КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Заключительный пример
|
|
|
|
Формат
{ <описания и определения> <выполняемые операторы>}
Пример:
{int i, j; void main ()
for(i=0; i<l; i++) { {
s[i]=0; <блок>
for (j=0; j<k; j++) { }
s[i] += p[i][j]*q[j]; } } }
Описания и определения, заданные внутри текущего блока, действуют (выделяется память под переменные) только внутри блока. Этим блок отличается от составного оператора. Блоки могут быть вложенными.
7.2 Процедуры
ПРОЦЕДУРА – это часть программы, которая не выполняется в естественном порядке, а вызывается специальным способом.
Когда некоторая совокупность действий должна выполняться в нескольких различных местах программы, то обычно нежелательно каждый раз повторять группу операторов, реализующих эти действия. Чтобы избежать повторений, указанную группу операторов можно записать в программе один раз и обращаться к ней, когда в этом возникнет необходимость. Обособленную группу операторов, которую можно выполнять многократно, обращаясь к ней из различных мест программы, называют процедурой.
Чтобы процедура при обращении к ней выполнялась каждый раз с новыми данными, ее нужно составить в общем виде, а исходные данные для работы передавать в переменные процедуры перед обращением к ней. Если, на пример, в программе в программе требуется решить три квадратных уравнения с различными коэффициентами, то алгоритм нахождения корней квадратного уравнения целесообразно оформить в виде процедуры, используя для обозначения коэффициентов переменные. Перед каждым обращением к процедуре нужно задать этим переменным числовые значения, соответствующие коэффициентам решаемых уравнений.
Преимущества: Использование процедур уменьшает общее количество операторов в программе, и, следовательно, для размещения программы требуется меньше памяти. Время на выполнение программы практически не изменяется. Использование процедур улучшает структуру программы. Кроме того, облегчается отладка программы, т.к. работа каждой процедуры может быть проверена по отдельности. Многие программы имеют дополнительную ценность, поскольку ими может воспользоваться не только тот, кто написал процедуру, но и другие лица.
|
|
|
Существует два вида процедур: ПОДПРОГРАММЫ и ФУНКЦИИ. Отличие подпрограмм от функций – первые не возвращают значения в основную программу.
ПОБОЧНЫЙ ЭФФЕКТ. В Си формально определены только ФУНКЦИИ.
Связь между функциями осуществляется через входные аргументы, возвращаемые значения и внешние переменные.
Схема обмена данными между процедурами
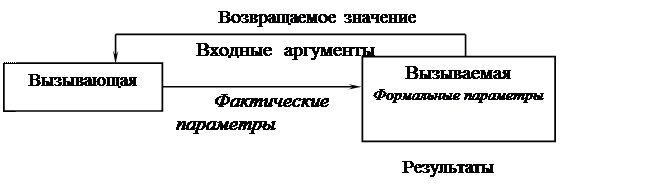 |
Возвращаемое значение функции разумно считать специфическим выходным параметром.
Формат ОПИСАНИЯ функции
[<тип_функции>] <имя_функции>
([<описания_формальных_параметров>])
<блок>
Если <тип_функции> отсутствует, то компилятор по умолчанию подставляет int. ВОЗВРАЩАЕМОЕ ЗНАЧЕНИЕ. Если возвращаемое значение имеет тип не int, то указание типа в заголовке функции ОБЯЗАТЕЛЬНО.
Оператор return: Остановимся поподробнее на зарезервированном слове return. После него функция перестает выполняться и возвращает управление вызвавшей ее функции, передав значение, указанное после return, как результат. Слов return в функции может быть несколько, но хотя бы одно должно присутствовать обязательно. Исключение – когда функция имеет тип возвращаемого значения void. В этом случае слово return в функции может и отсутствовать, если оно есть, то оно не должно передавать что-либо в качестве результата. В этом случае слово записывается так: return;float min_fun (float x[], int n) {
int i, j; // Локальные переменные функции
float min_value;
................
return (min_value) }
|
|
|
Подпрограмма – это функция, не возвращающая значения. Ключевое слово <типа_функции> void.
void <имя_функции> ([<описания_формальных_параметров>])
<блок>
Тип void: Ключевое слово void используется для нейтрализации значения объекта, на пример, для определения функции не возвращающей никаких значений.
