КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сравнение моделей знаний
|
|
|
|
Пример
Семантические сети представляют собой ориентированные графы с помеченными дугами. Аппарат семантических сетей является естественной формализацией ассоциативных связей, которыми пользуется человек при извлечении каких-то новых фактов из имеющихся. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т. п.
Модель семантических сетей
Обычно в семантической сети предусматриваются четыре категории вершин:
- понятия (объекты),
- события,
- свойства,
- значения.
Понятия представляют собой константы или параметры, которые определяют физические или абстрактные объекты.
События представляют действия, происходящие в реальном мире, и определяются указанием типа действия и ролей, которые играют объекты в этом действии.
Свойства используются для представления состояния или для модификации понятий и событий.
Сведения семантической сети образуют сценарий, который является набором понятий, событий и причинно-следственных связей.
Необходимо различать вершины, обозначающие экземпляры объектов, и вершины, представляющие классы объектов. Например, Новиков - экземпляр типа Студент. В семантической сети экземпляр может принадлежать более чем одному классу (Новиков – и Студент, и Спортсмен).
В других моделях в отличие от семантической сети типы объектов указаны в схеме, а экземпляры объектов представлены значениями в базе данных. В семантической сети один и тотже экземпляр объекта может быть соотнесен с несколькими типами.
В синтаксических моделях (реляционной, сетевой или иерархической) для обеспечения такой связи потребуется дублирование информации об объекте.
|
|
|
Все семантические отношения предметной области можно разделить на следующие:
- лингвистические,
- логические,
- теоретико-множественные,
- квантификационные.
Лингвистические отношения бывают глагольные (время, вид, род, число, залог, наклонение) и атрибутивные (модификация, размер, форма).
Логические отношения подразделяются на конъюнкцию (и), дизъюнкцию (или), отрицание (не) и импликацию (если – то).
Теоретико-множественные отношения - это отношение подмножества, отношение части и целого, отношение множества и элемента.
Квантификационные отношения делятся на логические кванторы общности и существования («каждый», «все»), нелогические кванторы («много», «несколько») и числовые характеристики.
При установлении структуры понятий существуют две обязательные связи
1- связь "есть-нек" (от слов "есть некоторый"). Направлена от частного понятия к более общему и показывает принадлежность элемента к классу;
2- связь "есть-часть". Показывает, что объект содержит в своем составе разнородные компоненты (объекты), не подобные данному объекту.
Пример семантической сети для описания структуры понятия "юридическое лицо" приведен на следующем рисунке.
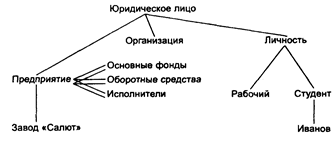
Рисунок 4.2 Элементы семантической сети
Связь "есть-нек" обозначается одной линией, связь "есть-часть" – двумя.
Рассмотрим представление событий и действий с помощью семантической сети. Выделяются простые отношения, которые характеризуют основные компоненты события. В первую очередь из события выделяется действие, которое обычно описывается глаголом. Далее необходимо определить объекты, которые действуют, объекты, над которыми эти действия производятся, и т. д. Все эти связи предметов, событий и качеств с глаголом называются падежами. Обычно рассматривают следующие падежи:
|
|
|
1. агент - предмет, являющийся инициатором действия;
2. объект - предмет, подвергающийся действию;
3. источник - размещение предмета перед действием;
4. приемник - размещение предмета после действия;
5. время - указание на то, когда происходит событие;
6. место - указание на то, где происходит событие;
7. цель - указание на цель действия.
Рассмотрим пример: Директор завода "САЛЮТ" остановил 25.03.90 цех № 4, чтобы заменить оборудование
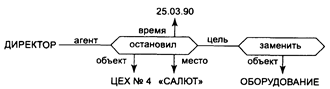
Рисунок 4.3 Пример семантической сети
Преимущества семантических сетей:
1) описание объектов и событий на уровне, очень близком к естественному языку;
2) обеспечивается возможность сцепления различных фрагментов сети;
3) возможные отношения между понятиями и событиями образуют достаточно небольшое и хорошо формализованное множество;
4) можно выделить из полной сети, представляющей все знания, некоторый участок семантической сети, который необходим в конкретном запросе.
4.4. Базы знаний
В современных системах управления вопрос о принятии решений информационной системой требует фиксации знаний об управляемом объекте и реализации моделей принятия решений, характерных для человека-специалиста (инженера, технолога, экономиста, бухгалтера). Способность человека накапливать и использовать знания, принимать решения можно назвать естественным интеллектом, соответствующие возможности информационной системы получили название искусственный интеллект.
Система понятий для представления знаний существенно отличается от понятий для представления данных, поэтому отображение знаний производится в базу знаний. Вместе с тем база знаний способна хранить данные как простую разновидность знаний.
Запросы, которые формулируются пользователями информационной системы, реализуются одним из двух возможных способов:
- сообщения, являющиеся ответом на запрос, хранятся в явном виде в БД, и процесс получения ответа представляет собой выделение подмножества значений из файлов БД, удовлетворяющих запросу;
- ответ не существует в явном виде в БД и формируется в процессе логического вывода на основании имеющихся данных.
