КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лексический анализ. Вначале составим программу на языке Си, которая предназначена только лишь (!) для распознавания лексем в тексте программы на языке SPL
|
|
|
|
Вначале составим программу на языке Си, которая предназначена только лишь (!) для распознавания лексем в тексте программы на языке SPL, а также для размещения идентификаторов в специальной таблице TNM. Эта таблица представляет собой глобальный одномерный массив
char TNM [400];
В процессе лексического анализа распознаются лексемы:
1) служебные слова;
2) знаки операций и разделители;
3) целые числа;
4) идентификаторы;
5) признак конца файла.
В программе каждой лексеме ставится в соответствие целое число. Знаки операций и разделители закодированы литеральными константами ‘ + ’, ‘ - ‘, ‘ * ’, ‘ / ’, ‘ % ’, ‘ = ’, ‘ ( ‘, ‘ ) ’, ‘, ’, ‘; ’.
Каждой из них соответствует целое число из таблицы кодов ASCII (М. Уэйт, С. Прата, Д. Мартин Язык Си.- М: “Мир”,1988.- С.512).
В таблице кодов ASCII также закодированы целыми числами символы букв и цифр. Обычно в этой таблице приводятся коды 256 символов.
Для служебных слов имена лексем выбирает программист. Предлагается эти лексемы обозначать соответствующими заглавными буквами с буквой L в конце. Например, служебным словом if и while имена лексем соответственно IFL, WHILEL и т.д. А связь с целыми числами определяется с помощью перечисляемых констант целого типа.
enum {BEGINL=257, ENDL, READL, PRITL, RETRL, IFL, THENL, WHILEL, DOL, INTL, CONSTL, NUMB, IDEN };
Здесь NUMB – лексема для целого числа;
IDEN – лексема для идентификатора.
Благодаря применению enum {}, лексема BEGINL получила числовое значение 257, ENDL – 258 и т.д. Таким образом, при написании программы нет необходимости помнить, что лексема BEGINL закодирована числом 257, а ENDL – 258. Везде, где нужно сослаться на эти лексемы, удобнее писать BEGINL, ENDL и т.д., а вместо них будут подставляться числа 257, 258 и т.д.
Кроме перечисленных лексем также используются признак конца файла EOF. В файле stdio.h есть директива препроцессора #define EOF – 1. Из нее видно, что EOF закодирован – 1.
Текст программы на Си для лексического анализа программы на SPL приведен в виде файла part1.c.
Целесообразно привести некоторые пояснения к этой программе. В ней используются глобальные переменные и приведенные выше в enum {} перечисленные константы.
int lex; //распознанная лексема (целое число)
int lval; // значение лексемы. Для константы это числовое значение, а для идентификатора – адрес в таблице идентификаторов TNM
int nst=0; // номер считываемой строки в программе на языке SPL
char nch=’\n’; // считываемый символ из программы на SPL
char TNM [400]; // таблица идентификаторов
char * ptn=TNM; // указатель на первый свободный элемент в таблице
идентификаторов. В самом начале он стоит на
TNM [0], т.к. имя массива TNM в языке Си
является адресом его самого первого (т.е. нулевого)
элемента.
FILE * PF; // указатель на файл с текстом программы на языке SPL
FILE * padres // указатель на файл, в который будут заносится
адреса идентификаторов в таблице TNM.
В программе part1.c при вызове функции main () используются параметры. Заголовок функции main () имеет вид:
void main (int av, char * av [ ])
Здесь ac – количество параметров (символьных строк);
char* av [ ] – массив указателей. В этот массив заносятся строки символов.
Конкретно, в av [0] автоматически заносятся имя файла с готовой для исполнения программой (например, part1.exe).