Пример:
void putmsg (void) {
printf("Hello, world!\n");
} /* End putmsg */
Для обращения к функции используется выражение с операцией “круглые скобки”:
Обозначение_функции (список_фактических_параметров);
Операндами операции () служат Обозначение_функции и список_фактических_параметров.
Наиболее естественное и понятное Обозначение_функции – это ее имя. Кроме того, функцию можно обозначить, разыменовав указатель на нее.
Сторонники Паскаля! Обратите внимание на разницу между mufunc и myfunc(). myfunc – это ФУНКЦИЯ, а myfunc() – это РЕЗУЛЬТАТ ЕЕ РАБОТЫ. Поэтому если вы напишете: myfunc;– то ошибки компиляции не будет (в выражениях допускается отсутствие операторов), но ничего не произойдет – для того, чтобы вызвать функцию, необходимо подействовать на нее оператором вызова функции ().Список фактических параметров, называемых аргументами, – это список выражений, количество которых равно числу формальных параметров функции (исключение составляют функции с переменным количеством параметров). Соответствие между фактическими и формальными параметрами устанавливается по их взаимному расположению в списках. Порядок вычисления значений фактических параметров (слева направо или справа на лево) стандарт языка СИ не определяет.
Между формальными и фактическими параметрами должно быть соответствие по типам. Лучше всего, когда тип фактического параметра совпадает с типом формального параметра. В противном случае компилятор автоматически добавляет команды преобразования типов, что возможно только в том случае, если такое приведение типов допустимо.
В языке Си нет предопределенных функций. Каждая используемая функция должна быть где-то определена (ОБЪЯВЛЕНА) до ее использования. Поскольку все функции могут транслироваться автономно, то в вызывающей процедуре необходимо ОПРЕДЕЛЕНИЕ вида (прототип функции):
|
|
|
(<тип_возвращаемого_значения>)<имя_функции>
([ описание_параметров]);
Без него возвращаемое значение функции будет интерпретироваться как типа int и возможна ошибка. Поэтому подпрограмма не описывается.
Здесь возможны два варианта: 1. Если Вы используете встроенные функции среды Си, то самому писать многие требуемые функции (ввод-вывод, подключение файлов, математические функции и т.д.) каждый раз несколько скучно К счастью, Си снабжен библиотекой, содержащей в себе множество разнообразных функций. Для того, чтобы использовать ее, подключите к вашей программе требуемый ЗАГЛОВОЧНЫЙ ФАЙЛ (он имеет расширение.h) к вашей программе следующей строкой: #include <Имя_заголовочного_файла> На место этой строки в программу при компиляции будет подставлено содержание указанного файла.2. Если Вы создали личную функцию, отличную от стандартных функций языка Си, то перед ее вызовом она обязательно должна быть объявлена:
На пример, пусть определена функция с прототипом:
int g (int x, long y);
Далее в программе использован вызов:
double m;
rez = g (3.0+m, 6.4e+2);
Оба фактических параметра в этом вызове имеют тип double. Компилятор, ориентируясь на прототип функции, автоматически предусмотрит такие преобразования:
(int) rez = g ((int)(3.0+m), (long)(6.4e+2))
Пример (функция):
void main () {
double max (double, double) // Прототип функции
…
max_value = max (cos(x), sin(x)); // Обращение к функции
… }
double max (double a, double b) // Описание функции
{ double y;
if (a > b) y = a;
else y=b;
return y; }
Пример (подпрограмма):
/* Умножение матрицы на вектор */
matrix(a, b, c, m, n);
void matrix (double p[10][10], /* Исходная матрица */
double q[10], /* Исходный вектор */
double s[10], /* Вектор–результат */
int l, /* Число строк */
int k) /* Число столбцов */
{ int i, j;
for (i=0; i<l; i++) {
for (s[i]=j=0; j<k; j++) {
s[i] += p[i][j]*q[j]; } }
} /* End matrix */
В каждой программе должна быть процедура, которой передает управление ОС и которая остается активной в течение всей работы программы. Эта процедура называется ГЛАВНОЙ и имеет заголовок вида
|
|
|
int main ([<параметры>])
<блок>
О параметрах пока умолчим, поэтому обычно имеем
void main (void) { … }
Функции в Си совершенно равноправны. И функция main тоже может вызываться другими функциями: Например: int func (int a); int main (void) { return func (5); } int func (int a) { return main (); } В этом случае выход из программы, конечно, произойдет только после завершения работы "самой наружной" функции main.