Последний случай принципиально отличается от рассмотренной ранее технологии использования баз данных и рассматривается в рамках представления знаний, т. е. информации, необходимой в процессе вывода новых фактов. База знаний содержит:
|
|
|
- сведения, которые отражают существующие в предметной области закономерности и позволяют выводить новые факты, справедливые в данном состоянии предметной области, но отсутствующие в БД, а также прогнозировать потенциально возможные состояния предметной области;
- сведения о структуре ЭИС и БД (метаинформация);
- сведения, обеспечивающие понимание входного языка, т. е. перевод входных запросов во внутренний язык.
Принято говорить не о "знаниях вообще", а о знаниях, зафиксированных с помощью той или иной модели знаний.
Принципиальными различиями обладают три модели представления знаний - продукционная модель, модель фреймов и модель семантических сетей.
4.5. Продукционная модель знаний
Продукционная модель состоит из трех основных компонентов:
- набора правил, представляющего собой в продукционной системе базу знаний;
- рабочей памяти, в которой хранятся исходные факты и результаты выводов, полученных из этих фактов;
- механизма логического вывода, использующего правила ц соответствии с содержимым рабочей памяти и формирующего новые факты.
Каждое правило содержит условную и заключительную части. В условной части правила находится одиночный факт либо несколько фактов (условий), соединенных логической операцией "И".
В заключительной части правила находятся факты, которые необходимо дополнительно сформировать в рабочей памяти, если условная часть правила является истинной.
Предположим, что в рабочей памяти хранятся следующие факты:
-доля выборки записей равна 0,09;
- ЭВМ - PC XT.
Правила логического вывода имеют вид:
1) Если метод доступа индексный, то СУБД - dBASE 3.
2) Если метод доступа последовательный, то СУБД - dBASE 3.
3) Если доля выборки записей <0,1, то метод доступа - индексный.
4) Если СУБД - dBASE 3 и ЭВМ - PC XT, то программист -Иванов.
Механизм вывода сопоставляет факты из условной части каждого правила с фактами, хранящимися в рабочей памяти. В данном примере сопоставление условия правила 3 с фактами из рабочей памяти приводит к добавлению нового факта "Метод доступа - индексный" и исключению правила 3 из списка применяемых правил.
|
|
|
С учетом нового факта становится справедливой условная часть правила 1, и в рабочей памяти появляется факт "СУБД -dBASE З". Далее становится применимым правило 4, что приводит к фиксации в рабочей памяти факта "Программист - Иванов". В этот момент дальнейшее применение правил невозможно, и процесс вывода останавливается. Наш пример показывает, что применимость каждого правила из базы знаний в процессе вывода вовсе не обязательна.
Новые факты, полученные механизмом вывода:
- метод доступа - индексный,
-СУБД-dBASE 3,
- программист - Иванов.
В приведенном примере для получения вывода правила применялись к фактам, записанным в рабочей памяти, и в результате применения правил добавлялись новые факты. Такой способ действий называется прямым выводом. Возможен также обратный вывод целей. В качестве цели выступает подтверждение истинности факта, отсутствующего в рабочей памяти. При обратном выводе исследуется возможность применения правил, подтверждающих цель, необходимые для этого дополнительные факты становятся новыми целями и процесс повторяется.
Предположим, что в нашем примере запрос цели имеет вид:
? "программист - Иванов".
Эта цель подтверждается правилом 4. Необходимые для правила 4 факты - "ЭВМ - PC XT" и "СУБД - dBASE 3". Первыйизних присутствует в рабочей памяти, а второй становится новой целью. Для этой цели требуется подтверждение правила 1 или правила 2. Факт-условие правила 2 не содержится в рабочей памяти и не является заключением существующих правил. Поэтому данная ветвь обратного вывода обрывается. Для применения правила 1 необходим факт "Метод доступа - индексный", он является заключением правила 3, а условие правила 3 соблюдается (в рабочей памяти хранится факт "Доля выборки записей равна 0.09").
В итоге первоначальная цель "программист-Иванов" признается истинной.
В случае обратного вывода условием останова системы является окончание списка правил, которые относятся к доказываемым целям. При прямом выводе останов происходит по окончании списка применимых правил. Следует отметить, что на каждом шаге вывода количество одновременно применимых правил может быть любым (в отличие от примеров, приведенных выше). Последовательность выбора подходящих правил не влияет на однозначность получаемого ответа; однако может существенно увеличить требуемое число шагов вывода. В реальных базах знаний с большим числом правил это может существенно снизить быстродействие системы. В системах с обратным выводом есть возможность исключить из рассмотрения правила, не имеющие отношения к выводу требуемых целей, и тем самым несколько ослабить указанный отрицательный эффект. По этой причине системы с обратным выводом целей получили большее распространение.
Представление знаний в виде набора правил имеет следующие преимущества:
- простота создания и понимания отдельных правил;
- простота механизма логического вывода.
К недостаткам этого способа организации базы знаний относятся:
- неясность взаимных отношений правил;
- отличие от человеческой структуры знаний.