В av [1] следует самостоятельно занести имя файла с текстом программы на языке SPL. Например, var2.s
Для этого необходимо, находясь в среде Borland C++, вызвать в верхнем меню Run/arguments и нажать клавишу “Enter”. Появится диалоговое окно, в которое следует ввести требуемое имя файла. В данном примере это var2.s. После этого вновь нажать “Enter”. Предполагается, что var2.s находится в текущей директории. Если нужно обеспечить обращение к этому файлу при запуске Borland C++ из другой директории, то следует привести полный путь и ввести, например, C:\\USER\\SPL\\var2.s part1.s ¿
Для лучшего понимания работы лексического анализатора part1.c, предлагается рассмотреть блок-схемы отдельных его функций.
Блок-схема функции
void main (int ac, char * av [ ])
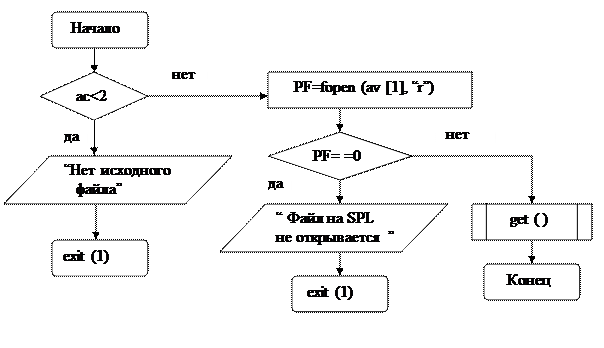 |

Вначале проверяется количество параметров ac. Должно быть не меньше двух строк символов, например, part1.exe в av [0] и var2.s в av [1]. Если параметров меньше двух, происходит остановка работы программы. Иначе открывается файл для чтения с текстом на SPL. В примере это var2.s, и его имя находится в av [1]. Если файл открылся, то происходит вызов функции get (), которая является “поставщиком” лексем.

|
|
|

|
|














|
|











|
|
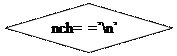


|
{ lex=EOF;
return;
}
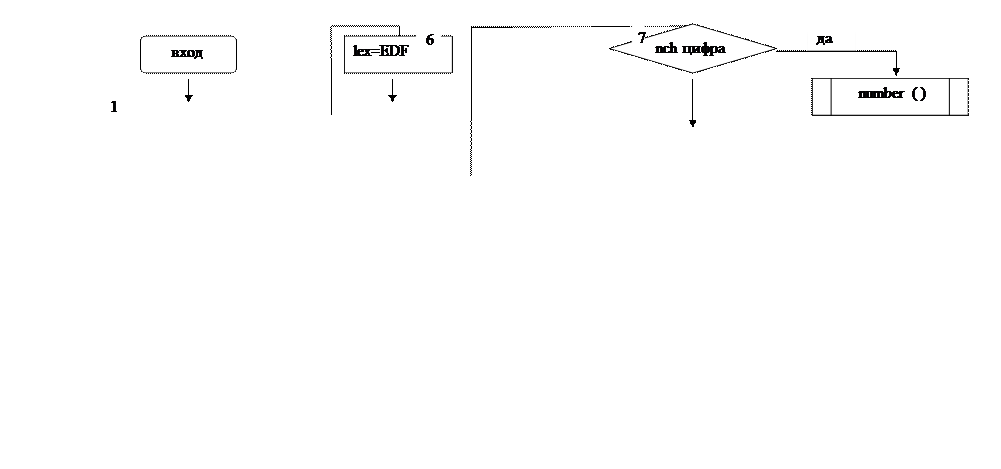
Однако программа part1.c предназначена только лишь для того, чтобы прочитать текст программы на SPL, распознать лексемы, а идентификаторы занести в специальную таблицу идентификаторов char TNM [400]. Поэтому в данной программе в функции get () блок №1 являет собой цикл while (nch!=EOF). Он позволяет прочитать весь текст программы на SPL до конца файла. Далее идет цикл while(isspace(nch)), позволяющий пропускать символы пробела, табуляции, перехода на новую строку и на новую страницу.
Если символ nch, прочитанный из файла с помощью функции get (), не является одним из перечисленных выше, то происходит его распознавание с вызовом функции number() или word().
