адресов и физических им соответствующих. Если будет найден в таблице физический адрес операнда,то его значение может быть использовано уже в следующем цикле конвейера кэш,это во-первых. А во-вторых, в случае команды перехода на месте адреса операнда в формате команды указывается адрес перехода. А это означает, что к моменту вычисления логического адреса перехода можно организовать обращение не только к таблице истории,но и в блок предсказания, в котором еще в циклах выборки это адрес перехода был считан из таблиц предсказания. Следовательно по результату сравнения логических адресов в команде перехода и в таблице предсказания, в случае совпадения их можно будет использовать результат,полученный из таблицы истории (физический адрес команды перехода) в следующем цикле работы конвейера кэш.
Следующий цикл С1. В этом цикле по значению логического адреса, сформированного в предыдущем цикле С0 (если в таблице истории ААНТ-absolute address history table не найден физический адрес) активизируется частично или полностью работа блока преобразования адресов, происходит обращение к индексной памяти кэш,если в буфере быстрой переадресации хранятся уже данные преобразования (физический адрес страницы) и буфере TLB (логический адрес страницы) и в случае наличия данных в кэш,данные считываются из памяти и передаются в исполнительные блоки процессора d в следующем цикле С2
Кэш память организована как память с чередованием адресов, то есть данные с четными адресами расположены в одном физическом блоке, а данные с нечетными в другом и следовательно кэш имеет два независимых друг от друга конвейера. В режиме выборки одновременно две строки выбираются из памяти и передаются в процессор.
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 396; Нарушение авторских прав?; Мы поможем в написании вашей работы!