4.6. Фреймы
В основе теории фреймов лежит фиксация знаний путем сопоставления новых фактов с рамками, определенными для каждого объекта в сознании человека. Структура в памяти ЭВМ, представляющая эти рамки, называется фреймом. С помощью фреймов мы пытаемся представить процесс систематизации знаний в форме, максимально близкой к принципам систематизации знаний человеком.
Фрейм представляет собой таблицу, структура и принципы организации которой являются развитием понятия отношения в реляционной модели данных. Новизна фреймов определяется двумя условиями:
1) имя атрибута может в ряде случаев занимать в фрейме позицию значения,
2) значением атрибута может служить имя другого фрейма или имя программно реализованной процедуры. Структура фрейма показана ниже.
Слотом фрейма называется элемент данных, предназначенный для фиксации знаний об объекте, которому отведен данный фрейм. Перечислим параметры слотов.
Имя слота. Каждый слот должен иметь уникальное имя во фрейме, к которому он принадлежит. Имя слота в некоторых случаях может быть служебным. Среди служебных имен отметим имя пользователя, определяющего фрейм; дату определения или модификации фрейма; комментарий.
Указатель наследования. Он показывает, какую информацию об атрибутах слотов во фрейме верхнего уровня наследуют слоты с теми же именами во фрейме нижнего уровня. Приведем типичные указатели наследования:
S (тот же). Слот наследуется с теми же значениями данных;
U (уникальный). Слот наследуется, но данные могут принимать любые значения;
I (независимый). Слот не наследуется.
Указатель типа данных. К типам данных относятся:
FRAME (указатель) - указывает имя фрейма верхнего уровня;
ATOM (переменная),
TEXT (текстовая информация),
LIST (список),
LISP (присоединенная процедура).
С помощью механизма управления наследованием по отношениям "есть-нек" осуществляются автоматический поиск и определение значений слотов фрейма верхнего уровня и присоединенных процедур.
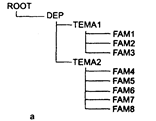
Рассмотримпример использования системы фреймов. Иерархия фреймов, показанная на рис. 4.4.а, отображает организационную структуру и работы, выполняемые в некотором отделе конструкторского бюро. Она предназначена для фиксации факта окончания отдельных работ исполнителями, группами и отделом в целом. Фрейм ROOT является стандартным фреймом, все другие фреймы должны быть подчинены ему. Слот АКО используется для установления иерархии фреймов.
Работа начинается посредством передачи сообщения в слот фрейма верхнего уровня DEP. При этом запускается присоединенная процедура, которая передает в фреймы нижнего уровня значение текущей даты. Когда происходит заполнение какого-то слота в фрейме, делается попытка дать значения всем слотам этого фрейма, в том числе попытка выполнения присоединенной процедуры.
Фреймовые системы обеспечивают ряд преимуществ по сравнению с продукционной моделью представления знаний:
1)знания организованы на основе концептуальных объектов;
2)допускается комбинация представления декларативных (как устроен объект) и процедурных (как взаимодействует объект) знаний;
3)иерархия фреймов вполне соответствует классификации понятий, привычной для восприятия человеком;
4)система фреймов легко расширяется и модифицируется.
Трудности применения фреймовой модели знаний в основном связаны с программированием присоединенных процедур.
| Имя слота | Указатель наследования | Указатель Типа | Значение слота |
| FRAME-NAME: DEP | |||
| АКО | (U) ROOT | FRAME ROOT | |
| DESINF | (U) ROOT | TEXT | (ОТДЕЛ 23) |
| DATE | (U) ROOT | LIST | |
| ТЕМА | (I).TOP. | LIST | (TEMA1 ТЕМА2) |
| ТЕМА1 | (I) «TOP» | LIST | NIL |
| ТЕМА2 | (I).TOP. | LIST | NIL |
| FLAG1 | (I) «TOP. | ATOM | |
| FLAG2 | (I) •TOP. | ATOM | |
| LOGIC | (U) «TOP. | LISP | MAIN |
| FRAME-NAME: TEMA1 | |||
| АКО | (U) ROOT | FRAME DEP | |
| DESINF | (U) ROOT | TEXT | (КОНСТРУИРОВАНИЕ ПЛЕЕРА) |
| DAE | (U) ROOT | LIST | |
| FAM | (I) «TOP. | LIST | (FAM1 FAM2 FAM3) |
| FAM1 | (I) •TOP» | LIST | NIL |
| FAM2 | (I) «TOP. | LIST | NIL |
| FAM3 | (I) •TOP. | LIST | NIL |
| FLAG1 | (1).TOP* | ATOM | |
| FLAG2 | (1) «TOP» | ATOM | |
| FLAG3 | (1) •TOP» | ATOM | |
| LOGIC | (U) •TOP. | LISP | COMP1 |
| FRAME-NAME: FAM1 | |||
| AKO | (U) ROOT | FRAME TEMA1 | |
| DESINF | (U) ROOT | TEXT | (ЛЕНТОПРОТЯЖНЫЙ |
| МЕХАНИЗМ) | |||
| DATE | (U) ROOT | LIST | |
| TODAY | (1) «TOP» | ATOM | |
| ENDDATE | (1).TOP. | ATOM | 02.04.91 |
| LOGIC | (U).TOP» | LISP | COMPDATE |
Рисунок 4.4 Пример базы знаний фреймового типа:
а - иерархия фреймов; б - значения слотов
4.7. Семантические сети для представления знаний
Особенность семантической сети как модели знаний состоит в единстве базы знаний и механизма вывода новых фактов. На основании вопроса к базе знаний строится семантическая сеть, отображающая структуру вопроса, и ответ получается в результате сопоставления общей сети для базы знаний в целом и сети для вопроса.