7.2.1 Передача скаляров
ФАКТИЧЕСКИЕ ПАРАМЕТРЫ. Перед передачей входные аргументы типа float и char АВТОМАТИЧЕСКИ преобразуются в типы double и int, следовательно, соответствующие параметры должны быть описаны надлежащим образом, иначе произойдет ошибка.
Пример:
Вызывающая процедура Вызываемая процедура
float a, b, max(); float max (float a, float b) { //Ошибка
..................
y=2+3.5*max(a, b); float max (double a, double b) {//Верно
ФОРМАЛЬНЫЕ ПАРАМЕТРЫ. При передаче СКАЛЯРНЫХ ДАННЫХ в вызываемую процедуру передаются только копии аргументов. Физически происходит выделение нового участка оперативной памяти и копирование аргументов в память, распределенную вызываемой процедуре.
ВНИМАНИЕ! Поэтому в теле функции мы можем изменить ТОЛЬКО КОПИЮ и не повлияем на АРГУМЕНТ в вызывающей процедуре!
Вопрос? А как же передать результаты работы в вызывающую процедуру, если реально можно передать только одно значение?
Для этого надо передавать АДРЕС области памяти, где хранится аргумент. При этом функция не может изменить этот адрес, а содержание может. Для получения адреса операция &. Следовательно, соответствующий параметр – УКАЗАТЕЛЬ!!
Пример:
Дана матрица {a[i][j]}, i,j = 1...10.
Найти max{ a [i][j] } и его индексы.
Вызывающая процедура
void main (void) {
float maxmatr(), maxim, a[10][10];
int m, n;
..................................
maxim = maxmatr (a, &m, &n);
Функция
float maxmatr (float a[10][10], int *k, int *l) {
float max;
int i, j;
max = a[0][0];
for(*k = *l = i =0; i<10; i++) {
for (j = 0; j < 10; j++) {
if (max<a[i][j]) {
max=a[i][j];
*k=i;
*l=j; } } }
return max;
} /* End maxmatr */
Подпрограммы
void maxmatr (float a[10][10], int *k, int *l, float *max) {
/* float max; везде заменить max на *max и убрать return/
Пример ом использования ПП может служить scanf: список данных – выходные аргументы, поэтому надо адреса(&), printf: список данных – входные аргументы, поэтому значения, без адресов.
7.2.2. Передача массивов
Фактическим аргументом при передаче массива служит его имя, т.е. передается АДРЕС 1-го элемента (индексы–0) и массив НЕ копируется в локальную память функции.
Это передача ПО ИМЕНИ | ПО ССЫЛКЕ | ПО АДРЕСУ. Такой механизм присущ передаче всех данных в языке FORTRAN.
При описании вида
float a[10][10];
обращение к функции вида: <имя_функции> (a)
эквивалентно обращению: <имя_функции> (&a[0][0]).
Следовательно, массивы-параметры занимают память, отводимую в вызывающей процедуре массивам-аргументам, поэтому в вызываемой процедуре допустимы описания вида:
int myfun (float b[], a[][10]);
Память не выделяется, выход за пределы памяти, отведенной массивам–аргументам, компилятором НЕ контролируется.
Максимальные значения всех индексов, кроме 1-го, надо задавать, чтобы правильно извлечь из памяти значения нужного элемента массива. Допустимо даже несоответствие размерностей массива-аргумента и массива-параметра только без выхода за пределы оперативной памяти уже выделенной для массива-аргументов.
Пример: Аргументы Параметры
float a[5][5], b[36]; float a[], b[][6];
Вычислить z = 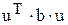 , где {u[i]}, i=1...4; {b[i][j]}, i, j = 1...4.
, где {u[i]}, i=1...4; {b[i][j]}, i, j = 1...4.
