КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция №23
Название лекции: Анализ временных характеристик хеширования.
Индексированные файлы.
План:
1. Проблема реорганизации. Анализ временных характеристик хеширования.
2. Индексированные файлы.
3. Поиск в индексе.
1. Проблема реорганизации. Анализ временных характеристик хеширования.
Для каждой операции поиска, модификации, включения, удаления требуется: обращение для чтения справочной участков (если весь справочник не помещается в память) + число доступов, которое не превышает число блоков в данном участке. При поиске в среднем просматривается половина блоков участка. Для всех операций, кроме поиска, требуется ещё записать блок во внешнюю память.
Если каждый участок состоит ровно из одного блока (т.е. лучший случай) для поиска требуется 2 обращения, для остальных 3. Чтобы уменьшить число блоков в участках нужно число участков должно быть ≈ числу записей в файле/ на число записей в блоке.
При росте числа блоков требуется реорганизация. Её достаточно просто провести, если ввести два ограничения:
1) При вычислении функции хеширования от ключа v получают очень большое число >> чем число участков. Полученное число делят на число участков, остаток от деления – номер участка.
2) При реорганизации число участков n умножают на некоторое фиксированное с (обычно с = 2).
Если мы удвоим число участков, то все записи участка i будут попадать в участки i или i+n и в эти участки не попадут никакие записи других участков.
Пусть по ключу v построим N=h(v) и N >>n– числа участков (если мы удвоим n то получим N >>2n), разделим N на n и получим (1.) 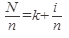 ; где: k–целое, i–остаток от деления, 0 ≤i ≤n-1 номер участка. Из формулы 1: (2.) N= nk+i;
; где: k–целое, i–остаток от деления, 0 ≤i ≤n-1 номер участка. Из формулы 1: (2.) N= nk+i;
Удвоив число участков получим: (3.) 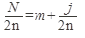 ; формулу (1.) разделим на 2 и прировняем с (3.) (4.)
; формулу (1.) разделим на 2 и прировняем с (3.) (4.) 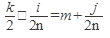 ;
;
Рассмотрим два случая.
1) k= 2l четное (5.) 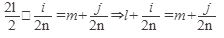 ;
;
в формуле (5.) – равенство двух смешанных чисел, l и m – целые числа, таким образом это целая часть смешанны числа равны → равны и целые части l = m, и равны и дробные части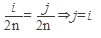 т.о. номер нового участка совпадает с номером старого участка.
т.о. номер нового участка совпадает с номером старого участка.
2) k=2 l +1 нечетное; (6.) 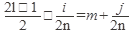 ; (7.)
; (7.) 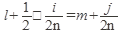 ; (8.)
; (8.) 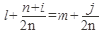 ;
;
l=m → j=n+i, т.е. новый участок сдвинут по отношению к старому на n.
Таким образом при удваивании числа участков записи, находившейся в участке i будут находится или в участке i или в участке i+ n, где n –старое число участков.
2. Индексированные файлы.
Решается та же задача: поиск записи по ключу v.
Допустим, что записи в файле отсортированы по значениям этого ключа (обратить внимание на сортировку дат dtos() и строк – лексикографическая сортировка). Для нескольких полей: сортировка по первому ключу, при равных первых – сортировка по второму и т.д.
В этом случае (файл отсортирован) для поиска можно использовать идею поиска в телефонной книги (словаре), вместо просмотра всех записей. Будем анализировать только первую запись на каждой странице. Если искомый ключ превышает ключ этой записи, то возможно, что искомая запись находится на предыдущей странице. Если даже для последней страницы искомый ключ меньше, чем первый на этой странице, то следует проанализировать записи этой последней страницы.
Аналогично организован доступ к файлу. Пусть мы имеем отсортированный файл с информацией, назовем его главным файлом. Создадим для главного файла второй файл– так называемый разреженный индекс, состоящий из пар (значение_ключа, адрес_блока).
Пара (v,b) появляется в файле индекса, если первая запись в блоке главного файла с адресом b имеет значение ключа v. Записи файла индекса подобно обыкновенному (информационному) файлу с двумя полями: ключ и номер блока. Записи файла индекса отсортированы по значению ключа и не являются закрепленными, т.к. нигде в другом файле нет ссылки ни на какую запись файла индекса. Вероятно, что с файлом индекса, как и с обычным (информационным) файлом следует выполнить операции включения, модификации, удаления и кроме того необходима новая функция (вместо поиска): для данного ключа v, найти такую запись ((v2,b2)| (v2 ≤ v1) Ù ((следующая (v3,b3) | (v3 >v1) Ú (v2,b2) –последняя в файле)))
В этом случае говорят, что v2 перекрывает v1 (это значит, что если запись с ключом v1, содержится в файле, то она может содержаться только в блоке b2, у которого первая запись имеет ключ v2).
3. Поиск в индексе.
Требуется найти запись в основном файле с ключом v1.
Задача (для файла индекса): найти в файле индекса запись (v2,b2) такую, что v2 покрывает ключ v1.
Решение: В простом случае (мало записей в индексе) – линейный поиск (условия применения – весь индекс в основной памяти) Внимание! пояснить, что такое линейный поиск.
Но и в этом случае выигрыш, т.к. если в блоке основного файла записано 'к' записей и известно 1 запись в индексе организуется на первый блок основного файла, то в файле индекса в 'к' раз меньше записей. Кроме того, обычно записи индекса короче, чем записи основного файла и в 1 блок индекса помещается больше записей (появляется вероятность размещение всего индекса в оперативной памяти).
Лучшая стратегия поиска в файле индекса – использование двоичного поиска. При данной стратегии на каждом шаге количество блоков (при поиске записи (v2,b2) – покрывающих ключ v1) индекса, содержащих запись (v2,b2) сокращается вдвое.
Таким образом если в индексе n блоков, то не боле чем за log2(n+1) чтений будет прогнан блок индекса, содержащий запись (v2,b2). В практике часто вместо оценки log2(n+1) используют оценку log2n. С учетом доступов к основному файлу общее число доступов – 3+ log2n (3 складывается из 1 – чтение справочника индекса, 1 – чтение блока файла, 1 – запись блока файла).
Пример: Пусть в главном файле есть 106 записей. В блоке помещается 10 записей, следовательно всего в файле 105 блоков. Пусть в один блок индекса помещается 100 записей, значит для индекса необходимо 1000 блоков. Таким образом, для доступа и перезаписи блока основного файла требуется 3+ log21000»13 обращений (log21024 = log2210 = 10, т.о. log21024»log21000»10).
При исследовании хешированного файла (и условии 1 блок – 1 участок) необходимо 3 доступа, но имеется для индекса дополнительные преимущества ® возможность поддерживать отсортированный порядок в файле (как минимум логическую упорядоченность).
Метод поиска в индексе, который может превосходить по быстродействию двоичный поиск, известен как интерполяция, или способ с помощью вычисления адреса. Этот метод основан на значении статистики предполагаемого распределения значений ключа при условии достаточной надежности этого распределения.
Пример: телефонная книга: известно, сколько необходимо «отступить» от правила, чтобы найти нужную букву. Т.к. вы знаете алфавит.
|
Дата добавления: 2014-01-05; Просмотров: 502; Нарушение авторских прав?; Мы поможем в написании вашей работы!