Рассмотрим пример семантической сети, отображающий подчиненность сотрудников в отделе учреждения, приведенный на рис. 35,а. Приводятся связи, показывающие подчиненность первого сотрудника. Остальные сотрудники отдела связываются через вершины сети связями типа "руководит 2", "руководит 3" и т. д.
Вопрос "Кто руководит Серовым?" представляется в виде подсети, показанной на рис. 4.5,б. Сопоставление общей сети с сетью запроса начинается с фиксации вершины "руководит", имеющей ветвь "объект", направленную к вершине "Серов". Затем производится переход по ветви "руководит", что и приводит к ответу "Петров"
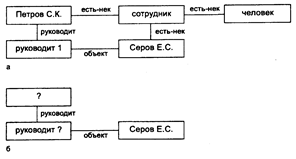
Рисунок 4.5 Примеры: а - семантической сети;
б - сети логического вывода для запроса
Преимущества семантических сетей состоят в том, что это достаточно понятный способ представления знаний на основе отношений между вершинами и дугами сети. Однако с увеличением размеров сети ухудшается се обозримость и увеличивается время вывода новых фактов с помощью механизма сопоставления.
Модели знаний - продукционная, фреймовая и модель семантических сетей - обладают практически равными возможностями представления знаний, использующих отношения "есть-нек" и "есть-часть". Дополнительно каждая модель знаний содержит средства усиления этой "базовой" конфигурации:
- продукционная модель позволяет легко расширять и усложнять множество правил вывода;
- фреймовая модель позволяет усилить вычислительные аспекты обработки знаний за счет расширения множества присоединенных процедур;
- модель семантических сетей позволяет расширять список отношений между вершинами и дугами сети, приближая выразительные возможности сети к уровню естественного языка.
4.9. Тезаурусы экономической информации
Первоначально идея разработки тезаурусов возникла в словарной практике в связи с составлением толковых словарей, как средство описания семантической структуры естественного языка. Затем они были применены в практике автоматизированных информационно-поисковых систем для обеспечения избыточного индексирования документов и информационных запросов. Под избыточным индексированием понимается дополнение поискового образа документов дополнительными дескрипторами, которые связаны по смыслу с основными дескрипторами.
Тезаурус - это словарь-справочник, в котором перечислены все лексические единицы ИМЯ с синонимичными им словами, а также выражены все важнейшие смысловые (парадигматические) отношения между лексическими единицами.
Тезаурус, как элемент информационного языка, выполняет следующие функции:
- средство формализации лексики;
- средство терминологического контроля;
- средство избыточного индексирования информационных запросов;
- средство выражения парадигматических отношений языка.
Основные этапы разработки тезауруса следующие:
а) Выбор источников лексики и отбор терминов.
б) Составление терминологического словаря.
в) Группировка терминов в тематические классы.
г) Формирование классов условной эквивалентности.
д) Установление парадигматических отношений.
е) Определение структуры тезауруса.
а) Для отбора лексического материала необходимо использовать экономические документы, отражающие характеристики экономического объекта. Кроме того, надо пользоваться такими вспомогательными средствами, как толковые и терминологические словари, справочники по исследуемой тематике, общесоюзные классификаторы.
Отбор терминов определяется специальными правилами. Перечислим некоторые из них:
- узкие термины применять, если в словаре отсутствуют подходящие общие термины;
- многословный термин вводить в том случае, если встречается довольно часто;
- прилагательное следует употреблять в сочетании с существительным.
б) В терминологическом словаре каждому отобранному термину дается определение, соответствующее его экономическому смыслу. Терминологический словарь служит в качестве пособия при формировании запросов конечными пользователями.
в) Все термины классифицируются в зависимости от функционального назначения в тематические классы. Ниже приведен перечень тематических классов экономической лексики:
1) Экономические категории, действия, события
2) Субъекты действия
3) Объекты действия
4) Назначение действия
5) Место действия
6) Источник поступления (финансирования)
7) Время действия
8) Функция управления
9) Единица измерения
10)Атрибутивные характеристики действия (разряд работ и т. п.)
11) Обоснование действия
12) Причина отклонения.
г) Дальнейшая работа по составлению тезауруса заключается в устранении многозначности (омонимия, полисемия) и синонимии терминов.
Омонимия - это совпадение в звучании и написании разных слов. Например: лук (растение) и лук (оружие).
Полисемия - это перенос названия одного предмета на другие предметы. Например: звезда (геометрическая фигура) и звезда (небесное тело), матрица (математическая) и матрица (техническая).
Омонимия и полисемия устраняются лексикографически при редактировании терминологического словаря.
Синонимия заключается в том, что одному "означаемому" (предмету, явлению) соответствует одно и более "означающих" (слов, словосочетаний). Например: алфавит - азбука, студенты - студенчество.