/* Вычисление квадратичной формы */
void main(void) {
float u[4], /* Входной вектор */
b[4][4], /* Входная матрица */
v[4], /* Вектор b*u */
z, /* Результат */
scalar(); /* Скалярное произведение векторов */
int i, j;
printf ("Исходный вектор: \n");
for (i=0; i<4; i++) {
scanf ("%f", &u[i]); }
printf ("Исходная матрица: \n");
for (i=0; i<4; i++) {
for (j=0; j<4; j++){
scanf ("%f", &b[i][j]);
} }
matrix(b, u, v);
z = scalar(v, u);
printf ("\n \n \n Квадратичная форма равна %.5g \n", z);
} /* End main */
/* Умножение матрицы на вектор */
void matrix (float a[][4], float x[], float y[]) {
int i, j;
for (i=0; i<4; i++) {
for (y[i]=j=0; j<4; j++) {
y[i] += a[i][j]*x[j];
} }
} /* End matrix */
/* Скалярное произведение векторов */
float scalar (float x[], float y[]) {
int i;
for (z = i = 0; i<4; i++) {
z += x[i]*y[i];
}
return z;
} /* End scalar */
Глава 8 Препроцессор
Каждая программа на языке СИ есть последовательность препроцессорных директив, описаний и определений глобальных объектов и функций.
Препроцессорные директивы (#include, #define и т.д.) управляют преобразованием текста программы до ее компиляции.
Определения вводят функции и объекты. Объекты необходимы для представления в программе обрабатываемых данных.
Функции определяют принципиально возможные действия программы.
Описания уведомляют компилятор о свойствах и именах тех объектов и функций, которые определены в других местах программы (например, ниже по ее тексту или в другом файле).
Исходная программ, подготовленная на языке СИ в виде текстового файла, походит три последовательных этапа обработки:
· Препроцессорное преобразование текста.
· Компиляция.
· Компоновка (редактирование связей или сборка).
Только после успешного завершения всех перечисленных этапов формируется исполняемый машинный код программы.
Задача препроцессора – преобразование текста программы до ее компиляции. Правила препроцессорной обработки определяет программист с помощью директив препроцессора.
Препроцессорная обработка включает несколько стадий, выполняемых последовательно. Конкретная реализация может объединять несколько стадий, но результат должен быть таким, как если бы они выполнялись в следующем порядке:
· Все системно–зависимые обозначения (например, системно–зависимый индикатор конца строки) перекодируются в стандартные коды.
· Каждая пара из символов ‘\’ и “конец строки” вместе с пробелами между ними убираются, и тем самым следующая строка исходного текста присоединяется к строке, в которой находилась эта пара символов.
· В тексте (точнее в тексте каждой отдельной строки) располагаются директивы и лексемы препроцессора, а каждый комментарий заменяется символом пустого промежутка.
· Выполняются директивы препроцессора и производятся макроподстановки (в зависимости от конкретной программы). Препроцессор “сканирует” исходный текст программы в поиске строк, начинающихся с символа #. Такие строки воспринимаются препроцессором как команды (директивы), которые определяют действия по преобразованию текста:
· Замена идентификаторов (обозначений) заранее подготовленными последовательностями символов.
· Включение в программу текстов из указанных файлов.
· Исключение из программы отдельных частей ее текста (условная компиляция).
· Макроподстановка, т.е. замена значения параметризированным текстом, формируемым препроцессором с учетом конкретных параметров (аргументов).
· Esc-последовательности в символьных константах и символьных строках,
например: ‘\n’ или ‘\xF2’, заменяются на их эквиваленты (на соответствующие числовые коды).
· Смежные символьные строки (строковые константы) конкатенируются, т.е. соединяются в одну строку.
· Каждая препроцессорная лексема преобразуется в лексему языка СИ.
Формат директивы препроцессора:
# имя_директивы лексемы_препроцессора
Перед символом # и после него в директиве разрешены пробелы. Пробелы также разрешены перед лексемами_препроцессора, между ними и после их.
Окончанием препроцессорной директивы служит конец текстовой строки (при наличии символа ‘\’, обозначающего перенос строки, окончанием препроцессорной директивы будет признак конца следующей строки текста).
Поясним, что подразумевается под препроцессорными лексемами или лексемами препроцессора (preprocessing token). К ним относятся символьные константы, имена включаемых файлов, идентификаторы, знаки операций, препроцессорные числа, знак препинания, строковые константы (строки) и любые символы, не определенные другим способом.