Если nch является одним из перечисленных специальных символов, например, ‘(’, ‘)’, ‘+’ и т.д., то лексема получает соответствующее значение, считывается новый символ и происходит возврат в цикл (блок №1). В противном случае выдается сообщение о недопустимом символе и происходит выход из программы.
Блок-схема функции void number ()
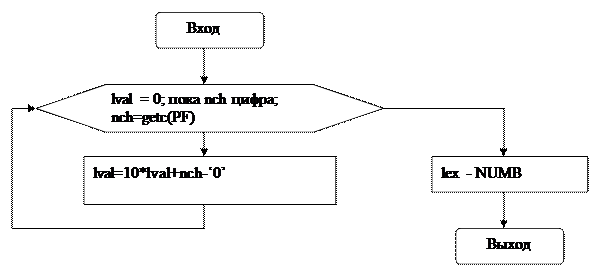
Блок №1 представляет собой цикл for (). В нем значение лексемы lval вначале обнуляется. Затем проверяется, что nch - цифра. Если это так, то происходит вычисление нового значения lval в блоке №2, старое значение lval умножается на 10, к нему прибавляем результат вычитания из кода прочитанной цифры (nch) кода нуля. В таблице кодов ASCII код нуля в “10” системе равен 48, код “1” – 49, код “2” – 50 и т.д. Соответственно в “16”-ричной системе – (30)16, (31)16, (32)16 и т.д.
Таким образом, разница кодов позволяет получить прочитанную цифру.
Предположим, из программы на SPL считывается константа 541.
По первой цифре “5” будет вызвана функция number (). lval=0. nch содержит код цифры “5”, т.е. (35)16. Естественно, что при проверке условия, является ли содержимое nch кодом цифры, ответ будет положительным. В результате происходит переход к блоку №2. В нем вычисляется lval=10*0+(35)16 – (30)16 =5. После этого происходит возврат в цикл и считывается из файла новое значение nch. Это код (34)16 цифры “4”.
Теперь в блоке №2 lval=10*5+(34)16 – (30)16 =54.
После считывания кода цифры “1” lval=10*54+(31)16 – (30)16=541.
После того, как очередной прочитанный символ окажется не цифрой, происходит выход из цикла. Лексема получает значение NUMB, и происходит выход из функции.
Блок-схема функции void word ()
 П
П 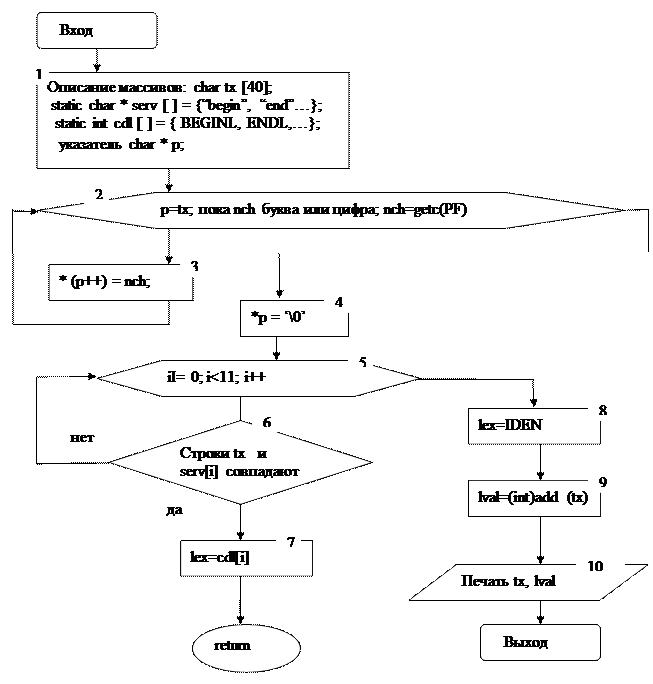
Блок №2 реализуется в виде цикла for. В указатель p заносится адрес tx[0]. Затем проверяется условие, что nch буква или цифра. Если это так, то реализуется блок №3. по адресу в указателе p, т.е. в tx[0] заносится символ nch. После этого значение p увеличивается на 1, то есть в р находится адрес tx [1]. Происходит возвращение в цикл. Считывается новое значение nch. Если это буква или цифра, вновь выполняется блок №2. Теперь уже символ nch заносится в tx [1], после чего в р становится адрес tx [2] и т.д. Если прочитанный символ nch не буква и не цифра, происходит выход из цикла. В очередной элемент массива tx заносится ‘\0’ – признак конца строки символов. В tx сформирована некая последовательность букв или букв и цифр. Теперь предстоит проверить, что она собой являет. Это может быть одно из служебных (зарезервированных) слов, перечисленных в массиве char*serv []
Проверка выполняется в цикле (блоки №5 и №6). В случае совпадения строки символов tx и одного из служебных слов переменная lex получает значение соответствующего элемента из массива int cdl [ ].