При построении тезауруса устранение синонимии производится путем группировки терминов в классы условной эквивалентности (КУЭ).
В КУЭ объединяются термины, между объемами понятий которых существуют отношения:
- равнозначности (геомагнетизм - земной магнетизм);
- перекрещивания, когда часть объема одного понятия входит в объем другого(книга - монография);
- подчинения, когда объем одного понятия составляет часть объема другого понятия (стол - мебель);
- внеположенности, когда объемы понятий полностью исключают друг друга и при этом не исчерпывают области предметов, о которых ведется рассуждение (стол - стул: общий класс - мебель).
В результате формирования классов условной эквивалентности термины тезауруса группируются в синонимические ряды. В каждом синонимическом ряду выделяется доминанта, то есть такой термин, который может заменить любое слово класса. Доминанту принято называть дескриптором. Однако фактически дескриптором является не имя КУЭ, а сам этот класс.
д) Парадигматические отношения в тезаурусах могут выражаться четырьмя способами:
- лексикографически;
- при помощи таблиц;
- аналитически;
- графически.
Лексикографический способ предполагает наличие специальных помет, которые указывают, в каких парадигматических отношениях находится данный дескриптор с заглавным. При этом используются условные обозначения, рекомендуемые ГОСТом, а именно:
н - нижестоящий видовой дескриптор по отношению к заглавному дескриптору;
в - вышестоящий родовой дескриптор по отношению к заглавному дескриптору;
ц - дескриптор находится в отношении - целое к заглавному дескриптору;
ч - дескриптор находится в отношении - часть к заглавному дескриптору;
с - ключевое слово находится в отношении синонимии к заглавному дескриптору;
см - отсылка от ключевого слова к дескриптору.
Табличный способ заключается в том, что под заглавным дескриптором записываются со сдвигом на несколько знаков вправо дескрипторы, находящиеся с ним в определенном отношении. Такой способ применяется в библиотечно-библиографических классификациях.
При аналитическом способе парадигматические отношения выражаются при помощи структуры кодов дескрипторов. Примером применения аналитического способа может служить универсальная десятичная классификация.
Графический способ предполагает применение различных графических схем.
Терминам экономических документов присущи отношения "вид-род", обозначающие смысловую соподчиненность терминов, и "целое-часть", дающие математическую взаимосвязь экономических категорий. Поэтому наиболее удобным будет сочетание лексикографического и табличного способов выражения парадигматических отношений.
е) Структура тезауруса влияет на результаты поиска и соответственно на эффективность работы всей системы.
Как правило, тезаурус представляется в виде совокупности расположенных в алфавитном порядке дескрипторных статей (семантических сегментов). Они представляет собой совокупность заглавного дескриптора и всех дескрипторов, связанных с ним какими-либо парадигматическими отношениями, а также ключевых слов-синонимов. Например:
Выпуск
с выпущено
с выработано
с произведено
с производство
Кольца уплотнительные круглого сечения
в Кольца уплотнительные
н Кольца резиновые уплотнительные круглого сечения, резина группы О
н Кольца резиновые уплотнительные круглого сечения, резина группы 1
Вопросы для самоконтроля к главе 3
1.Для чего служат семантические модели данных?
2.Какие уровни интерпретации имеют семантические модели?
3.Как отображается структура предметной области в модели сущностей и связей?
4.В чем недостатки модели «сущность-связь»?
5.Как отображается структура предметной области в модели семантической сети?
6.Что означают вершины графов в семантической сети?
7.Как отображаются связи между понятиями семантической сети? Что означает одинарная или двойная линия?
8.Что такое падежи семантической сети?
9.В чем преимущества семантической сети?
10.Как понимаете понятие искусственный интеллект?
11.В чем принципиальное отличие реализации запросов в базах знаний и базах данных?
12.Какие существуют принципиально различные модели знаний?
13.Что представляет собой продукционная модель знаний?
14.Как получаются новые знания в продукционной модели знаний?
15.Как ускорить процесс получения вывода в продукционной модели знаний?
16.В чем преимущества и недостатки продукционной модели знаний?
17. Что представляет собой фреймовая модель знаний?
18.Что представляет собой фрейм?
19.Что входит в структуру фрейма?
20.Как получаются новые знания в фреймовой модели знаний?
21.В чем преимущества и недостатки фреймовой модели?
22.Какие преимущества имеет та или иная модель знаний?
23.Что такое тезаурус?
24.Какие функции выполняет тезаурус?
25.Какие основные этапы разработки тезауруса?
26.В какие тематические классы объединяются все экономические понятия?
27.Для чего нужны классы условной эквивалентности?
28.Что такое дискриптор?
29.Какими способами отображаются парадигматические отношения в тезаурусах?
30.Что представляет собой структура тезауруса?
Терминологический словарь
Адрес связи - атрибут, в котором хранится начальный адрес или номер записи, обрабатываемой после этой записи. Обычная последовательность обработки записей в списке определяется возрастанием значений ключа в записях.
Атрибут – единица информации,информационное отображение отдельного свойства некоторого объекта, процесса или явления.