Определены следующие препроцессорные директивы:
#define –определение макроса или препроцессорного идентификатора.
#include –включение текста из файла.
#undef –отмена определения макроса или идентификатора (препроцессорного)
#if –проверка условия–выражения.
#ifdef –поверка определенности идентификатора.
#ifndef –проверка неопределенности идентификатора.
#else –начало альтернативной ветви для #if.
#endif –окончание условной директивы #if.
#elif –составная директива #else/#if
#line –смена номера следующей ниже строки.
#error –формирование текста сообщения об ошибке трансляции.
#pragma –действия, предусмотренные реализацией.
# –пустая директива.
Директива #define имеет несколько модификаций. Они предусматривают определение макросов и препроцессорных идентификаторов, каждому из которых ставится в соответствие некоторая символьная последовательность.
Директива #include позволяет включать в текст программы текст из указанного файла.
Директива #undef отменяет действие директивы #define, которая определила до этого имя препроцессорного идентификатора.
Директива #if и ее модификации #ifdef, #ifndef свместно с директивами #else, #endif, #elif позволяют организовать условную обработку текста программы. При использовании этих средств компилируется не весь текст, а только те его части которые выделены с помощью перечисленных директив.
Директива #line позволяет управлять нумерацией строк в файле с программой. Имя файла и желаемый начальный номер строки указывается непосредственно в директиве #line.
Директива #error позволяет задать текст диагностического сообщения, которое выводится при возникновении ошибок.
Директива #pragma вызывает действия, зависящие от реализации, т.е. запланированные авторами программы.
Директива # ничего не вызывает, т.к. является пустой директивой, т.е. не дает никакого эффекта и всегда игнорируется.
8.1 Макроопределения
Начнем с самой простой – с макроопределений констант. Мы можем задать какую-либо константу как
const int a = 5;.
В таком случае a – это полноценная переменная, с собственным адресом и областью видимости. Более того, написав
*((int*) &a) = 6;,
мы даже сможем изменять содержимое этой константы. По сути дела, модификатор const не задает константу, а лишь указывает компилятору, что значение переменной по идее не должно меняться.
Но есть и другой способ. Он хорош, если требуется задать не переменную, а именно некоторую константу (как правило – параметр).Для замены выбранного программистом идентификатора заранее подготовленной последовательностью символов используется директива (обратите внимание на пробелы):
#define <идентификатор> <строка_замещения>
(обратите внимание на отсутствие точки с запятой). Символы пробелов, помещенные в начале и в конце строки замещения, в подстановке не используются.
Например: #define VAR 5
Директива может размещаться в любом месте обрабатываемого текста., а ее действие в обычном случае распространяется от точки размещения до конца текста. Директива, во-первых, определяет идентификатор как препроцессорный. В результате работы препроцессора вхождения идентификатора, определенного командой #define, в тексте программы заменяются строкой замещения, окончанием которой обычно служит признак конца той “физической” строки.
Где действует макроопределение? Ввиду того, что замена производится до компиляции, областей видимости на этот этап времени еще нет. Поэтому макроопределение действительно с момента его объявления на протяжении всего текста программы до конца файла или явной отмены определения директивой #undef:
Например: #undef VAR
Исходный текст Результат препроцессорной обработки
#define BEGIN {
#define END {
void main() void main()
begin {
операторы операторы
end }
В данном случае программист решил использовать в качестве операторных скобок идентификаторы begin и end. До компиляции препроцессор заменяет все вхождения этих идентификаторов стандартными скобками { и }. Соответствующие указания программист дал препроцессору с помощью директив #define.
Данные ранее определения переопределять нельзя. Если это надо все же сделать, требуется сначала отменить определение:
Например: #define VAR 2... #undef VAR 2 #define VAR 3.... #undef VAR 3 #define VAR 4И, наконец, определение не должно превышать одну строку. Если <строка_замещения> оказывается слишком длинной, то ее можно продолжить в следующей строке текста. Для этого в конце продолжаемой строки помещается символ ‘\’. В ходе одной из стадий препроцессорной обработки этот символ вместе с последующим символом конца строки будет удален из текста программы.
Пример:
#define STRING “\n Game Over! \
– \t Игра закончена!”