Например, если в tx находится строка символов end, то она совпадает с элементом “end” из serv[1]. В результате лексема lex=ENDL, т.е. lex=258 (см. enum={BEGINL=257, ENDL…};).
Если содержимое не совпало ни с одним служебным словом, значит это идентификатор переменной или функции. В этом случае lex=IDEN, т.е. 269, и его необходимо занести в таблицу идентификаторов char TNM [400]. Для этого вызывается функция add (tx). Она возвращает указатель char*. Поэтому, чтобы присвоить возвращаемый адрес переменной целого типа int lval, применяется явное преобразование типа lval=(int) add (tx).
Блок-схема функции char*add(char*nm)
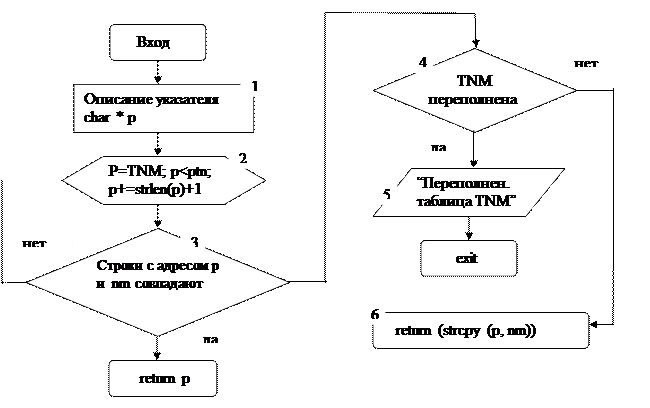
При вызове функции add (char*nm) вместо формального параметра nm передается фактический параметр tx (последовательность символов - идентификатор). В блоках №2 и №3 в цикле осуществляется проверка, не было ли ранее занесено в TNM этот идентификатор. Для этого используется указатель char*p. В блоке №2 вначале в p заносится TNM, т.е. адрес TNM [0]. Затем проверяется условие p<ptn. Следует вспомнить, что char*ptn был описан выше в качестве глобального указателя на первый свободный элемент в таблице идентификаторов TNM. Если p<ptn, то выполняется сравнение строк, прочитанных из TNM по адресу в р и переданных в функцию add (). В случае совпадения происходит возвращение адреса, где этот идентификатор был ранее записан. При несовпадении происходит изменение адреса на длину строки только что сравниваемого из TNM идентификатора плюс один символ на ‘\0’.
p+=strlen (p) +1.
После этого вновь проверяется условие p<ptn и т.д.
Если условие p<ptn не выполнилось, это означает, что проверены все ранее записанные в TNM идентификаторы. Тогда нужно изменить значение указателя ptn на количество символов заносимого в таблицу идентификатора плюс один.
ptn+=strlen(nm)+1.
Кроме того, нужно проверить, не выйдет ли новое значение ptn за пределы таблицы TNM. Все это оформлено в виде оператора
if ((ptn+=strlen(nm)+1)>TNM+400)
{
puts(“Переполнение таблицы TNM”);
exit (1);
}
return (strcpy(p, nm));
Если переполнения нет, то вызывается функция копирования строк strcpy(), которая строку nm скопирует в р, и адрес вернет в функцию word().
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 967; Нарушение авторских прав?; Мы поможем в написании вашей работы!