Атрибут-основание - отображение количественного свойства некоторого объекта, предмета, процесса.
Атрибут-признак - информационное отображение качественного свойства некоторого объекта, предмета, процесса.
Ацикличность – процедура позволяющая улучшить характеристики БД, чтобы при корректировке или перестройке отношений не было двусмысленности или потери информации.
База данных (БД) - это набор форматированных сообщений,
Бинарное дерево – древовидная организация данных, когда значение ключевого атрибута каждой записи больше, чем значение ключа у любой записи на ее левой ветви, и не меньше, чем ключ любой записи на ее правой ветви.
Веерное отношение - называется пара отношений, состоящая из одного основного, одного зависимого отношения и связи между ними при условии, что каждое значение зависимого отношения связано с единственным значением основного отношения.
Вероятный ключотношения - такое множество атрибутов, что каждое сочетание их значений встречается только в одной строке отношения, и никакое подмножество атрибутов этим свойством не обладает. Вероятных ключей в отношении может быть несколько.
Взаимодействие объектов - факт участия нескольких объектов в каком-либо процессе, который протекает и во времени, и в пространстве
Внутреннее описание - определяет организацию данных в памяти ЭВМ и методы доступа к данным..
Время поиска данных - нахождение значения ключевого атрибута равного заранее известной величине;
Время корректировки данных - т.е. включение или исключение одной записи;
Выборка - операция выделения подмножества значений СЕИ (строк), которые удовлетворяют заранее поставленным условиям выборки.
Дескриптор – доминанта в классе условной эквивалентности, то есть такой термин, который может заменить любое слово класса.
Документ - материальный носитель информации, содержащий оформленное в установленном порядке сообщение и имеющий юридическую силу.
Домен – множество всех допустимых значений атрибута
Древовидная организация данных (дерево) – метод организации данных, множество записей расположены определенным образом по уровням:
- на 1-м уровне расположена только одна запись (корень дерева),
- к любой записи i-го уровня ведет адрес связи только от одной записи уровня i-1.
Единицы информации -набор символов, которому придается определенный смысл (атрибуты и составные единицы информации).
Идентифицирующие свойства - свойства, по значению которых можно однозначно отличить данный экземпляр объекта от любого другого (в том числе и в пределах класса объектов, содержащего этот экземпляр).
Иерархическая база данных - множество отношений и веерных отношений, для которых соблюдаются два ограничения:
1) существует единственное отношение, называемое корневым, которое не является зависимым ни в одном веерном отношении.
2) все остальные отношения (за исключением корневого) являются зависимыми отношениями только в одном веерном отношении.
Иерархическая модель данных – модель данных, допустимыми информационными конструкциями которой являются отношение, веерное отношение и иерархическая база данных.
Индексирование - выражение тем на языке, принятом в информационно-поисковой системе, и записи в виде поисковых образов, которые связываются с документом.
Информация – ресурсы; новые сведения, позволяющие улучшить процессы, связанные с преобразованием вещества, энергии и самой информации, принятые, понятые и оцененные конечным потребителем как полезные
Концептуальная схема - описание структуры всех единиц информации, хранящихся в БД.
Концептуальное представление - информационное содержание базы данных в абстрактной форме. Цель концептуального уровня - создать такое формальное представление о базе данных, чтобы любое внешнее представление являлось его подмножеством.
Корректировка - включение и исключение записей
КУЭ - классы условной эквивалентности.
Неполная функциальная зависимость - это две зависимости:
- вероятный ключ отношения функционально определяет некоторый неключевой атрибут,
- часть вероятного ключа функционально определяет этот же неключевой атрибут.
Нормализация - это операция перехода от СЕИ с произвольной структурой к СЕИ с двухуровневой структурой, позволяющая улучшить характеристики БД по минимальность избыточности представления информации.
Объект - любой элемент некоторой системы. В экономических приложениях это любой предмет, занимающий место в пространстве.
Омонимия - совпадение в звучании и написании разных слов. Например: лук (растение) и лук (оружие).
Организация значений данных - относительно устойчивый порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между данными.
Отношение – таблица, с двухуровневой структурой
Отношение в первой нормальной форме (1 НФ) - это обычное отношение с двухуровневой структурой. Недопустимость в структуре отношения третьего и последующих уровней является ограничением, определяющим 1НФ отношения.
Отношение во второй нормальной форме (2НФ) - если оно соответствует 1НФ и не содержит неполных функциональных зависимостей.
Отношение в третьей нормальной форме (3 НФ) - если оно соответствует 2НФ и среди его атрибутов отсутствуют транзитивные функциональные зависимости (ФЗ).
Пакетный режим обработки - данные в системе накапливаются до тех пор, пока не наступит заданный момент времени, или объем данных не превысит некоторый предел. Затем имеющаяся информация обрабатывается несколькими последовательно запускаемыми программами.
Первичный ключ отношения- такой вероятный ключ, по значениям которого производится контроль достоверности информации в отношении.
Поиск - процедура выделения из некоторого множества записей определенного подмножества, записи которого удовлетворяют некоторому заранее поставленному условию.
Показатель - представляет собой полное описание количественного параметра, характеризующего некоторый объект или процесс.