…
printf(STRING);
На экране будет выведено:
Game Over! – Игра закончена!
К склейке применимы два правила:
1) Между косой чертой и символом новой строки не должно быть никаких других символов (пробелов, табуляций,...);
2) Склейка удаляет только символ новой строки и никак не затрагивает символы, идущие после нее (например, табуляции, помещенные с целью повышения читаемости программы). Это критично только для символьных строк, которые рекомендуется склеивать несколько иначе:
Пример:
#define LONG_STR "Это длинная строка..." "...очень длинная строка..." "ну просто очень длинная строка."
Для всего остального лишняя табуляция препятствием не является.
С помощью команды #define удобно выполнять настройку программы.
Например, если в программе требуется работать с массивами, то их размеры можно явно определить на этапе препроцессорной обработки:
Исходный текст Результат препроцессорной обработки
#define K 40
void main() void main()
{ {
int M[K][K]; int M[40][40];
float A[2*K+1]; float A[2*40+1];
float B[K+3][K–3]; float B[40+3][40–3];
· #define M 16 /* Идентификатор M определен как int 16*/
· #define M 'c' /* Идентификатор определен как симв. const*/
· #define M "c" /* Идентификатор определен как симв. строка
с двумя элементами 'c', '\0' */
· #define PK printf (\n Номер элемента = %d", i)
…
int i = 4; На экране:
PK Номер элемента = 4
…
#define REAL long double
#define E (5+10) // Подстановка в программе 2*E приведет
#define E 5+10 // к разным результатам
#define PI 3.141592
Макрозамены не производятся в строковых константах:
#include <stdio.h>
#define str строка
void main (void) {
printf ("Это моя str.\n"); // Печатается "Это моя str."
}
#include <stdio.h>
#define str "строка"
void main (void) {
printf ("Это моя %s.\n", str); // Печатается "Это моя строка."
}
Макрозамена будет произведена только во втором случае.
8.2 Включение в программу заголовочных файлов
Директива #include <…> предназначена для включения в текст программы текста файла из каталога “заголовочных файлов”, поставляемых вместе со стандартными библиотеками компилятора.
Каждая библиотечная функция, определенная стандартом языка СИ, имеет соответствующее описание (прототип библиотечной функции плюс определения типов, переменных, макроопределений и констант) в одном из заголовочных файлов.
Список заголовочных файлов для стандартных библиотек определен стандартом языка.
#include <имя_заголовочного_файла>
не подключает к программе соответствующую стандартную библиотеку. Препроцессорная обработка выполняется на уровне исходного текста программы. Директива #include только позволяет вставить в текст программы описания из указанного заголовочного файла. Подключение к программе кодов библиотечных функций осуществляется только на этапе редактирования связей (этап компоновки), т.е. после компиляции, когда уже получен машинный код программы. Доступ к кодам библиотечных функций нужен только на этапе компоновки.
Именно поэтому компилировать программу и устранять синтаксические ошибки в ее тексте можно без стандартной библиотеки, но обязательно с заголовочными файлами.
Здесь следует отметить еще одну важную особенность. Хотя в заголовочных файлах содержатся описания всех стандартных функций, в код программы включаются только те функции, которые используются в программе. Выбор нужных функций выполняет компоновщик на этапе, называемом «редактирование связей».
Термин “заголовочный файл” (header file) в применении к файлам содержащим описания библиотечных функций стандартных библиотек, не случаен.
Он предполагает включение этих файлов именно в начало программы. Мы настоятельно рекомендуем, чтобы до обращения к любой функции она была определена или описана в том же файле, где помещен текст программы. Описание или определение функции должно быть “выше” по тексту, чем вызов функций. Именно поэтому заголовочные файлы нужно помещать в начале текста программы, т.е. заведомо раньше обращений к соответствующим библиотечным функциям.
Хотя заголовочный файл может быть включен в программу не в ее начале, а непосредственно перед обращением к нужной библиотечной функции, такое размещение директив #include <…> не рекомендуется.
Команда #include имеет три формат а записи:
#include <имя_файла> /*имя в угловых скобках*/
#include “имя_файла” /*имя в кавычках*/
#include имя_макроса /*макрос, расширяемый до обозначения файла*/
где <имя_макроса> – это введенный директивой #define предпроцессорный идентификатор либо макрос, при замене которого после конечного числа подстановок будет получена последовательность символов <имя_файла> либо “имя_файла”.
