КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Параллельные алгоритмы
СРЕДСТВА ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Вычислительные алгоритмы обладают различным уровнем параллелизма.
Для некоторых классов задач имеется качественная оценка величины паралле-
лизма. Некоторые результаты такой оценки представлены в следующей таблице
Характеристики некоторых параллельных алгоритмов
| № | Наименование алгоритма | Время вычислений | Число процессов |
| Алгебра Решение треугольной системы уравнений, обращение треугольной матрицы Вычисление коэффициентов характеристического уравнения матрицы Решение системы линейных уравнений, обращение матрицы Метод исключения Гаусса Вычисление ранга матрицы Подобие двух матриц Нахождение LU -разложения симметричной матрицы Комбинаторика ε —оптимальный рюкзак, n — размерность задачи Задача о покрытии с гарантированной оценкой отклонения не более, чем в (1+ε)log d раз Нахождение ε — хорошей раскраски в задаче о балансировке множеств Теория графов Ранжирование списка Эйлеров путь в дереве Отыскание дерева минимального веса Транзитивное замыкание Раскраска вершины в Δ + 1 и Δ цветов Дерево поиска в глубину для графа Сортировка и поиск Сортировка Слияние для двух массивов размера n и m, N = m + m |
0(log2 n)
0(log2 n)
0(log2 n)
0(log2 n)
0(log2 n)
0(log2 n)
0(log 3 n)
0(log n log (n/ ε))
0(log2 n log m)
0(log3 n)
0(log n)
0(log n)
0 (log2 n)
0 (log2 n)
0(log3 n loglog n)
0(log3 n)
0 (log n)
0(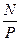 + log N) + log N)
| 0(n4 / log2 n) 0(n4 / log2 n) 0(n w+1) полиномиальное 0(n4 / log2 n) 0(n3 / ε2) 0(n) полиномиальное 0(n /log n) 0(n /log n) 0(n + m) 0(n) 0(n) P = 0(N / log N) |
Скрытый параллелизм. Необходимое условие параллельного выполнения i-й и j-й итераций цикла записывается как и в случае арифметических выражение в виде правила Рассела для циклов:
(OUT(i) AND IN(j)) OR (IN(i) AND OUT(j)) OR (OUT(i) AND OUT(j))=0
Приведем примеры зависимостей между итерациями – прямая (а), обратная
(б) и конкуренционная (в):
а) Итерация i а (i) = a (i –1) итерация 5 а(5) = а(4)
---------------------------------------
Итерация i+1 a (i + 1) = a (i) итерация 6 а(6) = а(5)
б) Итерация i a (i – 1) = a (i) итерация 5 а(4) = а(5)
--------------------------------------
Итерация i + 1 a (i) = a (i = 1) итерация 6 а(5) = а(6)
в) Итерация i s =
--------------------------------------
Итерация i + 1 s =
Знание оценок из таблицы не дает еще возможности построить практический параллельный алгоритм. Во многих случаях он не очевиден и его еще нужно различными приемами проявить в форме, доступной для программирования на некотором параллельном языке. Пример такого проявления приводится ниже.
Рассмотрим метод гиперплоскостей, предложенный L.Lamport в 1974 году на примере решения уравнений в частных производных. Метод носит название “фронта волны”. Пусть дана программа для вычисления в цикле значения Xi,j как среднего двух смежных точек (слева и сверху):
DO 1 I = 1,N
DO 1 J = 1,N
1 X (I, J) = X (I-1, J) + Y (I, J –1) + C
Рассмотрим две любые смежные по значениям индексов итерации, например:
X(2,2) = X(1,2) + X(2,1)
X(2,3) = X(1,3) + X(2,2)
Между итерациями существует прямая зависимость. Использовать для сложения смежные строки нельзя, так как нижняя строка зависит от верхней. Нельзя складывать и смежные столбцы, так как правый столбец зависит от левого. Тем не менее параллелизм в задаче есть, например, все операции в диагонали 41, 42, 43, 44 можно выполнять параллельно.
Если повернуть оси I, J на 45 градусов и переименовать операции внутри каждой диагонали,как на следующем рисунке, то можно использовать этот параллелизм. Соответствующая программа для верхних диагоналей (включая глав
ную) и нижних диагоналей приведена ниже:
DO 1 I = 1,N Пусть I =3, тогда x(3,1)=x(2,1)+x(3,0)
DO PAR J = 1, I x(3,2)=x(2,2)+x(2,1)
X (I, J) = X(I-1, J) + X(I-1, J-1) x(3,3)=x(2,3)+x(2,2)
1 CONTINUE Эти итерации действительно независимы
---------------------------------------
K + 2
DO 2 I = N +1, 2N – 1
DO PAR J + K, N
R = K + 1
X(I, J) = x(I-1, J) + X(I-1, J-1) + C
2 CONTINUE
Здесь К = 1,2 обозначает левый - верхний или правый - нижний треугольник пространства итераций.
Алгоритм метода гиперплоскостей состоит в следующем:
1. Производится анализ индексов и построение зависимостей в пространстве
итераций
2. Определяется угол наклона осей и переименование переменных
3. Строится параллельная программ
Недостаток метода гиперплоскостей состоит в том, что ширина параллелизма в каждой итерации параллельной программы неодинакова. Это исключено в методе параллелепипедов и ряде других методов.
Для параллельного программирования существует ряд языков. Основные из них:
• OpenMP – для многопроцессорных систем с общей памятью
• MPI - для многопроцессорных систем с индивидуальной памятью
Существует часто некоторая путаница между OpenMP и MPI. Эта путаница вполне понятно, поскольку есть еще версия MPI называется "Open MPI". С точки зрения программиста, MPI является библиотекой, которая содержит процедуры передачи сообщений. OpenMP, с другой стороны, представляет собой набор директив компилятора, которые сообщают OpenMP, если включен компилятор, какие части программы может быть запущены как нити. Таким образом, разница «нити» против «сообщений». Рассмотрим оба метода.
|
Дата добавления: 2014-01-04; Просмотров: 344; Нарушение авторских прав?; Мы поможем в написании вашей работы!