Полисемия - перенос названия одного предмета на другие предметы. Например: звезда (геометрическая фигура) и звезда (небесное тело).
Порядковая система кодирования – нумерация, применяемая, если классификация объектов вообще не требуется.
Последовательная организация данных – метод организации данных, когда записи располагаются в памяти строго одна за другой, без промежутков.
Предметная область - элементы материальной системы (объект, свойства объектов, взаимодействие объектов, свойства взаимодействия объектов), информация о которых хранится и обрабатывается в ЭИС.
Проекция – операция переноса в результирующее отношение тех столбцов исходного отношения, которые указаны в условии операции.
Простейшие СЕИ - таблицы, позволяющие создавать произвольные комбинации из атрибутов.
Разработка (проектирование) ЭИС - процесс составления описания еще не существующей системы на разных языках и с различной степенью детализации, в ходе которого осуществляется оптимизация проектных решений.
Реляционная база данных - модель данных, характеризующаяся следующими компонентами:
- информационной конструкцией - отношением с двухуровневой структурой,
- допустимыми операциями - проекцией, выборкой, соединением и другими
- ограничениями - функциональными зависимостями между атрибутами отношения.
Разрядная система кодирования – классификация объектов по нескольким признакам и их взаимная подчиненность соответствует выделению классов объектов, подклассов внутри каждого класса и т.д.
Свертка - операция преобразования СЕИ с двухуровневой структурой в СЕИ с произвольной многоуровневой структурой
Свойство объекта - некоторая величина, которая характеризует состояние объекта в любой момент времени. Отдельный экземпляр объекта можно точно описать, если указать достаточное количество значений его свойств.
Свойство взаимодействия - характеризует совместное поведение объектов, но не относится ни к одному объекту в отдельности..
Семантические модели - средство представления структуры предметной области.
Семантические сети - модель знаний, состоящая в единстве базы знаний и механизма вывода новых фактов. На основании вопроса к базе знаний строится семантическая сеть, отображающая структуру вопроса, и ответ получается в результате сопоставления общей сети для базы знаний в целом и сети для вопроса.
Серийная система кодирования – классификация объектов по одному признаку. Коды объектов разделяются на несколько частей (серий) по количеству значений этого признака и в пределах каждой серии использовать последовательные номера.
Сетевая база данных – модель данных, состоящая из множества отношений и веерных отношений. Отношения разделяются на основные и зависимые
Синонимия - одному "означаемому" (предмету, явлению) соответствует одно и более "означающих" (слов, словосочетаний).
Система – любой объект, который, с одной стороны, рассматривается как единое целое, а с другой - как множество связанных между собой или взаимодействующих составных частей
Слот фрейма - элемент данных, предназначенный для фиксации знаний об объекте, которому отведен данный фрейм.
Составная единица информации(СЕИ) - набор из атрибутов и, возможно, других СЕИ.
Система управления базой данных (СУБД) - комплекс программ, обеспечивающий централизованное хранение, накопление, модификацию и выдачу данных, входящих в БД.
Структура СЕИ - вхождение одних единиц информации в состав других единиц информации
Тезаурус -словарь-справочник, в котором перечислены все лексические единицы ИМЯ с синонимичными им словами, а также выражены все важнейшие смысловые (парадигматические) отношения между лексическими единицами.
Транзитивная ФЗ - это две ФЗ:
- вероятный ключ отношения функционально определяет не ключевой атрибут,
- этот атрибут функционально определяет другой не ключевой атрибут.
ФЗ – функциональная зависимость
Формирование данных - процедура упорядочения записей по ключевому атрибуту.
Продукционная модель – модель знаний, состоящая из набора правил и механизма логического вывода. Все правила содержат условную и заключительную части. В условной части правила находится одиночный факт либо несколько фактов. В заключительной части правила находятся факты, которые необходимо дополнительно сформировать в рабочей памяти, если условная часть правила является истинной.
Фреймы – модель знаний, структура знаний в памяти ЭВМ сопоставимая с рамками, определенными для каждого объекта в сознании человека. С помощью фреймов мы пытаемся представить процесс систематизации знаний в форме, максимально близкой к принципам систематизации знаний человеком.
Экономическая информация - информация о процессах производства, распределения, обмена и потребления материальных благ.
Экономическая информационная система - система, функционирование которой во времени заключается в сборе, хранении, обработке и выдачи информации о деятельности какого-то экономического объекта реального мира.
Эмерджентность - свойство системы обладать большими свойствами, чем составляющие ее элементы
Литература
1.Базилевич Л.А., Соколов Д.В., Франева Л.К. Модели и методы рационализации и проектирования организационных структур управления. –Л.: Изд. ЛФЭМ, 1991.
2.Герчикова И.Н. Менеджмент. 3 изд. – М.: Банки и биржи, ЮНИТИ, 1997.
3.Григоренко Г.П., ДаниленкоТ.Я.. Системы автоматизированной обработки информации (САОЭИ). Учебное пособие. –М.: МЭСИ, 1996.
4.Димов Э.М. Теория экономических информационных систем: Учебное пособие кафедры ЭИС ПГАТИ.