Существует правило, что если имя_файла – в угловых скобках, то препроцессор разыскивает файл в стандартных системных каталогах. Если имя_файла заключено в кавычки, то вначале препроцессор просматривает текущий каталог пользователя и только затем обращается к просмотру стандартных системных каталогов.
#include <stdio.h>
#define SIZE 4

void main(void) {
float u[SIZE], /* Входной вектор */
b[SIZE][SIZE], /* Входная матрица */
v[SIZE], /* Вектор b*u */
z, /* Результат */
scalar(); /* Скалярное произведение векторов */
int i, j;
printf ("Исходный вектор: \n");
for (i=0; i<SIZE; i++) {
scanf ("%f", &u[i]);}
printf ("Исходная матрица: \n");
for (i=0; i<SIZE; i++) {
for (j=0; j<SIZE; j++) {
scanf ("%f", &b[i][j]); } }
matrix(b, u, v);
z=scalar(v, u);
printf (" \n \n \n Квадратичная форма равна %.5g \n", z);
} /* End main */
/* Умножение матрицы на вектор */
void matrix (float a[][SIZE], float x[], float y[]) {
int i, j;
for (i=0; i<SIZE; i++) {
for (y[i]=j=0; j<SIZE; j++) {
y[i] += a[i][j]*x[j];
}
}
} /* End matrix */
/* Скалярное произведение векторов */
float scalar (float x[], float y[]) {
int i;
for (z = i = 0; i<SIZE; i++) {
z += x[i]*y[i];
}
return z;
} /* End scalar */
Глава 9 Символьная информация и строки
Для представления текстовой информации в языке СИ используются символы (константы), символьные переменные и строки (строковые константы), для которых в языке СИ не введено отдельного типа в отличие от некоторых других языков программирования.
Символьные константы используются для изображения отдельных знаков, имеющих индивидуальные внутренние коды. Каждая символьная константа – это лексема (элемент языка СИ), которая состоит из изображения символа и ограничивающих апострофов: ‘A’, ‘a’,’B’,’8’,’+’,’;’.
Внутри апострофов можно записать любой символ, изображаемый на экране или принтере в текстовом режиме а также управляющие символы.
Для символьных данных (переменных) введен базовый тип char. Описание символьных переменных имеет вид:
char список_имен_переменных;
Пример:
char a, z;
9.1 Ввод - вывод символьных данных
Для ввода и вывода символьных значений в форматных строках библиотечных функций printf() и scanf() используется спецификация преобразования % c.
Пример:
Ввести предложение, слова в котором разделены пробелами и в конце которого стоит точка. Удалить повторяющиеся пробелы между отдельными словами (оставить по одному пробелу), вывести отредактированное предложение на экран.
/* удаление повторяющихся пробелов */
#include<stdio.h>
void main()
{
char z,s; /*z–текущий вводимый символ*/
/*s–предыдущий введенный символ*/
printf(“\nНапишите предложение с точкой в конце: \n”);
for (z=s=’ ’;z!=’.’;s=z) {
scanf(“%c”,&z); // z=getch();
if (z! =’ ‘ || s!=’ ‘)
printf(“%c”,z); } /*конец цикла обработки*/
} /*конец программы*/
В программе две символьные переменные: z – для чтения очередного символа и s – для хранения предыдущего. В заголовке цикла переменные s и z получают значение “пробел”. Очередной символ вводится как значение переменной z, и пара z, s анализируется. Если хотя бы один из символов значений пары отличен от пробела, то значение z печатается. В заголовке цикла z сравнивается с символом “точка” и при несовпадении запоминается как значение s. Далее цикл повторяется до появления на входе точки, причем появление двух пробелов (z и s)приводит к пропуску оператора печати.
9.2 Внутренние коды и упорядоченность символов
ВАЖНО! В языке принято соглашение, что везде, где синтаксис позволяет использовать целые числа, можно использовать и символы, т.е. данные типа char, которые при этом представляются числовыми значениями своих внутренних кодов. Такое соглашение позволяет сравнительно просто упорядочивать символы, обращаясь с ними как с целочисленными величинами.
Например, внутренние коды десятичных цифр в таблицах кодов ASCII упорядочены по числовым значениям, поэтому несложно перебирать символы десятичных цифр в нужном порядке.
Пример:
Следующая программа печатает цифры от 0 до 9 и шестнадцатеричные представления их внутренних кодов.
/*печать десятичных цифр*/
#include<stdio.h>
void main()
{ char z;
for (z=’0’, z<=’9’, z++) {
if (z= =’0’ | |z= =’5’) printf(“\n”);
printf(“%c – %x”, z, z);
}
} /*конец программы*/
Результат выполнения программы:
0–30 1–31 2–32 3–33 4–34
5–35 6–36 7–37 8–38 9–39
Обратите внимание на то, что символьная переменная z является операндом арифметической операции ‘ ++ ’, выполняемой над числовым представлением ее внутреннего кода. Для изображения значения символов в форматной строке функции printf() используется спецификация %с. шестнадцатеричные коды выводятся с помощью спецификации %х.
Пример:
Воспользовавшись упорядоченностью внутренних кодов букв латинского алфавита, очень просто его напечатать.
/*печать латинского алфавита*/
#include<stdio.h>
void main() {
char z;
for (z=’A’, z<=’Z’, z++)
printf(“%c”,z);
} /*конец программы*/
Результат выполнения программы:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
9.3 Строки или строковые константы
В программе строки, или строковые константы, представляются последовательностью изображений символов, заключенной в кавычки (не в апострофы), например “любые символы”. Среди символов строки могут быть эскейп-последовательности, соответствующие кодам не изображаемых (специальных) символьных констант.
Примеры:
“1234567890”
“\t состав президиума”
“начало строки \t и конец строки”.
В качестве терминирующего символа выбран символ с кодом 0 (не путайте его с символом '0'). Таким образом, определение
char HelloStr [] = "Hello, world";
фактически интерпретируется как
char HelloStr [] = {'H', 'e', 'l', 'l', 'o', ' ', ',', 'w', 'o', 'r', 'l', 'd', '\0'};
Это происходит при инициализации массива строкой. Во всех остальных случаях встретившаяся строка интерпретируется как еще не созданный безымянный массив соответствующей длины. То есть выражение
printf ("Hello, world\n");
на самом деле интерпретируется как
char str1 [ ] = "Hello, world\n";
printf (str1);
При размещении строки в памяти транслятор автоматически добавляет в ее конец символ ‘\0’, т.е. нулевой байт.
Количество элементов в таком массиве на 1 больше, чем в изображении соответствующей строковой константы, т.к. в конец строки добавили нулевой байт ‘\0’.
У строк есть еще особенность: транслятор отводит каждой строке отдельное место в памяти ЭВМ даже в тех случаях, когда несколько строк полностью совпадают (стандарт языка СИ предполагает, что в конкретных реализациях это правило может не выполняться).
Присвоить значение массиву символов (т.е. строке) с помощью обычного оператора присваивания нельзя. Поместить строку в массив можно либо с помощью инициализации (при определении символьного массива), либо с помощью функций ввода. В функции scanf() или printf() для символьных строк используется спецификация преобразования %s.
Пример:
/*печать символьной строки*/
#include<stdio.h>
void main()
{ char B[]=”Cезам, откройся!”;
printf(“%s”,B); } /*конец программы*/
Результат выполнения программы: Сезам, откройся!
В программе длина массива В – 17 элементов, т.е. длина строки, помещаемой в массив (16 символов), плюс нулевой байт окончания строки. Именно 17 байтов выделяется при инициализации массива в приведенном примере. Инициализация массива символов с помощью строковой константы представляет собой сокращенный вариант инициализации массива и введена в язык для упрощения. Можно воспользоваться обычной инициализацией, поместив начальные значения элементов массива в фигурные скобки и не забыв при этом поместить в конце списка начальных значений специальный символ окончания строки ‘\0’. Таким образом, в программе была допустима такая инициализация массива В:
char B[ ] = {‘C’,’е’,’з’,’а’,’м’,’,’,’ ’,’о’,’т’,’к’,’р’,’о’,’й’,’с’,’я’,’!’,’\0’};
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 457; Нарушение авторских прав?; Мы поможем в написании вашей работы!