5.Долинская М.Г., Соловьев И.А.. Маркетинг и конкурентоспособность промышленной продукции. –М.: Издательство стандартов, 1991. –128 с.
6.Иватилов Ю.П., Лотов А.В. Математические модели в экономике. Под ред. Академика Моисеева Н.Н. Учебное пособие. –М.: Наука, 1979.
7.Информационные системы в экономике: Учебник под ред. В.В.Дика. – М.: Финансы и статистика, 1996. –272 с.
8.Кордонская И.Б., Диязитдинова А.Р. Детализированное описание организационной структуры компании. Методическая разработка для выполнения контрольной работы по ТЭИС. Изд. ПГАТИ, 15 с.
9.Криницкий Н.А., Миронов Г.А,, ФроловГ.Д. Автоматизированные информационные системы. Под ред. Академика Дородницина А.А. –М.: Наука, 1982.
10.Мисарович М., Марко Д., ТакахараИ. Теория иерархических информационных систем. Пер. с англ. –М.: Мир, 1973.
11.Мишенин А.И. Теория экономических информационных систем: Учебник. –4 изд. – М.: Финансы и статистика, 1999. – 240 с.
12.Ойхман Е.Г., Попов Э.В. Реинжиниринг бизнеса: Реинжиниринг организаций и информационные технологии. –М.: Финансы и статистика, 1997. –336 с.
13.Основы менеджмента. Учебное пособие для вузов / Научный ред. А.А.Радугин –М.: Центр, 1998.
14.Попов Э.В., Фоминых И.Б., Е.Б. Кисель, М.Д. Шапот. Статические и динамические экспертные системы: Учебное пособие, -М.: Финансы и статистика, 1996.
15.Романов А.Н., Одинцов Б.Е. Советующие информационные системы в экономике. Учебное пособие для вузов. –М.: ЮНИТИ-ДАНА, 2000.-487 с.
16.Якубайтис Э.Я. Информационные сети и системы: Справочная книга. М.: Финансы и статистика, 1996.
Содержание
Глава 1 Основные понятия экономических информационных систем.. 3
1.1 Основные понятия и определения экономических информационных систем ……………………………………………………………………………….3
1.2 Принципы построения и функционирования ЭИС …….……………5
1.3 Критерии эффективности ЭИС ………………..…………………… 6
1.4 Классификация ЭИС …………………..……………. 7
1.5 Теория организации. Использование концепции многоуровневых систем в теории организации ……………………..……………. 9
1.6 Формализация основных понятий теории организаций ив рамках теории многоуровневых систем …………………………………………. 13
1.7 Компоненты экономических информационных систем ……… … 17
1.8 Предметная область ………………………………………………… 18
1.9 Детализация представлений ЭИС ………………………………… 20
1.10 Классификация и основные свойства единиц информации …… 24
1.11 Экономические показатели и документы …………………….. 25
1.12 Жизненный цикл ЭИС ………………………………………… 27
1.13 Цели и методы модификации ЭИС …………………………… 28
Вопросы для самоконтроля к главе 1 …………………… …………. 30
Глава 2 Модели данных ……………………………… ……………... 31
2.1 Модели данных. Реляционная модель данных …………….. 31
2.2 Нормализация отношений ………… ……………………………. 34
2.3 Функциональные зависимости и ключи ……………… …… 37
2.4 Вторая и третья нормальные формы ……………… ……….. 38
2.5 Ациклические базы данных ……………… ……………… 40
2.6 Сетевая модель данных ………………………… ……………… 42
2.7 Организация веерного отношения в памяти ЭВМ ……………. 42
2.8 Иерархическая модель данных ……… …………………….. 44
2.9 Сравнение моделей данных ……………………………….. 45
2.10 Модель инвертированных файлов и информационно-поисковые системы ………………………………………………………………………… 46
Вопросы для самоконтроля к главе 2 ……….………………………… 48
Глава 3 Методы организации данных ………………………………. 49
3.1 Методы организации данных в памяти ЭВМ ………………… 49
3.2 Последовательная организация данных ……… …………….. 49
3.3 Цепная (списковая) организация данных ……… …………… 51
3.4 Древовидная организация данных ………… …………….. 53
3.5 Сравнение методов организации данных …………………… 55
3.6 организации данных во внешней памяти ЭВМ ………………. 56
Вопросы для самоконтроля к главе 3 ……….………………………… 56
Глава 4 Моделирование предметных областей в экономике.
Базы данных ………………………………………………………… 58
4.1 Семантические модели данных …………… …………. 58
4.2 Модель сущностей и связей …………………………….. 58
4.3 Модель семантических сетей …………………… ………….. 59
4.4 Базы знаний …………………………………………… ………… 62
4.5 Продукционная модель знаний …………… ………………… 62
4.6 Фреймы ………………………………………………… ……….. 64
4.7 Семантические сети для представления знаний …………….. 66
4.8 Сравнение моделей данных ………………..……………….. 67
4.9 Тезаурусы экономической информации ………….…………. 67
Вопросы для самоконтроля к главе 4 ……….………… ……………… 70
Терминологический словарь ……………………………………………. 72
Литература ……………..………………………………....……….. 77
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 1966; Нарушение авторских прав?; Мы поможем в написании вашей работы!